PeerDAS
El protocolo de Ethereum está experimentando su actualización de escalado más significativa desde la introducción de las transacciones de blobs con la EIP-4844. Como parte de la actualización Fusaka, PeerDAS introduce una nueva forma de gestionar los datos de los blobs, lo que supone un aumento aproximado de un orden de magnitud en la capacidad de disponibilidad de datos (DA) para las L2.
Más información sobre la hoja de ruta de escalado de blobs (opens in a new tab)
Escalabilidad
La visión de Ethereum es ser una plataforma neutral, segura y descentralizada disponible para todo el mundo. A medida que crece el uso de la red, esto requiere equilibrar el trilema de la escala, la seguridad y la descentralización de la red. Si Ethereum simplemente aumentara los datos gestionados por la red dentro de su diseño actual, correría el riesgo de sobrecargar los nodos en los que Ethereum se basa para su descentralización. La escalabilidad requiere un diseño de mecanismos riguroso que minimice las concesiones.
Una de las estrategias para lograr este objetivo es permitir un ecosistema diverso de soluciones de escalado de capa 2 en lugar de procesar todas las transacciones en la red principal de la . Las o los rollups procesan transacciones en sus propias cadenas separadas y utilizan Ethereum para la verificación y la seguridad. Publicar únicamente compromisos críticos para la seguridad y comprimir las cargas útiles permite a las L2 utilizar la capacidad de DA de Ethereum de forma más eficiente. A su vez, la L1 transporta menos datos sin comprometer las garantías de seguridad, mientras que las L2 incorporan a más usuarios con costes de gas más bajos. Inicialmente, las L2 publicaban datos como calldata en transacciones ordinarias, que competían con las transacciones de la L1 por el gas y no eran prácticas para la disponibilidad masiva de datos.
Proto-Danksharding
El primer gran paso hacia el escalado de la L2 fue la actualización Dencun, que introdujo el Proto-Danksharding (EIP-4844). Esta actualización creó un nuevo tipo de datos especializado para los rollups, llamado «blobs». Los blobs, u objetos binarios grandes, son piezas efímeras de datos arbitrarios que no necesitan ejecución de la EVM y que los nodos almacenan solo durante un tiempo limitado. Este procesamiento más eficiente permitió que las L2 publicaran más datos en Ethereum y se escalaran aún más.
A pesar de tener ya grandes beneficios para el escalado, el uso de blobs es solo una parte del objetivo final. En el protocolo actual, cada nodo de la red necesita todavía descargar cada blob. El cuello de botella se convierte en el ancho de banda requerido por los nodos individuales, con la cantidad de datos que deben descargarse aumentando directamente con un mayor número de blobs.
Ethereum no compromete la descentralización, y el ancho de banda es uno de los botones más sensibles. Incluso con la computación potente ampliamente disponible para cualquiera que pueda permitírselo, las limitaciones del ancho de banda de subida (opens in a new tab) incluso en ciudades muy urbanizadas de países desarrollados (como Alemania (opens in a new tab), Bélgica (opens in a new tab), Australia (opens in a new tab) o los Estados Unidos (opens in a new tab)) podrían restringir los nodos a solo poder funcionar desde centros de datos si los requisitos de ancho de banda no se ajustan cuidadosamente.
Los operadores de nodos tienen requisitos de ancho de banda y espacio en disco cada vez mayores a medida que aumentan los blobs. El tamaño y la cantidad de blobs están limitados por estas restricciones. Cada blob puede transportar hasta 128 kb de datos con una media de 6 blobs por bloque. Este fue solo el primer paso hacia un diseño futuro que utilice los blobs de una manera aún más eficiente.
Muestreo de disponibilidad de datos
La disponibilidad de datos es la garantía de que todos los datos necesarios para validar la cadena de forma independiente son accesibles para todos los participantes de la red. Garantiza que los datos se han publicado en su totalidad y que pueden utilizarse para verificar sin confianza el nuevo estado de la cadena o las transacciones entrantes.
