Cómo usar Slither para encontrar errores en contratos inteligentes
Cómo usar Slither
El objetivo de este tutorial es mostrar cómo usar Slither para encontrar errores de manera automática en los contratos inteligentes.
- Instalación
- Uso de la línea de comandos
- Introducción al análisis estático: breve introducción al análisis estático
- API: descripción de la API de Python
Instalación
Slither requiere Python >= 3.6. Se puede instalar a través de pip o usando Docker.
Slither a través de pip:
pip3 install --user slither-analyzerSlither a través de docker:
docker pull trailofbits/eth-security-toolboxdocker run -it -v "$PWD":/home/trufflecon trailofbits/eth-security-toolboxEl comando anterior ejecuta eth-security-toolbox en un Docker que tiene acceso a su directorio actual. Puede cambiar los archivos desde su host y ejecutar las herramientas en los archivos desde el Docker
Dentro de Docker, ejecute:
solc-select 0.5.11cd /home/trufflecon/Ejecutar un script
Para ejecutar un script de Python con Python 3:
python3 script.pyLínea de comandos
Línea de comandos frente a scripts definidos por el usuario. Slither viene con un conjunto de detectores predefinidos que encuentran muchos errores comunes. Al llamar a Slither desde la línea de comandos, se ejecutarán todos los detectores sin necesidad de tener conocimientos detallados de análisis estático:
slither project_pathsAdemás de los detectores, Slither tiene capacidades de revisión de código a través de sus impresores (opens in a new tab) y herramientas (opens in a new tab).
Utilice crytic.io (opens in a new tab) para obtener acceso a detectores privados y a la integración con GitHub.
Análisis estático
Las capacidades y el diseño del marco de análisis estático de Slither se han descrito en publicaciones de blog (1 (opens in a new tab), 2 (opens in a new tab)) y en un artículo académico (opens in a new tab).
El análisis estático existe en distintas formas. Lo más probable es que se dé cuenta de que los compiladores como clang (opens in a new tab) y gcc (opens in a new tab) dependen de estas técnicas de investigación, pero también sustentan (Infer (opens in a new tab), CodeClimate (opens in a new tab), FindBugs (opens in a new tab) y herramientas basadas en métodos formales como Frama-C (opens in a new tab) y Polyspace (opens in a new tab).
No vamos a revisar aquí exhaustivamente las técnicas de análisis estático y de investigación. En cambio, nos centraremos en lo necesario para entender cómo funciona Slither y así poder utilizarlo de forma más eficaz para encontrar errores y entender el código.
Representación del código
A diferencia del análisis dinámico, que se basa en una única ruta de ejecución, el análisis estático se basa en todas las rutas a la vez. Para ello, se basa en una representación de código diferente. Los dos más comunes son el árbol de sintaxis abstracta (AST) y el grafo de flujo de control (CFG).
Árboles de sintaxis abstracta (AST)
Los AST se utilizan cada vez que el compilador analiza el código. Es probablemente la estructura más básica sobre la que se puede realizar un análisis estático.
En pocas palabras, un AST es un árbol estructurado en el que, normalmente, cada hoja contiene una variable o una constante, y los nodos internos son operadores u operaciones de flujo de control. Considere el siguiente código:
1function safeAdd(uint a, uint b) pure internal returns(uint){2 if(a + b <= a){3 revert();4 }5 return a + b;6}El AST correspondiente se muestra en:
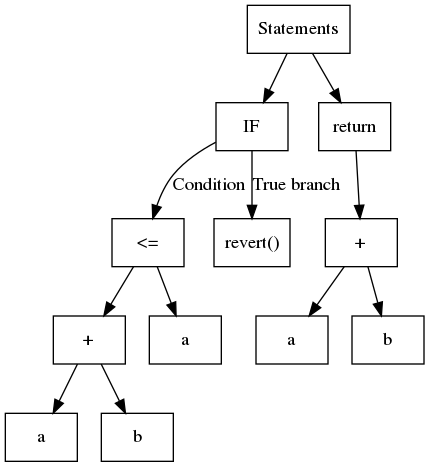
Slither utiliza el AST exportado por solc.
Si bien es sencillo de construir, el AST es una estructura anidada. A veces, esto no es lo más sencillo de analizar. Por ejemplo, para identificar las operaciones utilizadas en la expresión a + b <= a, primero debe analizar <= y luego +. Un enfoque común es utilizar el llamado patrón de visitantes, que navega por el árbol recursivamente. Slither contiene un visitante genérico en ExpressionVisitor (opens in a new tab).
El siguiente código utiliza ExpressionVisitor para detectar si la expresión contiene una adición:
1from slither.visitors.expression.expression import ExpressionVisitor2from slither.core.expressions.binary_operation import BinaryOperationType34class HasAddition(ExpressionVisitor):56 def result(self):7 return self._result89 def _post_binary_operation(self, expression):10 if expression.type == BinaryOperationType.ADDITION:11 self._result = True1213visitor = HasAddition(expression) # la expresión es la expresión que se va a probar14print(f'La expresión {expression} tiene una adición: {visitor.result()}')Mostrar todoGrafo de flujo de control (CFG)
La segunda representación de código más común es el grafo de flujo de control (CFG). Como su nombre indica, es una representación basada en grafos que expone todas las rutas de ejecución. Cada nodo contiene una o varias instrucciones. Las aristas del grafo representan las operaciones de flujo de control (if/then/else, bucle, etc.). El CFG de nuestro ejemplo anterior es:
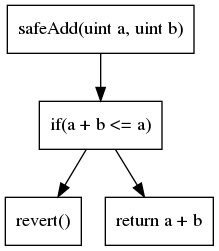
El CFG es la representación sobre la que se construye la mayoría de los análisis.
