이더리움을 이해하고 싶으신가요?
이 백서는 이더리움이 출시되기 전인 2014년에 발행되었습니다. 10년 이상의 개발, 주요 업그레이드 및 생태계 성장을 거친 지금, 원본 백서는 더 이상 오늘날의 이더리움을 반영하지 않습니다.
작성된 지 수년이 지났지만, 아래의 원본 백서는 이더리움과 그 비전을 정확하게 보여주는 유용한 참고 자료로서 계속 활용되고 있으므로 그대로 유지합니다.
차세대 스마트 컨트랙트 및 탈중앙화 애플리케이션 플랫폼
2009년 사토시 나카모토의 비트코인 개발은 뒷받침하는 자산이나 "내재 가치 (새 탭에서 열림)"가 없으면서도 중앙화된 발행자나 통제자가 없는 디지털 자산의 첫 번째 사례로서, 돈과 통화 분야의 급진적인 발전으로 종종 찬사를 받아왔습니다. 그러나 비트코인 실험에서 틀림없이 더 중요하다고 할 수 있는 또 다른 부분은 분산 합의의 도구로서 기반이 되는 블록체인 기술이며, 비트코인의 이러한 다른 측면으로 관심이 빠르게 옮겨가기 시작했습니다. 흔히 언급되는 블록체인 기술의 대안적 애플리케이션에는 사용자 지정 통화 및 금융 상품을 나타내기 위해 블록체인 상의 디지털 자산을 사용하는 것("컬러드 코인 (새 탭에서 열림)"), 기반이 되는 물리적 기기의 소유권("스마트 자산 (새 탭에서 열림)"), 도메인 이름과 같은 대체 불가능한 자산("Namecoin (새 탭에서 열림)")뿐만 아니라, 임의의 규칙을 구현하는 코드 조각에 의해 디지털 자산이 직접 제어되도록 하는 더 복잡한 애플리케이션("스마트 컨트랙트 (새 탭에서 열림)")이나 심지어 블록체인 기반의 "탈중앙화된 자율 조직 (새 탭에서 열림)"(DAO)까지도 포함됩니다. 이더리움이 제공하고자 하는 것은 임의의 상태 전환 함수를 인코딩할 수 있는 '컨트랙트'를 생성하는 데 사용할 수 있는 완전한 튜링 완전(Turing-complete) 프로그래밍 언어가 내장된 블록체인입니다. 이를 통해 사용자는 단 몇 줄의 코드로 로직을 작성하기만 하면 위에서 설명한 모든 시스템뿐만 아니라 아직 상상하지 못한 다른 많은 시스템을 만들 수 있습니다.
비트코인 및 기존 개념 소개
역사
탈중앙화된 디지털 통화의 개념과 자산 등록부 같은 대안적 애플리케이션은 수십 년 전부터 존재해 왔습니다. 1980년대와 1990년대의 익명 전자 화폐 프로토콜은 주로 차우미안 블라인딩(Chaumian blinding)이라는 암호학적 원형에 의존하여 높은 수준의 프라이버시를 갖춘 통화를 제공했지만, 중앙화된 중개자에 의존했기 때문에 큰 호응을 얻지 못했습니다. 1998년, 웨이 다이의 b-money (새 탭에서 열림)는 연산 퍼즐 해결과 탈중앙화된 합의를 통해 화폐를 창출한다는 아이디어를 도입한 최초의 제안이 되었지만, 탈중앙화된 합의를 실제로 어떻게 구현할 수 있는지에 대한 세부 사항은 부족했습니다. 2005년, 할 피니(Hal Finney)는 b-money의 아이디어와 아담 백(Adam Back)의 연산적으로 어려운 해시캐시(Hashcash) 퍼즐을 결합하여 암호화폐의 개념을 만드는 시스템인 "재사용 가능한 작업증명(reusable proofs of work) (새 탭에서 열림)" 개념을 도입했지만, 백엔드로 신뢰할 수 있는 컴퓨팅에 의존함으로써 다시 한번 이상적인 형태에는 미치지 못했습니다. 2009년, 사토시 나카모토(Satoshi Nakamoto)에 의해 처음으로 탈중앙화된 통화가 실제로 구현되었으며, 이는 공개키 암호학을 통해 소유권을 관리하는 확립된 원형과 코인의 소유자를 추적하기 위한 "작업증명(PoW)"이라는 합의 알고리즘을 결합한 것이었습니다.
작업증명(PoW) 이면의 메커니즘은 두 가지 문제를 동시에 해결했기 때문에 이 분야에서 획기적인 발전이었습니다. 첫째, 단순하고 적당히 효과적인 합의 알고리즘을 제공하여 네트워크의 노드들이 비트코인 원장의 상태에 대한 일련의 표준적인 업데이트에 집단적으로 동의할 수 있게 했습니다. 둘째, 합의 프로세스에 자유롭게 참여할 수 있는 메커니즘을 제공하여 누가 합의에 영향을 미칠지 결정하는 정치적 문제를 해결하는 동시에 시빌 공격(sybil attack)을 방지했습니다. 이는 특정 목록에 고유한 엔티티로 등록되어야 하는 것과 같은 형식적인 참여 장벽을 경제적 장벽으로 대체함으로써 이루어집니다. 즉, 합의 투표 과정에서 단일 노드의 가중치는 해당 노드가 제공하는 컴퓨팅 파워에 정비례합니다. 그 이후로 노드의 가중치를 컴퓨팅 리소스가 아닌 보유한 통화량에 비례하여 계산하는 지분 증명(PoS)이라는 대안적 접근 방식이 제안되었습니다. 두 접근 방식의 상대적인 장단점에 대한 논의는 이 백서의 범위를 벗어나지만, 두 접근 방식 모두 암호화폐의 중추 역할을 하는 데 사용될 수 있다는 점에 유의해야 합니다.
상태 전환 시스템으로서의 비트코인

기술적인 관점에서 볼 때, 비트코인과 같은 암호화폐의 원장은 상태 전환 시스템으로 생각할 수 있습니다. 여기에는 기존의 모든 비트코인의 소유권 현황으로 구성된 "상태"와, 상태 및 트랜잭션을 입력받아 그 결과로 새로운 상태를 출력하는 "상태 전환 함수"가 있습니다. 예를 들어 표준 은행 시스템에서 상태는 대차대조표이고, 트랜잭션은 A에서 B로 $X를 이동하라는 요청이며, 상태 전환 함수는 A의 계정에서 $X를 줄이고 B의 계정에서 $X를 늘립니다. 애초에 A의 계정에 $X 미만이 있는 경우 상태 전환 함수는 오류를 반환합니다. 따라서 다음과 같이 공식적으로 정의할 수 있습니다.
APPLY(S,TX) -> S' or ERROR
위에서 정의한 은행 시스템의 경우:
APPLY({ Alice: $50, Bob: $50 },"send $20 from Alice to Bob") = { Alice: $30, Bob: $70 }
하지만:
APPLY({ Alice: $50, Bob: $50 },"send $70 from Alice to Bob") = ERROR
비트코인의 "상태"는 발행되었지만 아직 사용되지 않은 모든 코인(엄밀히 말하면 "미사용 트랜잭션 출력값" 또는 UTXO)의 모음이며, 각 UTXO에는 액면가와 소유자(본질적으로 암호학적 공개키인 20바이트 주소로 정의됨fn1)가 있습니다. 트랜잭션은 하나 이상의 입력값을 포함하며, 각 입력값에는 기존 UTXO에 대한 참조와 소유자의 주소와 연결된 개인 키로 생성된 암호학적 서명이 포함됩니다. 또한 하나 이상의 출력값을 포함하며, 각 출력값에는 상태에 추가될 새로운 UTXO가 포함됩니다.
상태 전환 함수 APPLY(S,TX) -> S'는 대략 다음과 같이 정의할 수 있습니다.
TX의 각 입력값에 대해:- 참조된 UTXO가
S에 없으면 오류를 반환합니다. - 제공된 서명이 UTXO의 소유자와 일치하지 않으면 오류를 반환합니다.
- 참조된 UTXO가
- 모든 입력 UTXO의 액면가 합계가 모든 출력 UTXO의 액면가 합계보다 작으면 오류를 반환합니다.
- 모든 입력 UTXO가 제거되고 모든 출력 UTXO가 추가된
S를 반환합니다.
첫 번째 단계의 전반부는 트랜잭션 발신자가 존재하지 않는 코인을 사용하는 것을 방지하고, 첫 번째 단계의 후반부는 트랜잭션 발신자가 다른 사람의 코인을 사용하는 것을 방지하며, 두 번째 단계는 가치 보존을 강제합니다. 결제에 이를 사용하기 위한 프로토콜은 다음과 같습니다. 앨리스(Alice)가 밥(Bob)에게 11.7 BTC를 보내고 싶어 한다고 가정해 보겠습니다. 먼저, 앨리스는 자신이 소유한 사용 가능한 UTXO 중에서 합계가 최소 11.7 BTC가 되는 세트를 찾습니다. 현실적으로 앨리스는 정확히 11.7 BTC를 맞추지 못할 것입니다. 그녀가 얻을 수 있는 가장 작은 조합이 6+4+2=12라고 가정해 보겠습니다. 그런 다음 그녀는 이 세 개의 입력값과 두 개의 출력값으로 트랜잭션을 생성합니다. 첫 번째 출력값은 밥의 주소를 소유자로 하는 11.7 BTC가 되고, 두 번째 출력값은 남은 0.3 BTC의 "거스름돈"으로 소유자는 앨리스 자신이 됩니다.
채굴

신뢰할 수 있는 중앙화된 서비스에 접근할 수 있다면 이 시스템을 구현하는 것은 아주 간단할 것입니다. 중앙화된 서버의 하드 드라이브를 사용하여 상태를 추적하면서 설명된 대로 정확하게 코딩하기만 하면 됩니다. 하지만 비트코인을 통해 우리는 탈중앙화된 통화 시스템을 구축하려고 하므로, 모든 사람이 트랜잭션 순서에 동의하도록 보장하기 위해 상태 전환 시스템과 합의 시스템을 결합해야 합니다. 비트코인의 탈중앙화된 합의 프로세스는 네트워크의 노드들이 "블록"이라는 트랜잭션 패키지를 지속적으로 생성하려고 시도할 것을 요구합니다. 네트워크는 대략 10분마다 하나의 블록을 생성하도록 설계되었으며, 각 블록에는 타임스탬프, 논스, 이전 블록에 대한 참조(즉, 해시) 및 이전 블록 이후 발생한 모든 트랜잭션 목록이 포함됩니다. 시간이 지남에 따라 이는 비트코인 원장의 최신 상태를 나타내기 위해 지속적으로 업데이트되는 영구적이고 계속 성장하는 "블록체인"을 생성합니다.