Los blobs de Ethereum proporcionan una sólida garantía de disponibilidad de datos que garantiza la seguridad de las L2. Para ello, los nodos de Ethereum necesitan descargar y almacenar los blobs en su totalidad. ¿Pero qué pasaría si pudiéramos distribuir los blobs en la red de forma más eficiente y evitar esta limitación?
Un enfoque diferente para almacenar los datos y garantizar su disponibilidad es el muestreo de disponibilidad de datos (DAS). En lugar de que cada ordenador que ejecuta Ethereum almacene por completo cada blob, DAS introduce una división descentralizada del trabajo. Rompe la carga de procesar los datos distribuyendo tareas más pequeñas y manejables por toda la red de nodos. Los blobs se dividen en trozos y cada nodo solo descarga unos pocos trozos utilizando un mecanismo de distribución aleatoria uniforme entre todos los nodos.
Esto introduce un nuevo problema: demostrar la disponibilidad e integridad de los datos. ¿Cómo puede la red garantizar que los datos están disponibles y que son todos correctos cuando los nodos individuales solo contienen pequeños trozos? ¡Un nodo malicioso podría servir datos falsos y romper fácilmente las fuertes garantías de disponibilidad de datos! Aquí es donde la criptografía viene al rescate.
Para garantizar la integridad de los datos, la EIP-4844 ya se implementó con compromisos KZG. Son pruebas criptográficas que se crean cuando se añade un nuevo blob a la red. En cada bloque se incluye una pequeña prueba, y los nodos pueden verificar que los blobs recibidos se corresponden con el compromiso KZG del bloque.
DAS es un mecanismo que se basa en esto y garantiza que los datos sean correctos y estén disponibles. El muestreo es un proceso en el que un nodo consulta solo una pequeña parte de los datos y la verifica con el compromiso. KZG es un esquema de compromiso polinómico, lo que significa que se puede verificar cualquier punto de la curva polinómica. Al comprobar solo un par de puntos en el polinomio, el cliente que realiza el muestreo puede tener una fuerte garantía probabilística de que los datos están disponibles.
PeerDAS
PeerDAS (EIP-7594) (opens in a new tab) es una propuesta específica que implementa el mecanismo DAS en Ethereum, marcando probablemente la mayor actualización desde La Fusión. PeerDAS está diseñado para extender los datos de los blobs, dividiéndolos en columnas y distribuyendo un subconjunto a los nodos.
Ethereum toma prestadas algunas matemáticas inteligentes para lograr esto: aplica una codificación de borrado al estilo de Reed-Solomon a los datos de los blobs. Los datos de los blobs se representan como un polinomio cuyos coeficientes codifican los datos, y a continuación se evalúa ese polinomio en puntos adicionales para crear un blob extendido, duplicando el número de evaluaciones. Esta redundancia añadida permite la recuperación por borrado: aunque falten algunas evaluaciones, el blob original puede reconstruirse siempre que se disponga de al menos la mitad del total de los datos, incluidas las piezas extendidas.