Existen muchas otras representaciones de código. Cada representación tiene ventajas y desventajas según el análisis que se quiera realizar.
Análisis
El tipo de análisis más sencillo que puede realizar con Slither son los análisis sintácticos.
Análisis de sintaxis
Slither puede navegar por los diferentes componentes del código y su representación para encontrar inconsistencias y defectos usando un enfoque del tipo coincidencia de patrones.
Por ejemplo, los siguientes detectores buscan problemas relacionados con la sintaxis:
-
Sombreado de variables de estado (opens in a new tab): itera sobre todas las variables de estado y comprueba si alguna sombrea una variable de un contrato heredado (state.py#L51-L62 (opens in a new tab))
-
Interfaz ERC20 incorrecta (opens in a new tab): busca firmas de función ERC20 incorrectas (incorrect_erc20_interface.py#L34-L55 (opens in a new tab))
Análisis semántico
En contraste con el análisis de sintaxis, un análisis semántico profundizará y analizará el “significado” del código. Esta familia incluye algunos amplios tipos de análisis. Conducen a resultados más potentes y útiles, pero también son más complejos de escribir.
Los análisis semánticos se usan para las detecciones de vulnerabilidad más avanzadas.
Análisis de dependencia de datos
Se dice que una variable variable_a tiene una dependencia de datos de variable_b si hay una ruta para la cual el valor de variable_a está influenciado por variable_b.
En el siguiente código, variable_a depende de variable_b:
1// ...2variable_a = variable_b + 1;Slither viene con capacidades integradas de dependencia de datos (opens in a new tab), gracias a su representación intermedia (que se tratará en una sección posterior).
Se puede encontrar un ejemplo del uso de la dependencia de datos en el detector de igualdad estricta peligrosa (opens in a new tab). Aquí Slither buscará una comparación de igualdad estricta con un valor peligroso (incorrect_strict_equality.py#L86-L87 (opens in a new tab)), e informará al usuario de que debe usar >= o <= en lugar de ==, para evitar que un atacante atrape el contrato. Entre otros, el detector considerará peligroso el valor de retorno de una llamada a balanceOf(address) (incorrect_strict_equality.py#L63-L64 (opens in a new tab)), y utilizará el motor de dependencia de datos para rastrear su uso.
Cálculo de punto fijo
Si su análisis navega a través del CFG y sigue las aristas, es probable que vea nodos ya visitados. Por ejemplo, si un bucle se presenta como se muestra a continuación:
1for(uint i; i < range; ++){2 variable_a += 13}Su análisis necesitará saber cuándo detenerse. Hay dos estrategias principales aquí: (1) iterar en cada nodo un número finito de veces, (2) calcular el llamado punto fijo. Un punto fijo, o fixpoint, básicamente significa que el análisis de este nodo no proporciona ninguna información significativa.
Un ejemplo de punto fijo usado se puede encontrar en los detectores de reentrada: Slither explora los nodos, y busca llamadas externas, escritura y lectura al almacenamiento. Una vez que ha alcanzado un punto fijo (reentrancy.py#L125-L131 (opens in a new tab)), detiene la exploración y analiza los resultados para ver si hay una reentrada, a través de diferentes patrones de reentrada (reentrancy_benign.py (opens in a new tab), reentrancy_read_before_write.py (opens in a new tab), reentrancy_eth.py (opens in a new tab)).
Escribir análisis utilizando un cálculo de punto fijo eficiente requiere una buena comprensión de cómo el análisis propaga su información.
Representación intermedia
Una representación intermedia (IR) es un lenguaje que pretende ser más susceptible al análisis estático que el original. Slither traduce Solidity a su propia IR: SlithIR (opens in a new tab).
Entender SlithIR no es necesario si solo desea escribir comprobaciones básicas. Sin embargo, será útil si tiene pensado escribir análisis semánticos avanzados. Los impresores SlithIR (opens in a new tab) y SSA (opens in a new tab) le ayudarán a entender cómo se traduce el código.
Conceptos básicos de la API
Slither tiene una API que le permite explorar los atributos básicos del contrato y sus funciones.
Para cargar una base de código:
1from slither import Slither2slither = Slither('/path/to/project')3Exploración de contratos y funciones
Un objeto Slither tiene:
contracts (list(Contract)): lista de contratoscontracts_derived (list(Contract)): lista de contratos que no son heredados por otro contrato (subconjunto de contratos)get_contract_from_name (str): Devuelve un contrato a partir de su nombre
Un objeto Contract tiene:
name (str): nombre del contratofunctions (list(Function)): lista de funcionesmodifiers (list(Modifier)): lista de modificadoresall_functions_called (list(Function/Modifier)): lista de todas las funciones internas accesibles para el contratoinheritance (list(Contract)): lista de los contratos heredadosget_function_from_signature (str): Devuelve una Función a partir de su firmaget_modifier_from_signature (str): Devuelve un Modificador a partir de su firmaget_state_variable_from_name (str): Devuelve una StateVariable a partir de su nombre
Un objeto Function o Modifier tiene:
name (str): nombre de la funcióncontract (contract): el contrato donde se declara la funciónnodes (list(Node)): lista de los nodos que componen el CFG de la función/modificadorentry_point (Node): punto de entrada del CFGvariables_read (list(Variable)): lista de variables leídasvariables_written (list(Variable)): lista de variables escritasstate_variables_read (list(StateVariable)): lista de variables de estado leídas (subconjunto devariables_read)state_variables_written (list(StateVariable)): lista de variables de estado escritas (subconjunto devariables_written)
Última actualización de la página: 3 de febrero de 2025