이 패러다임에서 블록이 유효한지 확인하는 알고리즘은 다음과 같습니다.
- 블록이 참조하는 이전 블록이 존재하고 유효한지 확인합니다.
- 블록의 타임스탬프가 이전 블록의 타임스탬프보다 크고fn2 미래의 2시간 이내인지 확인합니다.
- 블록의 작업증명(PoW)이 유효한지 확인합니다.
S[0]를 이전 블록 끝의 상태라고 가정합니다.TX가n개의 트랜잭션이 있는 블록의 트랜잭션 목록이라고 가정합니다.0...n-1의 모든i에 대해S[i+1] = APPLY(S[i],TX[i])를 설정합니다. 적용 중 하나라도 오류를 반환하면 종료하고 false를 반환합니다.- true를 반환하고
S[n]를 이 블록 끝의 상태로 등록합니다.
본질적으로 블록의 각 트랜잭션은 트랜잭션이 실행되기 전의 표준 상태에서 새로운 상태로의 유효한 상태 전환을 제공해야 합니다. 상태는 어떤 방식으로든 블록에 인코딩되지 않는다는 점에 유의하세요. 이는 검증 노드가 기억해야 할 순수한 추상화이며, 제네시스 상태에서 시작하여 모든 블록의 모든 트랜잭션을 순차적으로 적용해야만 모든 블록에 대해 (안전하게) 계산할 수 있습니다. 또한 채굴자가 블록에 트랜잭션을 포함하는 순서가 중요하다는 점에 유의하세요. 블록에 B가 A에 의해 생성된 UTXO를 사용하는 두 개의 트랜잭션 A와 B가 있는 경우, A가 B보다 먼저 오면 블록이 유효하지만 그렇지 않으면 유효하지 않습니다.
위 목록에 있는 유효성 조건 중 다른 시스템에서는 볼 수 없는 한 가지는 "작업증명(PoW)"에 대한 요구 사항입니다. 정확한 조건은 256비트 숫자로 취급되는 모든 블록의 이중 SHA-256 해시가 동적으로 조정되는 목표값보다 작아야 한다는 것입니다. 이 글을 쓰는 시점에서 이 목표값은 약 2187입니다. 이것의 목적은 블록 생성을 연산적으로 "어렵게" 만들어 시빌 공격자가 자신에게 유리하게 전체 블록체인을 다시 만드는 것을 방지하는 것입니다. SHA-256은 완전히 예측 불가능한 의사 난수 함수로 설계되었기 때문에 유효한 블록을 생성하는 유일한 방법은 단순히 시행착오를 거쳐 논스를 반복적으로 증가시키고 새로운 해시가 일치하는지 확인하는 것뿐입니다.
현재 목표값인 약 2187에서 네트워크는 유효한 블록을 찾기 전에 평균 약 269번의 시도를 해야 합니다. 일반적으로 목표값은 네트워크의 어떤 노드가 평균적으로 10분마다 새로운 블록을 생성하도록 2016 블록마다 네트워크에 의해 재조정됩니다. 이러한 연산 작업에 대해 채굴자에게 보상하기 위해, 모든 블록의 채굴자는 무에서 자신에게 25 BTC를 지급하는 트랜잭션을 포함할 권리가 있습니다. 또한 트랜잭션의 입력값 총액이 출력값 총액보다 큰 경우, 그 차액 역시 "트랜잭션 수수료"로서 채굴자에게 돌아갑니다. 참고로 이것은 BTC가 발행되는 유일한 메커니즘이기도 합니다. 제네시스 상태에는 코인이 전혀 포함되어 있지 않았습니다.
채굴의 목적을 더 잘 이해하기 위해 악의적인 공격자가 발생했을 때 어떤 일이 일어나는지 살펴보겠습니다. 비트코인의 기반 암호학은 안전한 것으로 알려져 있으므로, 공격자는 비트코인 시스템에서 암호학으로 직접 보호되지 않는 유일한 부분인 트랜잭션 순서를 표적으로 삼을 것입니다. 공격자의 전략은 간단합니다.
- 어떤 상품(가급적이면 빠른 전송이 가능한 디지털 상품)의 대가로 판매자에게 100 BTC를 보냅니다.
- 상품이 전송되기를 기다립니다.
- 동일한 100 BTC를 자신에게 보내는 또 다른 트랜잭션을 생성합니다.
- 자신에게 보낸 트랜잭션이 먼저 발생한 것이라고 네트워크를 설득하려고 시도합니다.
(1) 단계가 진행되면 몇 분 후 어떤 채굴자가 해당 트랜잭션을 블록(예: 270000번 블록)에 포함시킬 것입니다. 약 1시간 후, 해당 블록 뒤에 5개의 블록이 체인에 추가될 것이며, 각 블록은 간접적으로 해당 트랜잭션을 가리키며 이를 "확정(confirm)"합니다. 이 시점에서 판매자는 결제가 완결된 것으로 수락하고 상품을 전송합니다. 디지털 상품이라고 가정하고 있으므로 전송은 즉시 이루어집니다. 이제 공격자는 100 BTC를 자신에게 보내는 또 다른 트랜잭션을 생성합니다. 공격자가 단순히 이를 실제 네트워크에 배포하면 트랜잭션은 처리되지 않습니다. 채굴자들은 APPLY(S,TX)를 실행하려고 시도할 것이고 TX가 더 이상 상태에 존재하지 않는 UTXO를 소비한다는 것을 알아차릴 것입니다. 따라서 대신 공격자는 블록체인의 "포크"를 생성합니다. 동일한 269999번 블록을 부모로 가리키지만 이전 트랜잭션 대신 새로운 트랜잭션이 포함된 다른 버전의 270000번 블록을 채굴하는 것으로 시작합니다. 블록 데이터가 다르기 때문에 작업증명(PoW)을 다시 수행해야 합니다. 게다가 공격자의 새로운 버전의 270000번 블록은 해시가 다르기 때문에 원래의 270001번부터 270005번 블록은 이를 "가리키지" 않습니다. 따라서 원래 체인과 공격자의 새로운 체인은 완전히 분리됩니다. 포크에서는 가장 긴 블록체인을 진실로 간주한다는 규칙이 있으므로, 정당한 채굴자들은 270005 체인에서 작업하는 반면 공격자 혼자 270000 체인에서 작업하게 됩니다. 공격자가 자신의 블록체인을 가장 길게 만들려면 따라잡기 위해 네트워크의 나머지 전체를 합친 것보다 더 많은 컴퓨팅 파워를 가져야 합니다(따라서 "51% 공격"이라고 합니다).
머클 트리
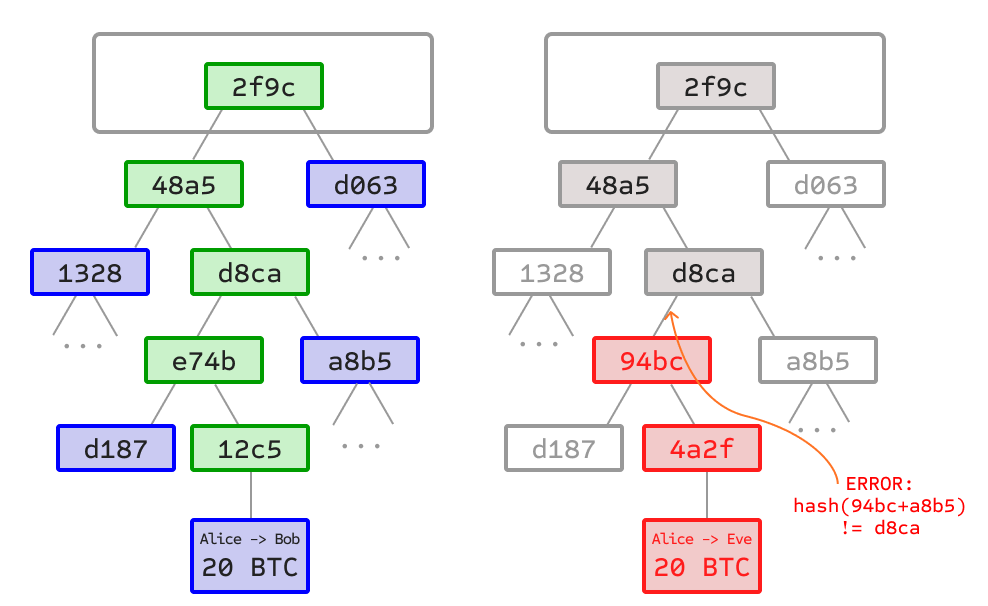
왼쪽: 브랜치의 유효성을 증명하기 위해 머클 트리의 적은 수의 노드만 제시해도 충분합니다.
오른쪽: 머클 트리의 어떤 부분을 변경하려는 시도는 결국 체인 위쪽 어딘가에서 불일치를 초래하게 됩니다.
비트코인의 중요한 확장성 기능은 블록이 다단계 데이터 구조로 저장된다는 것입니다. 블록의 "해시"는 실제로는 블록 헤더의 해시일 뿐입니다. 블록 헤더는 타임스탬프, 논스, 이전 블록 해시 및 블록의 모든 트랜잭션을 저장하는 머클 트리라는 데이터 구조의 루트 해시를 포함하는 약 200바이트의 데이터입니다. 머클 트리는 이진 트리의 일종으로, 기본 데이터를 포함하는 트리 맨 아래의 수많은 리프 노드 세트, 각 노드가 두 자식의 해시인 중간 노드 세트, 그리고 마지막으로 역시 두 자식의 해시로 형성되어 트리의 "꼭대기"를 나타내는 단일 루트 노드로 구성됩니다. 머클 트리의 목적은 블록의 데이터를 단편적으로 전달할 수 있도록 하는 것입니다. 노드는 한 소스에서 블록의 헤더만 다운로드하고 다른 소스에서 자신과 관련된 트리의 작은 부분만 다운로드하더라도 모든 데이터가 정확하다는 것을 확신할 수 있습니다. 이것이 작동하는 이유는 해시가 위로 전파되기 때문입니다. 악의적인 사용자가 머클 트리 맨 아래에 가짜 트랜잭션을 바꿔치기하려고 시도하면, 이 변경은 위쪽 노드의 변경을 유발하고, 그 위쪽 노드의 변경을 유발하여, 마침내 트리의 루트를 변경하고 결과적으로 블록의 해시를 변경하게 됩니다. 이로 인해 프로토콜은 이를 완전히 다른 블록으로 등록하게 됩니다(거의 확실하게 유효하지 않은 작업증명(PoW)을 갖게 됨).