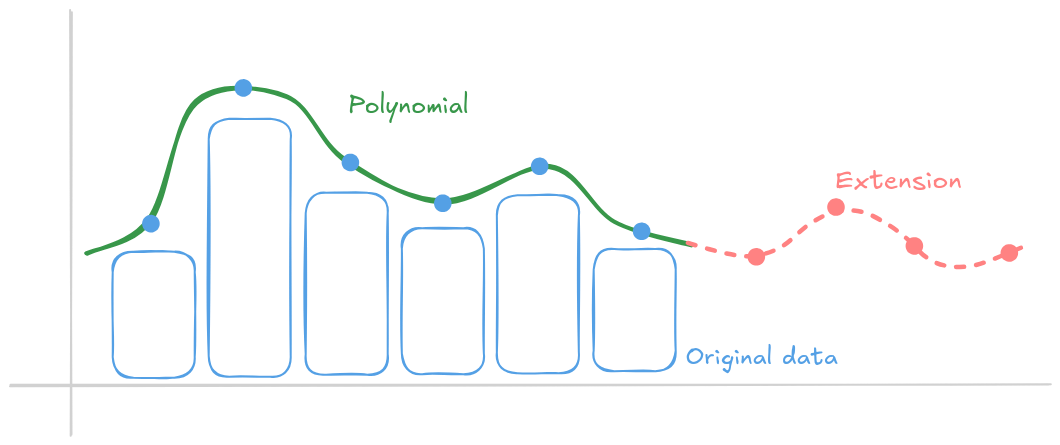
En realidad, este polinomio tiene miles de coeficientes. Los compromisos KZG son valores de unos pocos bytes, algo así como un hash, conocido por todos los nodos. Cada nodo que contenga suficientes puntos de datos puede reconstruir eficientemente un conjunto completo de datos de blob (opens in a new tab).
Dato curioso: la misma técnica de codificación se utilizaba en los DVD. Si se rayaba un DVD, el reproductor seguía pudiendo leerlo gracias a la codificación Reed-Solomon que añade las piezas que faltan del polinomio.
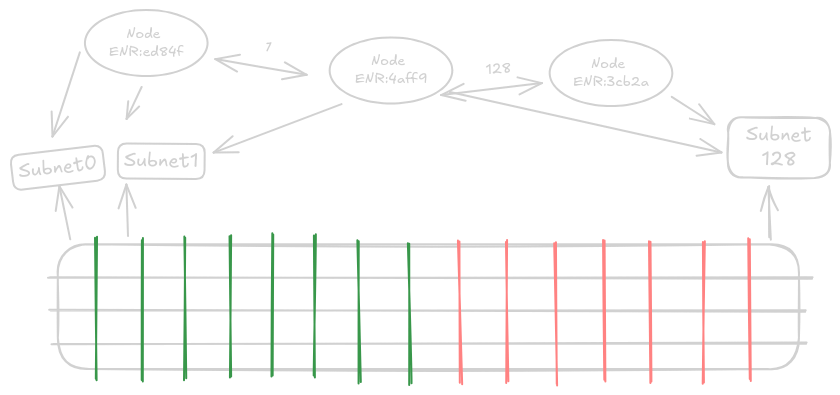
Históricamente, los datos en las blockchains, ya fueran bloques o blobs, se transmitían a todos los nodos. Con el enfoque de dividir y muestrear de PeerDAS, ya no es necesario transmitir todo a todos. Después de Fusaka, la red de la capa de consenso se organiza en temas/subredes de gossip: las columnas de blobs se asignan a subredes específicas, y cada nodo se suscribe a un subconjunto predeterminado y custodia solo esas piezas.
Con PeerDAS, los datos de los blobs extendidos se dividen en 128 piezas llamadas columnas. Los datos se distribuyen a estos nodos a través de un protocolo de gossip dedicado en subredes específicas a las que se suscriben. Cada nodo regular de la red participa en al menos 8 subredes de columna elegidas al azar. Recibir datos de solo 8 de las 128 subredes significa que este nodo predeterminado recibe solo 1/16 de todos los datos, pero como los datos se extendieron, esto es 1/8 de los datos originales.
Esto permite un nuevo límite teórico de escalado de 8x el esquema actual de «todos descargan todo». Con los nodos suscribiéndose a diferentes subredes aleatorias que sirven columnas de blobs, la probabilidad es muy alta de que se distribuyan uniformemente y, por lo tanto, cada pieza de datos exista en algún lugar de la red. Los nodos que ejecutan validadores están obligados a suscribirse a más subredes con cada validador que ejecutan.