머클 트리 프로토콜은 장기적인 지속 가능성에 필수적이라고 할 수 있습니다. 모든 블록의 전체를 저장하고 처리하는 비트코인 네트워크의 "풀 노드"는 2014년 4월 기준으로 비트코인 네트워크에서 약 15GB의 디스크 공간을 차지하며 매월 1기가바이트 이상씩 증가하고 있습니다. 현재 이것은 일부 데스크톱 컴퓨터에서는 가능하지만 휴대폰에서는 불가능하며, 먼 미래에는 기업과 취미로 하는 사람들만이 참여할 수 있게 될 것입니다. "단순 지불 검증(SPV)"으로 알려진 프로토콜은 "라이트 노드"라는 또 다른 클래스의 노드가 존재할 수 있게 해줍니다. 이 노드는 블록 헤더를 다운로드하고 블록 헤더의 작업증명(PoW)을 검증한 다음 자신과 관련된 트랜잭션과 연관된 "브랜치"만 다운로드합니다. 이를 통해 라이트 노드는 전체 블록체인의 아주 작은 부분만 다운로드하면서도 강력한 보안 보장과 함께 모든 비트코인 트랜잭션의 상태와 현재 잔액이 무엇인지 확인할 수 있습니다.
대안적 블록체인 애플리케이션
기반이 되는 블록체인 아이디어를 가져와 다른 개념에 적용하려는 아이디어 역시 오랜 역사를 가지고 있습니다. 2005년, 닉 사보(Nick Szabo)는 "소유자 권한이 있는 안전한 재산권(secure property titles with owner authority) (새 탭에서 열림)"이라는 개념을 발표했습니다. 이 문서는 "복제된 데이터베이스 기술의 새로운 발전"이 어떻게 누가 어떤 토지를 소유하고 있는지에 대한 등록부를 저장하는 블록체인 기반 시스템을 가능하게 하여, 홈스테딩(homesteading), 취득시효(adverse possession), 조지주의 토지세(Georgian land tax)와 같은 개념을 포함하는 정교한 프레임워크를 만들 수 있는지 설명합니다. 하지만 안타깝게도 당시에는 사용 가능한 효과적인 복제 데이터베이스 시스템이 없었기 때문에 이 프로토콜은 실제로 구현되지 못했습니다. 그러나 2009년 이후 비트코인의 탈중앙화된 합의가 개발되자 수많은 대안적 애플리케이션이 빠르게 등장하기 시작했습니다.
- Namecoin - 2010년에 생성된 Namecoin (새 탭에서 열림)은 탈중앙화된 이름 등록 데이터베이스로 가장 잘 설명할 수 있습니다. Tor, 비트코인, BitMessage와 같은 탈중앙화된 프로토콜에서는 다른 사람들이 상호 작용할 수 있도록 계정을 식별하는 방법이 필요하지만, 기존의 모든 솔루션에서 사용 가능한 유일한 식별자 종류는
1LW79wp5ZBqaHW1jL5TCiBCrhQYtHagUWy와 같은 의사 난수 해시뿐입니다. 이상적으로는 "george"와 같은 이름의 계정을 가질 수 있기를 원할 것입니다. 하지만 문제는 한 사람이 "george"라는 이름의 계정을 만들 수 있다면, 다른 사람도 동일한 프로세스를 사용하여 자신을 위해 "george"를 등록하고 그 사람을 사칭할 수 있다는 것입니다. 유일한 해결책은 첫 번째 등록자는 성공하고 두 번째 등록자는 실패하는 선출원(first-to-file) 패러다임이며, 이는 비트코인 합의 프로토콜에 완벽하게 적합한 문제입니다. Namecoin은 이러한 아이디어를 사용한 이름 등록 시스템 중 가장 오래되고 가장 성공적인 구현체입니다. - 컬러드 코인(Colored coins) - 컬러드 코인 (새 탭에서 열림)의 목적은 사람들이 비트코인 블록체인에서 자신만의 디지털 통화를 생성하거나, 단위가 하나인 통화의 중요하고 사소한 경우인 디지털 토큰을 생성할 수 있도록 하는 프로토콜 역할을 하는 것입니다. 컬러드 코인 프로토콜에서는 특정 비트코인 UTXO에 공개적으로 색상을 할당하여 새로운 통화를 "발행"하며, 프로토콜은 다른 UTXO의 색상을 이를 생성한 트랜잭션이 소비한 입력값의 색상과 동일하게 재귀적으로 정의합니다(혼합 색상 입력값의 경우 일부 특별한 규칙이 적용됨). 이를 통해 사용자는 특정 색상의 UTXO만 포함된 지갑을 유지하고 일반 비트코인과 마찬가지로 이를 전송할 수 있으며, 블록체인을 역추적하여 수신한 UTXO의 색상을 결정할 수 있습니다.
- 메타코인(Metacoins) - 메타코인의 이면에 있는 아이디어는 비트코인 위에 존재하는 프로토콜을 갖는 것입니다. 비트코인 트랜잭션을 사용하여 메타코인 트랜잭션을 저장하지만 다른 상태 전환 함수인
APPLY'를 갖습니다. 메타코인 프로토콜은 유효하지 않은 메타코인 트랜잭션이 비트코인 블록체인에 나타나는 것을 막을 수 없기 때문에,APPLY'(S,TX)가 오류를 반환하면 프로토콜이 기본적으로APPLY'(S,TX) = S로 설정된다는 규칙이 추가됩니다. 이는 비트코인 자체 내에서는 구현할 수 없는 고급 기능을 잠재적으로 갖춘 임의의 암호화폐 프로토콜을 생성하기 위한 쉬운 메커니즘을 제공합니다. 채굴 및 네트워킹의 복잡성은 이미 비트코인 프로토콜에 의해 처리되므로 개발 비용이 매우 낮습니다. 메타코인은 일부 금융 컨트랙트 클래스, 이름 등록 및 탈중앙화 거래소를 구현하는 데 사용되었습니다.
따라서 일반적으로 합의 프로토콜을 구축하는 데는 독립적인 네트워크를 구축하는 것과 비트코인 위에 프로토콜을 구축하는 두 가지 접근 방식이 있습니다. 전자의 접근 방식은 Namecoin과 같은 애플리케이션의 경우 꽤 성공적이었지만 구현하기가 어렵습니다. 각각의 개별 구현은 독립적인 블록체인을 부트스트랩해야 할 뿐만 아니라 필요한 모든 상태 전환 및 네트워킹 코드를 구축하고 테스트해야 합니다. 또한 우리는 탈중앙화된 합의 기술을 위한 애플리케이션 세트가 멱법칙 분포(power law distribution)를 따를 것으로 예측합니다. 즉, 대다수의 애플리케이션은 자체 블록체인을 보장하기에는 너무 작을 것이며, 서로 상호 작용해야 하는 대규모 탈중앙화 애플리케이션 클래스, 특히 탈중앙화 자율 조직(DAO)이 존재한다는 점에 주목합니다.
반면 비트코인 기반 접근 방식은 비트코인의 단순 지불 검증(SPV) 기능을 상속하지 않는다는 결함이 있습니다. SPV는 블록체인 깊이를 유효성의 프록시로 사용할 수 있기 때문에 비트코인에서 작동합니다. 어느 시점에서 트랜잭션의 조상이 충분히 멀리 거슬러 올라가면 합법적으로 상태의 일부였다고 말하는 것이 안전합니다. 반면 블록체인 기반 메타 프로토콜은 자체 프로토콜의 컨텍스트 내에서 유효하지 않은 트랜잭션을 포함하지 않도록 블록체인에 강제할 수 없습니다. 따라서 완전히 안전한 SPV 메타 프로토콜 구현은 특정 트랜잭션이 유효한지 여부를 확인하기 위해 비트코인 블록체인의 시작 부분까지 역방향으로 스캔해야 합니다. 현재 비트코인 기반 메타 프로토콜의 모든 "라이트" 구현은 데이터를 제공하기 위해 신뢰할 수 있는 서버에 의존하고 있습니다. 이는 특히 암호화폐의 주요 목적 중 하나가 신뢰의 필요성을 제거하는 것임을 고려할 때 매우 차선책인 결과라고 할 수 있습니다.
스크립팅
어떤 확장 기능이 없더라도 비트코인 프로토콜은 실제로 "스마트 컨트랙트" 개념의 약한 버전을 촉진합니다. 비트코인의 UTXO는 공개키뿐만 아니라 단순한 스택 기반 프로그래밍 언어로 표현된 더 복잡한 스크립트에 의해서도 소유될 수 있습니다. 이 패러다임에서 해당 UTXO를 소비하는 트랜잭션은 스크립트를 만족하는 데이터를 제공해야 합니다. 실제로 기본적인 공개키 소유권 메커니즘조차도 스크립트를 통해 구현됩니다. 스크립트는 타원 곡선 서명을 입력으로 받아 트랜잭션 및 UTXO를 소유한 주소와 대조하여 검증하고, 검증이 성공하면 1을 반환하고 그렇지 않으면 0을 반환합니다. 다양한 추가 사용 사례를 위한 더 복잡한 다른 스크립트도 존재합니다. 예를 들어, 검증을 위해 주어진 3개의 개인 키 중 2개의 서명이 필요한 스크립트("다중서명")를 구성할 수 있으며, 이는 기업 계정, 안전한 저축 계정 및 일부 판매자 에스크로 상황에 유용한 설정입니다. 스크립트는 연산 문제에 대한 해결책에 포상금을 지급하는 데 사용될 수도 있으며, "나에게 이 액면가의 도지코인(Dogecoin) 트랜잭션을 보냈다는 SPV 증명을 제공할 수 있다면 이 비트코인 UTXO는 당신의 것입니다"와 같은 스크립트를 구성하여 본질적으로 탈중앙화된 교차 암호화폐 교환을 허용할 수도 있습니다.
하지만 비트코인에 구현된 스크립팅 언어에는 몇 가지 중요한 한계가 있습니다.
- 튜링 완전성(Turing-completeness)의 부족 - 즉, 비트코인 스크립팅 언어가 지원하는 연산의 큰 하위 집합이 있지만 모든 것을 지원하지는 않습니다. 누락된 주요 범주는 루프(loop)입니다. 이는 트랜잭션 검증 중 무한 루프를 피하기 위해 수행됩니다. 이론적으로 if 문을 사용하여 기본 코드를 여러 번 반복하기만 하면 모든 루프를 시뮬레이션할 수 있으므로 스크립트 프로그래머가 극복할 수 있는 장애물이지만, 공간 효율성이 매우 떨어지는 스크립트가 생성됩니다. 예를 들어, 대안적인 타원 곡선 서명 알고리즘을 구현하려면 코드에 개별적으로 포함된 256번의 반복적인 곱셈 라운드가 필요할 것입니다.