Cada nodo tiene un identificador único generado aleatoriamente, que normalmente sirve como su identidad pública para las conexiones. En PeerDAS, este número se utiliza para determinar el conjunto aleatorio de subredes a las que tiene que suscribirse, lo que da como resultado una distribución aleatoria uniforme de todos los datos de los blobs.
Una vez que un nodo reconstruye con éxito los datos originales, redistribuye las columnas recuperadas de nuevo a la red, reparando activamente cualquier brecha de datos y mejorando la resiliencia general del sistema. Los nodos conectados a validadores con un saldo combinado ≥4096 ETH deben ser un supernodo y, por lo tanto, deben suscribirse a todas las subredes de columna de datos y custodiar todas las columnas. Estos supernodos repararán continuamente las brechas de datos. La naturaleza probabilísticamente autorreparable del protocolo permite fuertes garantías de disponibilidad sin limitar a los operadores domésticos que solo poseen porciones de los datos.
La disponibilidad de los datos puede ser confirmada por cualquier nodo que posea solo un pequeño subconjunto de los datos del blob gracias al mecanismo de muestreo descrito anteriormente. Esta disponibilidad se hace cumplir: los validadores deben seguir nuevas reglas de elección de bifurcación, lo que significa que solo aceptarán y votarán por bloques después de haber verificado la disponibilidad de los datos.
El impacto directo en los usuarios (especialmente en los usuarios de la L2) son unas comisiones más bajas. Con 8 veces más espacio para los datos de los rollups, las operaciones de los usuarios en su cadena se abaratan con el tiempo. Pero la reducción de las comisiones después de Fusaka llevará tiempo y dependerá de los BPO.
Solo de parámetros de blobs (BPO)
La red podrá procesar teóricamente 8 veces más blobs, pero los aumentos de blobs son un cambio que debe ser probado adecuadamente y ejecutado de forma segura y gradual. Las redes de prueba proporcionan la confianza suficiente para desplegar las características en la red principal, pero necesitamos garantizar la estabilidad de la red p2p antes de permitir un número significativamente mayor de blobs.
Para aumentar gradualmente el número objetivo de blobs por bloque sin sobrecargar la red, Fusaka introduce bifurcaciones de solo de parámetros de blobs (BPO) (opens in a new tab). A diferencia de las bifurcaciones regulares que necesitan una amplia coordinación del ecosistema, acuerdo y actualizaciones de software, los BPO (EIP-7892) (opens in a new tab) son actualizaciones preprogramadas que aumentan el número máximo de blobs con el tiempo sin intervención.
Esto significa que inmediatamente después de que se active Fusaka y se ponga en marcha PeerDAS, el número de blobs permanecerá sin cambios. El número de blobs comenzará a duplicarse cada pocas semanas hasta alcanzar un máximo de 48, mientras que los desarrolladores supervisan para asegurarse de que el mecanismo funciona como se espera y no tiene efectos adversos en los nodos que ejecutan la red.
Direcciones futuras
PeerDAS es solo un paso hacia una visión de escalado mayor de FullDAS (opens in a new tab), o Danksharding. Mientras que PeerDAS utiliza la codificación de borrado 1D para cada blob individualmente, el Danksharding completo utilizará un esquema de codificación de borrado 2D más completo en toda la matriz de datos de los blobs. La ampliación de los datos en dos dimensiones crea propiedades de redundancia aún más fuertes y una reconstrucción y verificación más eficientes. La realización de FullDAS requerirá optimizaciones sustanciales de la red y del protocolo, junto con investigación adicional.
Lecturas adicionales
- PeerDAS: Muestreo de disponibilidad de datos de pares por Francesco D'Amato (opens in a new tab)
- Una documentación del PeerDAS de Ethereum (opens in a new tab)
- Demostración de la seguridad de PeerDAS sin el AGM (opens in a new tab)
- Vitalik sobre PeerDAS, su impacto y las pruebas de Fusaka (opens in a new tab)
Última actualización de la página: 23 de febrero de 2026