- 가치 맹목성(Value-blindness) - UTXO 스크립트가 인출할 수 있는 금액에 대해 세밀한 제어를 제공할 방법이 없습니다. 예를 들어, 오라클 컨트랙트의 강력한 사용 사례 중 하나는 헤징 컨트랙트일 것입니다. 여기서 A와 B는 1000달러 가치의 BTC를 넣고 30일 후 스크립트가 1000달러 가치의 BTC를 A에게 보내고 나머지를 B에게 보냅니다. 이를 위해서는 1 BTC의 USD 가치를 결정하는 오라클이 필요하지만, 그렇다 하더라도 현재 사용 가능한 완전히 중앙화된 솔루션에 비해 신뢰 및 인프라 요구 사항 측면에서 엄청난 개선입니다. 하지만 UTXO는 전부 아니면 전무(all-or-nothing) 방식이기 때문에 이를 달성하는 유일한 방법은 다양한 액면가의 많은 UTXO(예: 최대 30까지의 모든 k에 대해 2k의 UTXO 1개)를 보유하고 오라클이 어떤 UTXO를 A에게 보내고 어떤 것을 B에게 보낼지 선택하도록 하는 매우 비효율적인 편법을 사용하는 것뿐입니다.
- 상태의 부족 - UTXO는 사용되거나 사용되지 않거나 둘 중 하나입니다. 다단계 컨트랙트나 그 이상의 다른 내부 상태를 유지하는 스크립트를 위한 기회가 없습니다. 이로 인해 다단계 옵션 컨트랙트, 탈중앙화 거래소 제안 또는 2단계 암호학적 커밋먼트 프로토콜(안전한 연산 포상금에 필요)을 만들기 어렵습니다. 또한 이는 UTXO가 단순하고 일회성인 컨트랙트를 구축하는 데만 사용될 수 있으며 탈중앙화 조직과 같은 더 복잡한 "상태 저장(stateful)" 컨트랙트에는 사용될 수 없음을 의미하며, 메타 프로토콜을 구현하기 어렵게 만듭니다. 가치 맹목성과 결합된 이진 상태는 또 다른 중요한 애플리케이션인 인출 한도 설정이 불가능하다는 것을 의미하기도 합니다.
- 블록체인 맹목성(Blockchain-blindness) - UTXO는 논스, 타임스탬프 및 이전 블록 해시와 같은 블록체인 데이터에 대해 알지 못합니다. 이는 스크립팅 언어에서 잠재적으로 가치 있는 무작위성 소스를 박탈함으로써 도박 및 기타 여러 범주의 애플리케이션을 심각하게 제한합니다.
따라서 암호화폐 위에 고급 애플리케이션을 구축하는 세 가지 접근 방식을 볼 수 있습니다. 새로운 블록체인 구축, 비트코인 위에서 스크립팅 사용, 비트코인 위에 메타 프로토콜 구축입니다. 새로운 블록체인을 구축하면 기능 세트를 구축하는 데 무한한 자유가 허용되지만 개발 시간, 부트스트래핑 노력 및 보안의 대가가 따릅니다. 스크립팅을 사용하는 것은 구현하고 표준화하기 쉽지만 기능이 매우 제한적이며, 메타 프로토콜은 쉽지만 확장성에 결함이 있습니다. 이더리움을 통해 우리는 개발 용이성에서 훨씬 더 큰 이점을 제공하고 훨씬 더 강력한 경량 클라이언트 속성을 제공하는 동시에 애플리케이션이 경제적 환경과 블록체인 보안을 공유할 수 있도록 하는 대안적 프레임워크를 구축하고자 합니다.
이더리움
이더리움의 목적은 탈중앙화 애플리케이션 (dapp)을 구축하기 위한 대안 프로토콜을 만드는 것으로, 대규모의 탈중앙화 애플리케이션에 매우 유용할 것이라 믿는 다른 일련의 절충안을 제공합니다. 특히 빠른 개발 시간, 작고 드물게 사용되는 애플리케이션을 위한 보안, 그리고 다른 애플리케이션들이 매우 효율적으로 상호작용할 수 있는 능력이 중요한 상황에 중점을 둡니다. 이더리움은 본질적으로 궁극적인 추상적 기반 계층을 구축함으로써 이를 수행합니다. 즉, 튜링 완전(Turing-complete) 프로그래밍 언어가 내장된 블록체인을 통해, 누구나 소유권, 트랜잭션 형식 및 상태 전환 함수에 대한 임의의 규칙을 직접 생성할 수 있는 스마트 컨트랙트와 탈중앙화 애플리케이션을 작성할 수 있게 합니다. Namecoin의 기본 버전은 단 두 줄의 코드로 작성할 수 있으며, 통화 및 평판 시스템과 같은 다른 프로토콜은 20줄 미만으로 구축할 수 있습니다. 가치를 포함하고 특정 조건이 충족될 때만 잠금을 해제하는 암호학적 "상자"인 스마트 컨트랙트 역시 이 플랫폼 위에 구축될 수 있습니다. 이는 튜링 완전성, 가치 인식, 블록체인 인식 및 상태라는 추가적인 기능 덕분에 비트코인 스크립팅이 제공하는 것보다 훨씬 더 강력한 성능을 발휘합니다.
이더리움 계정
이더리움에서 상태는 "계정"이라는 객체들로 구성되며, 각 계정은 20바이트의 주소를 가지고 상태 전환은 계정 간의 가치와 정보의 직접적인 전송으로 이루어집니다. 이더리움 계정은 다음 네 가지 필드를 포함합니다:
- 논스: 각 트랜잭션이 한 번만 처리되도록 보장하는 데 사용되는 카운터
- 계정의 현재 이더 잔고
- 계정의 컨트랙트 코드 (존재하는 경우)
- 계정의 스토리지 (기본적으로 비어 있음)
"이더"는 이더리움의 주요 내부 암호화 연료이며, 트랜잭션 수수료를 지불하는 데 사용됩니다. 일반적으로 계정에는 두 가지 유형이 있습니다. 개인 키에 의해 제어되는 외부 소유 계정(externally owned accounts)과 컨트랙트 코드에 의해 제어되는 컨트랙트 계정입니다. 외부 소유 계정에는 코드가 없으며, 트랜잭션을 생성하고 서명하기를 통해 외부 소유 계정에서 메시지를 보낼 수 있습니다. 반면 컨트랙트 계정은 메시지를 수신할 때마다 코드가 활성화되어 내부 스토리지를 읽고 쓸 수 있으며, 다른 메시지를 보내거나 차례로 컨트랙트를 생성할 수 있습니다.
이더리움에서 "컨트랙트"는 "이행"되거나 "준수"되어야 하는 것으로 간주되어서는 안 됩니다. 오히려 이더리움 실행 환경 내에 존재하는 "자율 에이전트(autonomous agents)"에 가깝습니다. 이들은 메시지나 트랜잭션에 의해 "찔렸을(poked)" 때 항상 특정 코드 조각을 실행하며, 영구적인 변수를 추적하기 위해 자체 이더 잔고와 자체 키/값 저장소에 대한 직접적인 제어권을 갖습니다.
메시지와 트랜잭션
이더리움에서 "트랜잭션"이라는 용어는 외부 소유 계정에서 보낼 메시지를 저장하는 서명된 데이터 패키지를 지칭하는 데 사용됩니다. 트랜잭션에는 다음이 포함됩니다:
- 메시지 수신자
- 발신자를 식별하는 서명
- 발신자에서 수신자로 전송할 이더의 양
- 선택적 데이터 필드
- 트랜잭션 실행에 허용되는 최대 연산 단계 수를 나타내는
STARTGAS값 - 연산 단계당 발신자가 지불하는 수수료를 나타내는
GASPRICE값
처음 세 가지는 모든 암호화폐에서 예상되는 표준 필드입니다. 데이터 필드는 기본적으로 아무런 기능이 없지만, 가상 머신에는 컨트랙트가 데이터에 접근할 수 있게 해주는 연산 코드가 있습니다. 사용 사례의 예로, 컨트랙트가 온체인 도메인 등록 서비스로 기능하는 경우, 자신에게 전달되는 데이터가 두 개의 "필드"를 포함하는 것으로 해석하고자 할 수 있습니다. 첫 번째 필드는 등록할 도메인이고 두 번째 필드는 등록할 IP 주소입니다. 컨트랙트는 메시지 데이터에서 이 값들을 읽어 스토리지에 적절히 배치할 것입니다.
STARTGAS 및 GASPRICE 필드는 이더리움의 서비스 거부(DoS) 방지 모델에 매우 중요합니다. 코드 내에서 우발적이거나 악의적인 무한 루프 또는 기타 연산 낭비를 방지하기 위해, 각 트랜잭션은 사용할 수 있는 코드 실행의 연산 단계 수에 한도를 설정해야 합니다. 연산의 기본 단위는 "가스"입니다. 일반적으로 하나의 연산 단계는 1 가스의 비용이 들지만, 일부 작업은 연산 비용이 더 많이 들거나 상태의 일부로 저장해야 하는 데이터의 양을 증가시키기 때문에 더 많은 양의 가스 비용이 듭니다. 또한 트랜잭션 데이터의 모든 바이트에 대해 5 가스의 수수료가 부과됩니다. 수수료 시스템의 목적은 공격자가 연산, 대역폭 및 스토리지를 포함하여 소비하는 모든 리소스에 비례하여 비용을 지불하도록 요구하는 것입니다. 따라서 네트워크가 이러한 리소스 중 어느 것이든 더 많이 소비하게 만드는 트랜잭션은 그 증가분에 대략 비례하는 가스비를 가져야 합니다.
메시지
컨트랙트는 다른 컨트랙트에 "메시지"를 보낼 수 있는 기능이 있습니다. 메시지는 직렬화되지 않으며 이더리움 실행 환경에만 존재하는 가상 객체입니다. 메시지에는 다음이 포함됩니다:
- 메시지 발신자 (암시적)
- 메시지 수신자
- 메시지와 함께 전송할 이더의 양
- 선택적 데이터 필드
STARTGAS값
본질적으로 메시지는 외부 행위자가 아닌 컨트랙트에 의해 생성된다는 점을 제외하면 트랜잭션과 같습니다. 메시지는 현재 코드를 실행 중인 컨트랙트가 CALL 연산 코드를 실행할 때 생성되며, 이는 메시지를 생성하고 실행합니다. 트랜잭션과 마찬가지로 메시지는 수신 계정이 자신의 코드를 실행하도록 유도합니다. 따라서 컨트랙트는 외부 행위자가 할 수 있는 것과 정확히 동일한 방식으로 다른 컨트랙트와 관계를 맺을 수 있습니다.
트랜잭션이나 컨트랙트에 의해 할당된 가스 허용량은 해당 트랜잭션과 모든 하위 실행에서 소비된 총 가스에 적용된다는 점에 유의하세요. 예를 들어, 외부 행위자 A가 1000 가스와 함께 B에게 트랜잭션을 보내고, B가 C에게 메시지를 보내기 전에 600 가스를 소비하며, C의 내부 실행이 반환되기 전에 300 가스를 소비한다면, B는 가스가 고갈되기 전에 100 가스를 추가로 사용할 수 있습니다.
이더리움 상태 전환 함수
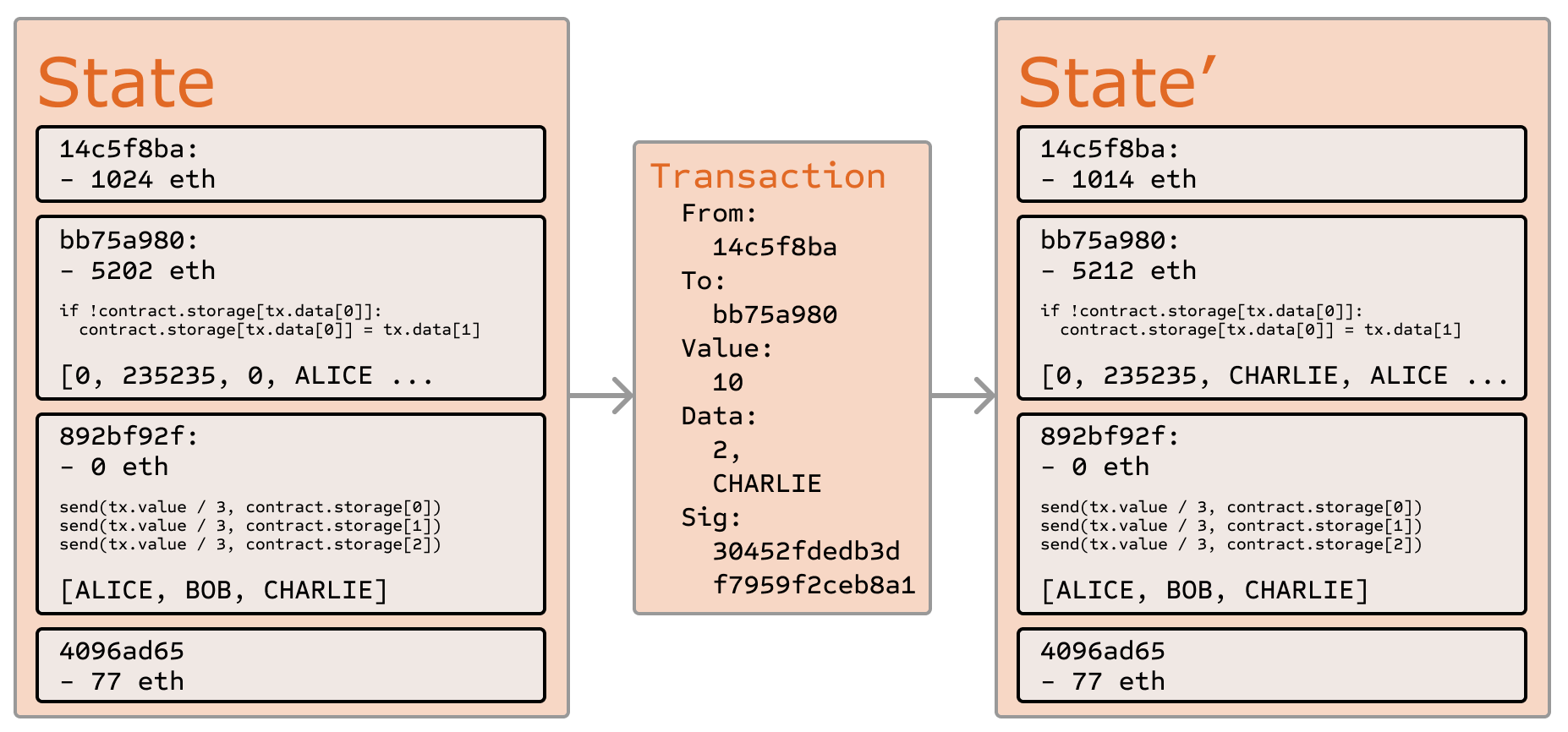
이더리움 상태 전환 함수인 APPLY(S,TX) -> S'는 다음과 같이 정의할 수 있습니다:
- 트랜잭션이 올바른 형식인지(즉, 올바른 수의 값을 가지고 있는지), 서명이 유효한지, 논스가 발신자 계정의 논스와 일치하는지 확인합니다. 그렇지 않으면 오류를 반환합니다.
- 트랜잭션 수수료를
STARTGAS * GASPRICE로 계산하고, 서명에서 발신 주소를 결정합니다. 발신자의 계정 잔고에서 수수료를 빼고 발신자의 논스를 증가시킵니다. 지출할 잔고가 충분하지 않으면 오류를 반환합니다. GAS = STARTGAS를 초기화하고, 트랜잭션의 바이트에 대한 비용을 지불하기 위해 바이트당 일정량의 가스를 차감합니다.- 발신자 계정에서 수신 계정으로 트랜잭션 가치를 전송합니다. 수신 계정이 아직 존재하지 않으면 생성합니다. 수신 계정이 컨트랙트인 경우, 완료될 때까지 또는 실행 중 가스가 고갈될 때까지 컨트랙트의 코드를 실행합니다.
- 발신자의 자금이 부족하여 가치 전송에 실패하거나 코드 실행 중 가스가 고갈되면, 수수료 지불을 제외한 모든 상태 변경을 되돌리기하고 수수료를 채굴자의 계정에 추가합니다.
- 그렇지 않은 경우, 남은 모든 가스에 대한 수수료를 발신자에게 환불하고, 소비된 가스에 대해 지불된 수수료를 채굴자에게 보냅니다.
예를 들어, 컨트랙트의 코드가 다음과 같다고 가정해 보겠습니다:
if !self.storage[calldataload(0)]:
self.storage[calldataload(0)] = calldataload(32)
실제로는 컨트랙트 코드가 저수준 EVM 코드로 작성된다는 점에 유의하세요. 이 예제는 명확성을 위해 우리의 고수준 언어 중 하나인 Serpent로 작성되었으며, EVM 코드로 컴파일될 수 있습니다. 컨트랙트의 스토리지가 비어 있는 상태에서 시작하고, 10 이더의 가치, 2000 가스, 0.001 이더의 가스 가격, 그리고 64바이트의 데이터와 함께 트랜잭션이 전송되었다고 가정해 보겠습니다. 여기서 0-31 바이트는 숫자 2를 나타내고 32-63 바이트는 문자열 CHARLIEfn3을 나타냅니다. 이 경우 상태 전환 함수의 프로세스는 다음과 같습니다:
- 트랜잭션이 유효하고 올바른 형식인지 확인합니다.
- 트랜잭션 발신자가 최소 2000 * 0.001 = 2 이더를 가지고 있는지 확인합니다. 그렇다면 발신자의 계정에서 2 이더를 뺍니다.
- 가스 = 2000으로 초기화합니다. 트랜잭션 길이가 170바이트이고 바이트 수수료가 5라고 가정할 때, 850을 빼서 1150 가스가 남도록 합니다.
- 발신자의 계정에서 10 이더를 추가로 빼고, 이를 컨트랙트의 계정에 더합니다.
- 코드를 실행합니다. 이 경우는 간단합니다. 인덱스
2에 있는 컨트랙트의 스토리지가 사용 중인지 확인하고, 그렇지 않다는 것을 인식한 다음, 인덱스2의 스토리지를CHARLIE값으로 설정합니다. 이 작업에 187 가스가 소요된다고 가정하면, 남은 가스 양은 1150 - 187 = 963이 됩니다. - 963 * 0.001 = 0.963 이더를 발신자의 계정에 다시 더하고, 결과 상태를 반환합니다.
트랜잭션의 수신 측에 컨트랙트가 없다면, 총 트랜잭션 수수료는 단순히 제공된 GASPRICE에 트랜잭션의 바이트 길이를 곱한 값과 같을 것이며, 트랜잭션과 함께 전송된 데이터는 무관할 것입니다.
되돌리기 측면에서 메시지는 트랜잭션과 동일하게 작동한다는 점에 유의하세요. 메시지 실행 중 가스가 고갈되면 해당 메시지의 실행과 그 실행에 의해 트리거된 다른 모든 실행은 되돌리기되지만, 상위 실행은 되돌리기할 필요가 없습니다. 이는 컨트랙트가 다른 컨트랙트를 호출하는 것이 "안전"하다는 것을 의미합니다. 마치 A가 G 가스로 B를 호출하면 A의 실행은 최대 G 가스만 잃도록 보장되는 것과 같습니다. 마지막으로, 컨트랙트를 생성하는 연산 코드인 CREATE가 있다는 점에 유의하세요. 이 연산 코드의 실행 메커니즘은 일반적으로 CALL와 유사하지만, 실행 출력이 새로 생성된 컨트랙트의 코드를 결정한다는 점이 다릅니다.
코드 실행
이더리움 컨트랙트의 코드는 "이더리움 가상 머신 코드" 또는 "EVM 코드"라고 불리는 저수준의 스택 기반 바이트코드 언어로 작성됩니다. 코드는 일련의 바이트로 구성되며, 각 바이트는 하나의 연산을 나타냅니다. 일반적으로 코드 실행은 현재 프로그램 카운터(0에서 시작)에서 연산을 반복적으로 수행한 다음 프로그램 카운터를 1씩 증가시키는 무한 루프로 구성되며, 코드의 끝에 도달하거나 오류 또는 STOP나 RETURN 명령이 감지될 때까지 계속됩니다. 연산은 데이터를 저장할 수 있는 세 가지 유형의 공간에 접근할 수 있습니다:
- 스택: 값을 푸시(push)하고 팝(pop)할 수 있는 후입선출(LIFO) 컨테이너
- 메모리: 무한히 확장 가능한 바이트 배열
- 컨트랙트의 장기 스토리지: 키/값 저장소. 연산이 끝난 후 초기화되는 스택 및 메모리와 달리 스토리지는 장기간 지속됩니다.
코드는 수신되는 메시지의 가치, 발신자 및 데이터뿐만 아니라 블록 헤더 데이터에도 접근할 수 있으며, 데이터의 바이트 배열을 출력으로 반환할 수도 있습니다.
EVM 코드의 공식적인 실행 모델은 놀라울 정도로 간단합니다. 이더리움 가상 머신이 실행되는 동안, 전체 연산 상태는 튜플 (block_state, transaction, message, code, memory, stack, pc, gas)로 정의될 수 있습니다. 여기서 block_state는 모든 계정을 포함하고 잔고와 스토리지를 포함하는 전역 상태입니다. 매 실행 라운드가 시작될 때, code의 pc번째 바이트를 가져와 현재 명령을 찾으며(pc >= len(code)인 경우 0), 각 명령은 튜플에 미치는 영향에 대한 고유한 정의를 가지고 있습니다. 예를 들어, ADD는 스택에서 두 개의 항목을 팝하고 그 합을 푸시하며, gas를 1만큼 줄이고 pc를 1만큼 증가시킵니다. 그리고 SSTORE는 스택에서 상위 두 개의 항목을 팝하고 첫 번째 항목이 지정한 인덱스의 컨트랙트 스토리지에 두 번째 항목을 삽입합니다. 적시 컴파일(JIT)을 통해 이더리움 가상 머신 실행을 최적화하는 방법은 여러 가지가 있지만, 이더리움의 기본 구현은 몇 백 줄의 코드로 완료할 수 있습니다.
블록체인과 채굴

이더리움 블록체인은 여러 면에서 비트코인 블록체인과 유사하지만 몇 가지 차이점이 있습니다. 블록체인 아키텍처와 관련하여 이더리움과 비트코인의 주요 차이점은 비트코인과 달리 이더리움 블록에는 트랜잭션 목록과 가장 최근 상태의 사본이 모두 포함되어 있다는 것입니다. 그 외에도 블록 번호와 난이도라는 두 가지 다른 값도 블록에 저장됩니다. 이더리움의 기본 블록 검증 알고리즘은 다음과 같습니다:
- 참조된 이전 블록이 존재하고 유효한지 확인합니다.
- 블록의 타임스탬프가 참조된 이전 블록의 타임스탬프보다 크고 미래의 15분 이내인지 확인합니다.
- 블록 번호, 난이도, 트랜잭션 루트, 엉클 루트 및 가스 한도(다양한 저수준 이더리움 전용 개념)가 유효한지 확인합니다.
- 블록의 작업증명 (PoW)이 유효한지 확인합니다.
S[0]를 이전 블록 끝의 상태라고 가정합니다.TX를n개의 트랜잭션이 있는 블록의 트랜잭션 목록이라고 가정합니다.0...n-1의 모든i에 대해S[i+1] = APPLY(S[i],TX[i])를 설정합니다. 애플리케이션이 오류를 반환하거나 이 시점까지 블록에서 소비된 총 가스가GASLIMIT를 초과하면 오류를 반환합니다.S_FINAL를S[n]로 하되, 채굴자에게 지급되는 블록 보상을 추가합니다.- 상태
S_FINAL의 머클 트리 루트가 블록 헤더에 제공된 최종 상태 루트와 같은지 확인합니다. 같으면 블록이 유효하고, 그렇지 않으면 유효하지 않습니다.
이 접근 방식은 각 블록에 전체 상태를 저장해야 하므로 언뜻 보기에 매우 비효율적으로 보일 수 있지만, 실제로는 비트코인과 비슷한 수준의 효율성을 가져야 합니다. 그 이유는 상태가 트리 구조로 저장되며, 매 블록 이후 트리의 작은 부분만 변경하면 되기 때문입니다. 따라서 일반적으로 인접한 두 블록 사이에서 트리의 대부분은 동일해야 하므로, 데이터는 한 번만 저장되고 포인터(즉, 하위 트리의 해시)를 사용하여 두 번 참조될 수 있습니다. 이를 달성하기 위해 "패트리샤 트리(Patricia tree)"로 알려진 특별한 종류의 트리가 사용되며, 여기에는 노드를 단순히 변경하는 것뿐만 아니라 효율적으로 삽입하고 삭제할 수 있도록 머클 트리 개념을 수정한 내용이 포함됩니다. 또한 모든 상태 정보가 마지막 블록의 일부이기 때문에 전체 블록체인 기록을 저장할 필요가 없습니다. 이 전략을 비트코인에 적용할 수 있다면 공간을 5~20배 절약할 수 있을 것으로 계산됩니다.
흔히 묻는 질문은 물리적 하드웨어 측면에서 컨트랙트 코드가 "어디서" 실행되는가 하는 것입니다. 이에 대한 대답은 간단합니다. 컨트랙트 코드를 실행하는 프로세스는 블록 검증 알고리즘의 일부인 상태 전환 함수 정의의 일부입니다. 따라서 트랜잭션이 블록 B에 추가되면, 해당 트랜잭션에 의해 생성된 코드 실행은 현재와 미래에 블록 B를 다운로드하고 검증하는 모든 노드에 의해 실행됩니다.
애플리케이션
일반적으로 이더리움 위에는 세 가지 유형의 애플리케이션이 있습니다. 첫 번째 범주는 금융 애플리케이션으로, 사용자에게 자신의 돈을 사용하여 자금을 관리하고 컨트랙트를 체결하는 더 강력한 방법을 제공합니다. 여기에는 하위 통화, 금융 파생상품, 헤징 컨트랙트, 예금 지갑, 유언장, 그리고 궁극적으로는 일부 본격적인 고용 컨트랙트까지 포함됩니다. 두 번째 범주는 반금융(semi-financial) 애플리케이션으로, 돈이 관련되어 있지만 수행되는 작업에 비금전적인 측면도 크게 작용하는 경우입니다. 완벽한 예로는 연산 문제 해결에 대한 자동 집행 현상금이 있습니다. 마지막으로, 온라인 투표 및 탈중앙화된 거버넌스와 같이 금융과 전혀 관련이 없는 애플리케이션이 있습니다.
토큰 시스템
블록체인 상의 토큰 시스템은 USD나 금과 같은 자산을 나타내는 하위 통화부터 회사 주식, 스마트 자산을 나타내는 개별 토큰, 위조 불가능한 안전한 쿠폰, 심지어 기존 가치와 전혀 관련이 없이 인센티브를 위한 포인트 시스템으로 사용되는 토큰 시스템에 이르기까지 다양한 애플리케이션을 가지고 있습니다. 토큰 시스템은 이더리움에서 놀라울 정도로 쉽게 구현할 수 있습니다. 이해해야 할 핵심은 통화나 토큰 시스템이 근본적으로 단 하나의 연산을 가진 데이터베이스라는 점입니다. 즉, (i) 트랜잭션 전에 A가 최소한 X 단위를 가지고 있었고 (2) 트랜잭션이 A에 의해 승인되었다는 조건 하에, A에서 X 단위를 빼서 B에게 X 단위를 주는 것입니다. 토큰 시스템을 구현하는 데 필요한 것은 이 로직을 컨트랙트에 구현하는 것뿐입니다.
서펀트(Serpent)로 토큰 시스템을 구현하기 위한 기본 코드는 다음과 같습니다.
def send(to, value):
if self.storage[msg.sender] >= value:
self.storage[msg.sender] = self.storage[msg.sender] - value
self.storage[to] = self.storage[to] + value
이것은 본질적으로 이 문서의 앞부분에서 설명한 "은행 시스템" 상태 전환 함수를 문자 그대로 구현한 것입니다. 처음에 통화 단위를 분배하는 초기 단계와 몇 가지 다른 엣지 케이스를 처리하기 위해 몇 줄의 코드를 추가해야 하며, 이상적으로는 다른 컨트랙트가 주소의 잔액을 조회할 수 있도록 하는 함수가 추가되어야 합니다. 하지만 그게 전부입니다. 이론적으로, 하위 통화 역할을 하는 이더리움 기반 토큰 시스템은 온체인 비트코인 기반 메타 통화에는 없는 또 다른 중요한 기능을 포함할 수 있습니다. 바로 해당 통화로 직접 트랜잭션 수수료를 지불할 수 있는 기능입니다. 이것이 구현되는 방식은 컨트랙트가 발신자에게 수수료를 지불하는 데 사용된 이더를 환불해 줄 이더 잔액을 유지하고, 수수료로 받은 내부 통화 단위를 모아 지속적으로 실행되는 경매에서 재판매함으로써 이 잔액을 다시 채우는 것입니다. 따라서 사용자는 이더로 계정을 "활성화"해야 하지만, 일단 이더가 있으면 컨트랙트가 매번 환불해 주기 때문에 재사용할 수 있습니다.
금융 파생상품 및 가치 안정 통화
금융 파생상품은 "스마트 컨트랙트"의 가장 일반적인 애플리케이션이며, 코드로 구현하기 가장 간단한 것 중 하나입니다. 금융 컨트랙트를 구현할 때의 주요 과제는 대부분 외부 가격 티커를 참조해야 한다는 것입니다. 예를 들어, 매우 바람직한 애플리케이션은 미국 달러 대비 이더(또는 다른 암호화폐)의 변동성을 헤지하는 스마트 컨트랙트이지만, 이를 위해서는 컨트랙트가 ETH/USD의 가치를 알아야 합니다. 이를 수행하는 가장 간단한 방법은 특정 당사자(예: NASDAQ)가 유지 관리하는 "데이터 피드" 컨트랙트를 통하는 것입니다. 이 컨트랙트는 해당 당사자가 필요에 따라 컨트랙트를 업데이트할 수 있도록 설계되었으며, 다른 컨트랙트가 해당 컨트랙트에 메시지를 보내고 가격을 제공하는 응답을 받을 수 있는 인터페이스를 제공합니다.
이러한 핵심 요소가 주어지면 헤징 컨트랙트는 다음과 같습니다.
- 당사자 A가 1000 이더를 입력할 때까지 기다립니다.
- 당사자 B가 1000 이더를 입력할 때까지 기다립니다.
- 데이터 피드 컨트랙트를 조회하여 계산된 1000 이더의 USD 가치를 스토리지에 기록합니다. 이를 $x라고 가정합니다.
- 30일 후, A 또는 B가 컨트랙트를 "재활성화"하여 $x 가치의 이더(데이터 피드 컨트랙트를 다시 조회하여 새로운 가격을 얻어 계산됨)를 A에게 보내고 나머지를 B에게 보낼 수 있도록 허용합니다.
이러한 컨트랙트는 암호화폐 상거래에서 상당한 잠재력을 가질 것입니다. 암호화폐에 대해 언급되는 주요 문제 중 하나는 변동성이 크다는 사실입니다. 많은 사용자와 상인이 암호화폐 자산을 다루는 보안과 편의성을 원할 수 있지만, 단 하루 만에 자금 가치의 23%를 잃을 수 있는 상황에 직면하고 싶어 하지는 않을 것입니다. 지금까지 가장 일반적으로 제안된 해결책은 발행자가 뒷받침하는 자산이었습니다. 이 아이디어는 발행자가 단위를 발행하고 취소할 권리가 있는 하위 통화를 생성하고, 지정된 기초 자산(예: 금, USD) 1단위를 (오프라인으로) 제공하는 모든 사람에게 해당 통화 1단위를 제공하는 것입니다. 그런 다음 발행자는 암호화폐 자산 1단위를 돌려보내는 모든 사람에게 기초 자산 1단위를 제공할 것을 약속합니다. 이 메커니즘을 통해 발행자를 신뢰할 수 있다면 비암호화 자산을 암호화폐 자산으로 "격상"시킬 수 있습니다.
그러나 실제로는 발행자를 항상 신뢰할 수 있는 것은 아니며, 경우에 따라 은행 인프라가 너무 취약하거나 적대적이어서 이러한 서비스가 존재하기 어렵습니다. 금융 파생상품은 대안을 제공합니다. 여기서는 단일 발행자가 자산을 뒷받침할 자금을 제공하는 대신, 암호화폐 참조 자산(예: ETH)의 가격이 오를 것이라고 베팅하는 투기꾼들의 탈중앙화된 시장이 그 역할을 합니다. 발행자와 달리 투기꾼은 헤징 컨트랙트가 그들의 자금을 에스크로에 보관하기 때문에 거래에서 채무를 불이행할 수 있는 선택권이 없습니다. 이 접근 방식은 가격 티커를 제공하기 위해 여전히 신뢰할 수 있는 출처가 필요하기 때문에 완전히 탈중앙화된 것은 아닙니다. 하지만 인프라 요구 사항을 줄이고(발행자가 되는 것과 달리 가격 피드를 발행하는 데는 라이선스가 필요하지 않으며 표현의 자유로 분류될 가능성이 높음) 사기 가능성을 줄인다는 측면에서 여전히 엄청난 개선이라고 할 수 있습니다.
신원 및 평판 시스템
가장 초기의 대안 암호화폐인 Namecoin (새 탭에서 열림)은 비트코인과 유사한 블록체인을 사용하여 사용자가 다른 데이터와 함께 공개 데이터베이스에 자신의 이름을 등록할 수 있는 이름 등록 시스템을 제공하려고 시도했습니다. 주로 언급되는 사용 사례는 "bitcoin.org"(또는 Namecoin의 경우 "bitcoin.bit")와 같은 도메인 이름을 IP 주소에 매핑하는 DNS (새 탭에서 열림) 시스템입니다. 다른 사용 사례로는 이메일 인증 및 잠재적으로 더 발전된 평판 시스템이 있습니다. 이더리움에서 Namecoin과 유사한 이름 등록 시스템을 제공하는 기본 컨트랙트는 다음과 같습니다.
def register(name, value):
if !self.storage[name]:
self.storage[name] = value
컨트랙트는 매우 간단합니다. 이더리움 네트워크 내부에 추가할 수는 있지만 수정하거나 제거할 수는 없는 데이터베이스일 뿐입니다. 누구나 어떤 값과 함께 이름을 등록할 수 있으며, 그 등록은 영원히 유지됩니다. 더 정교한 이름 등록 컨트랙트에는 다른 컨트랙트가 이를 조회할 수 있도록 하는 "함수 절"과 이름의 "소유자"(즉, 최초 등록자)가 데이터를 변경하거나 소유권을 이전할 수 있는 메커니즘도 포함될 것입니다. 그 위에 평판 및 신뢰의 웹(web-of-trust) 기능을 추가할 수도 있습니다.
탈중앙화된 파일 스토리지
지난 몇 년 동안 사용자가 하드 드라이브의 백업을 업로드하고 서비스가 백업을 저장하여 월별 요금을 대가로 사용자가 액세스할 수 있도록 하는 수많은 인기 있는 온라인 파일 스토리지 스타트업이 등장했으며, 가장 눈에 띄는 것은 Dropbox입니다. 그러나 현시점에서 파일 스토리지 시장은 때때로 상대적으로 비효율적입니다. 기존의 다양한 솔루션을 대략적으로 살펴보면, 특히 무료 할당량이나 기업 수준의 할인이 적용되지 않는 "불쾌한 골짜기(uncanny valley)"인 20-200GB 수준에서 주류 파일 스토리지의 월별 비용은 단 한 달 만에 전체 하드 드라이브 비용보다 더 많은 비용을 지불하게 되는 수준입니다. 이더리움 컨트랙트는 개별 사용자가 자신의 하드 드라이브를 임대하여 소액의 돈을 벌 수 있고 사용하지 않는 공간을 사용하여 파일 스토리지 비용을 더욱 낮출 수 있는 탈중앙화된 파일 스토리지 생태계의 개발을 가능하게 합니다.
이러한 장치의 핵심 기반은 우리가 "탈중앙화된 Dropbox 컨트랙트"라고 부르는 것이 될 것입니다. 이 컨트랙트는 다음과 같이 작동합니다. 먼저, 원하는 데이터를 블록으로 나누고 프라이버시를 위해 각 블록을 암호화한 다음, 이를 바탕으로 머클 트리를 구축합니다. 그런 다음 N개의 블록마다 컨트랙트가 머클 트리에서 무작위 인덱스를 선택하고(컨트랙트 코드에서 액세스할 수 있는 이전 블록 해시를 무작위성 소스로 사용), 트리의 해당 특정 인덱스에 있는 블록의 소유권에 대한 단순 지불 검증(SPV)과 유사한 증명을 트랜잭션과 함께 제공하는 첫 번째 엔티티에게 X 이더를 제공한다는 규칙을 가진 컨트랙트를 만듭니다. 사용자가 파일을 다시 다운로드하려는 경우 소액 결제 채널 프로토콜(예: 32킬로바이트당 1 사보 지불)을 사용하여 파일을 복구할 수 있습니다. 수수료 측면에서 가장 효율적인 접근 방식은 지불자가 끝날 때까지 트랜잭션을 게시하지 않고, 대신 매 32킬로바이트마다 동일한 논스를 가진 약간 더 수익성 있는 트랜잭션으로 교체하는 것입니다.
이 프로토콜의 중요한 특징은 많은 무작위 노드가 파일을 잊어버리지 않기로 결정할 것이라고 신뢰하는 것처럼 보일 수 있지만, 비밀 공유(secret sharing)를 통해 파일을 여러 조각으로 나누고 컨트랙트를 모니터링하여 각 조각이 여전히 어떤 노드의 소유인지 확인함으로써 그 위험을 거의 0으로 줄일 수 있다는 것입니다. 컨트랙트가 여전히 돈을 지불하고 있다면, 이는 누군가가 여전히 파일을 저장하고 있다는 암호학적 증명을 제공합니다.
탈중앙화된 자율 조직
"탈중앙화된 자율 조직(DAO)"의 일반적인 개념은 특정 구성원 또는 주주 집합을 가진 가상 엔티티로, 아마도 67%의 다수결로 엔티티의 자금을 사용하고 코드를 수정할 권리를 갖는 것입니다. 구성원들은 조직이 자금을 어떻게 할당해야 하는지 집단적으로 결정합니다. DAO의 자금을 할당하는 방법은 현상금, 급여에서부터 작업에 보상하기 위한 내부 통화와 같은 훨씬 더 독특한 메커니즘에 이르기까지 다양할 수 있습니다. 이는 본질적으로 전통적인 회사나 비영리 단체의 법적 틀을 복제하지만, 집행을 위해 암호학적 블록체인 기술만을 사용합니다. 지금까지 DAO에 대한 많은 논의는 배당금을 받는 주주와 거래 가능한 주식이 있는 "탈중앙화된 자율 기업(DAC)"의 "자본주의적" 모델을 중심으로 이루어졌습니다. 아마도 "탈중앙화된 자율 커뮤니티"로 설명될 수 있는 대안은 모든 구성원이 의사 결정에서 동등한 몫을 가지며 구성원을 추가하거나 제거하려면 기존 구성원의 67%가 동의해야 하는 형태일 것입니다. 그러면 한 사람이 하나의 멤버십만 가질 수 있다는 요구 사항은 그룹에 의해 집단적으로 집행되어야 합니다.
DAO를 코딩하는 방법에 대한 일반적인 개요는 다음과 같습니다. 가장 단순한 설계는 구성원의 3분의 2가 변경에 동의하면 변경되는 자가 수정 코드(self-modifying code)입니다. 코드는 이론적으로 불변이지만, 코드 덩어리를 별도의 컨트랙트에 두고 호출할 컨트랙트의 주소를 수정 가능한 스토리지에 저장함으로써 이를 쉽게 우회하고 사실상의 가변성을 가질 수 있습니다. 이러한 DAO 컨트랙트의 간단한 구현에는 트랜잭션에 제공된 데이터로 구분되는 세 가지 트랜잭션 유형이 있습니다.
- 스토리지 인덱스
K의 주소를 값V로 변경하기 위해 인덱스i와 함께 제안을 등록하는[0,i,K,V] - 제안
i에 찬성하는 투표를 등록하는[1,i] - 충분한 투표가 이루어진 경우 제안
i를 확정하는[2,i]
그런 다음 컨트랙트에는 이들 각각에 대한 절이 있습니다. 열려 있는 모든 스토리지 변경 사항의 기록과 함께 누가 투표했는지에 대한 목록을 유지합니다. 또한 모든 구성원의 목록도 있습니다. 스토리지 변경 사항에 대해 구성원의 3분의 2가 투표하면 확정 트랜잭션이 변경 사항을 실행할 수 있습니다. 더 정교한 뼈대에는 트랜잭션 전송, 구성원 추가 및 구성원 제거와 같은 기능을 위한 내장된 투표 기능이 있으며, 유동적 민주주의(Liquid Democracy) (새 탭에서 열림) 스타일의 투표 위임(즉, 누구나 자신을 대신하여 투표할 사람을 지정할 수 있으며, 지정은 전이적이므로 A가 B를 지정하고 B가 C를 지정하면 C가 A의 투표를 결정함)을 제공할 수도 있습니다. 이러한 설계는 DAO가 탈중앙화된 커뮤니티로서 유기적으로 성장할 수 있게 하여, 사람들이 결국 누가 구성원인지 필터링하는 작업을 전문가에게 위임할 수 있도록 합니다. 하지만 "현재 시스템"과 달리 개별 커뮤니티 구성원이 자신의 성향을 변경함에 따라 전문가는 시간이 지남에 따라 쉽게 나타나고 사라질 수 있습니다.
대안 모델은 탈중앙화된 기업을 위한 것으로, 모든 계정이 0개 이상의 주식을 가질 수 있으며 의사 결정을 내리려면 주식의 3분의 2가 필요합니다. 완전한 뼈대에는 자산 관리 기능, 주식 매수 또는 매도 제안을 하는 기능, 제안을 수락하는 기능(가급적이면 컨트랙트 내부에 주문 매칭 메커니즘 포함)이 포함됩니다. 위임 또한 유동적 민주주의 스타일로 존재하여 "이사회"의 개념을 일반화할 것입니다.
추가 애플리케이션
1. 예금 지갑. 앨리스가 자신의 자금을 안전하게 보관하고 싶지만 개인 키를 잃어버리거나 누군가 해킹할까 봐 걱정한다고 가정해 보겠습니다. 그녀는 다음과 같이 은행인 밥과 함께 컨트랙트에 이더를 넣습니다.
- 앨리스 혼자서는 하루에 자금의 최대 1%만 인출할 수 있습니다.
- 밥 혼자서는 하루에 자금의 최대 1%만 인출할 수 있지만, 앨리스는 자신의 키로 트랜잭션을 생성하여 이 기능을 차단할 수 있습니다.
- 앨리스와 밥이 함께하면 얼마든지 인출할 수 있습니다.
일반적으로 하루 1%는 앨리스에게 충분하며, 앨리스가 더 많이 인출하고 싶다면 밥에게 연락하여 도움을 받을 수 있습니다. 앨리스의 키가 해킹당하면 그녀는 밥에게 달려가 자금을 새 컨트랙트로 옮깁니다. 그녀가 키를 잃어버리면 밥이 결국 자금을 빼낼 것입니다. 밥이 악의적인 것으로 판명되면 그녀는 밥의 인출 기능을 차단할 수 있습니다.
2. 농작물 보험. 가격 지수 대신 날씨 데이터 피드를 사용하여 금융 파생상품 컨트랙트를 쉽게 만들 수 있습니다. 아이오와주의 한 농부가 아이오와주의 강수량에 반비례하여 지불하는 파생상품을 구매한다면, 가뭄이 들 경우 농부는 자동으로 돈을 받게 되고 비가 충분히 오면 농작물이 잘 자랄 것이기 때문에 농부는 행복할 것입니다. 이는 일반적으로 자연재해 보험으로 확장될 수 있습니다.
3. 탈중앙화된 데이터 피드. 금융 차액 결제 거래(CFD)의 경우, 실제로 "SchellingCoin (새 탭에서 열림)"이라는 프로토콜을 통해 데이터 피드를 탈중앙화하는 것이 가능할 수 있습니다. SchellingCoin은 기본적으로 다음과 같이 작동합니다. N명의 당사자가 모두 주어진 데이터(예: ETH/USD 가격)의 값을 시스템에 입력하고, 값이 정렬되며, 25번째에서 75번째 백분위수 사이에 있는 모든 사람은 보상으로 토큰 1개를 받습니다. 모든 사람은 다른 모든 사람이 제공할 답변을 제공할 인센티브가 있으며, 많은 수의 플레이어가 현실적으로 동의할 수 있는 유일한 값은 명백한 기본값인 진실입니다. 이것은 이론적으로 ETH/USD 가격, 베를린의 온도 또는 특정 어려운 연산의 결과를 포함하여 원하는 수의 값을 제공할 수 있는 탈중앙화된 프로토콜을 만듭니다.
4. 스마트 다중서명 에스크로. 비트코인은 예를 들어 주어진 5개의 키 중 3개가 자금을 사용할 수 있는 다중서명 트랜잭션 컨트랙트를 허용합니다. 이더리움은 더 세분화된 기능을 허용합니다. 예를 들어 5명 중 4명은 모든 것을 사용할 수 있고, 5명 중 3명은 하루에 최대 10%를 사용할 수 있으며, 5명 중 2명은 하루에 최대 0.5%를 사용할 수 있습니다. 또한 이더리움 다중서명은 비동기식입니다. 두 당사자가 서로 다른 시간에 블록체인에 서명을 등록할 수 있으며 마지막 서명이 자동으로 트랜잭션을 전송합니다.
5. 클라우드 컴퓨팅. EVM 기술은 검증 가능한 컴퓨팅 환경을 만드는 데에도 사용될 수 있습니다. 이를 통해 사용자는 다른 사람에게 연산을 수행하도록 요청한 다음 선택적으로 무작위로 선택된 특정 체크포인트에서 연산이 올바르게 수행되었는지에 대한 증명을 요청할 수 있습니다. 이를 통해 모든 사용자가 데스크톱, 노트북 또는 특수 서버로 참여할 수 있는 클라우드 컴퓨팅 시장을 만들 수 있으며, 보안 보증금과 함께 스팟 검사(spot-checking)를 사용하여 시스템을 신뢰할 수 있도록(즉, 노드가 수익성 있게 속일 수 없도록) 보장할 수 있습니다. 이러한 시스템이 모든 작업에 적합하지는 않을 수 있습니다. 예를 들어 높은 수준의 프로세스 간 통신이 필요한 작업은 대규모 노드 클라우드에서 쉽게 수행할 수 없습니다. 그러나 다른 작업은 병렬화하기가 훨씬 쉽습니다. SETI@home, folding@home 및 유전 알고리즘과 같은 프로젝트는 이러한 플랫폼 위에 쉽게 구현될 수 있습니다.
6. 피어 투 피어 도박. Frank Stajano와 Richard Clayton의 Cyberdice (새 탭에서 열림)와 같은 수많은 피어 투 피어 도박 프로토콜을 이더리움 블록체인에 구현할 수 있습니다. 가장 간단한 도박 프로토콜은 사실 단순히 다음 블록 해시에 대한 차액 결제 거래 컨트랙트이며, 거기에서 더 발전된 프로토콜을 구축하여 속일 수 없는 거의 제로에 가까운 수수료의 도박 서비스를 만들 수 있습니다.
7. 예측 시장. 오라클이나 SchellingCoin이 제공된다면 예측 시장도 쉽게 구현할 수 있으며, SchellingCoin과 함께 예측 시장은 탈중앙화된 조직을 위한 거버넌스 프로토콜로서 퓨타키(futarchy) (새 탭에서 열림)의 첫 번째 주류 애플리케이션이 될 수 있습니다.
8. 온체인 탈중앙화 마켓플레이스, 신원 및 평판 시스템을 기반으로 사용합니다.
기타 사항 및 우려 사항
수정된 GHOST 구현
"Greedy Heaviest Observed Subtree"(GHOST) 프로토콜은 요나탄 솜폴린스키(Yonatan Sompolinsky)와 아비브 조하르(Aviv Zohar)가 2013년 12월 (새 탭에서 열림)에 처음 도입한 혁신적인 기술입니다. GHOST의 도입 배경은 빠른 확정 시간을 가진 블록체인이 현재 높은 스테일(stale) 비율로 인해 보안성이 저하되는 문제를 겪고 있다는 점입니다. 블록이 네트워크를 통해 전파되는 데 일정 시간이 걸리기 때문에, 채굴자 A가 블록을 채굴한 후 A의 블록이 B에게 전파되기 전에 채굴자 B가 우연히 다른 블록을 채굴하게 되면, B의 블록은 결국 버려지게 되어 네트워크 보안에 기여하지 못하게 됩니다. 또한 중앙화 문제도 존재합니다. 채굴자 A가 30%의 해시파워를 가진 마이닝 풀이고 B가 10%의 해시파워를 가지고 있다면, A는 70%의 확률로 스테일 블록을 생성할 위험이 있는 반면(나머지 30%의 경우 A가 마지막 블록을 생성했으므로 즉시 채굴 데이터를 얻기 때문입니다), B는 90%의 확률로 스테일 블록을 생성할 위험이 있습니다. 따라서 스테일 비율이 높아질 정도로 블록 간격이 짧다면, A는 단순히 규모가 크다는 이유만으로 훨씬 더 높은 효율성을 갖게 됩니다. 이 두 가지 효과가 결합되면, 블록을 빠르게 생성하는 블록체인은 하나의 마이닝 풀이 네트워크 해시파워의 충분히 큰 비율을 차지하여 채굴 과정을 사실상 통제하게 될 가능성이 매우 높습니다.
솜폴린스키와 조하르가 설명한 바와 같이, GHOST는 어느 체인이 "가장 긴" 체인인지 계산할 때 스테일 블록을 포함시킴으로써 네트워크 보안 손실이라는 첫 번째 문제를 해결합니다. 즉, 블록의 부모와 그 이상의 조상뿐만 아니라, 블록 조상의 스테일 후손(이더리움 용어로는 "엉클(uncles)")까지도 어느 블록이 가장 큰 총 작업증명(PoW)의 뒷받침을 받는지 계산하는 데 추가됩니다. 중앙화 편향이라는 두 번째 문제를 해결하기 위해, 우리는 솜폴린스키와 조하르가 설명한 프로토콜을 넘어 스테일 블록에도 블록 보상을 제공합니다. 스테일 블록은 기본 보상의 87.5%를 받고, 스테일 블록을 포함하는 조카(nephew) 블록은 나머지 12.5%를 받습니다. 그러나 트랜잭션 수수료는 엉클 블록에 지급되지 않습니다.
이더리움은 7단계까지만 내려가는 단순화된 버전의 GHOST를 구현합니다. 구체적으로는 다음과 같이 정의됩니다.
- 블록은 하나의 부모를 지정해야 하며, 0개 이상의 엉클을 지정해야 합니다.
- 블록 B에 포함된 엉클은 다음 속성을 가져야 합니다.
- B의 k세대 조상의 직계 자식이어야 하며, 여기서
2 <= k <= 7입니다. - B의 조상일 수 없습니다.
- 엉클은 유효한 블록 헤더여야 하지만, 이전에 검증되었거나 유효한 블록일 필요는 없습니다.
- 엉클은 이전 블록에 포함된 모든 엉클 및 동일한 블록에 포함된 다른 모든 엉클과 달라야 합니다(이중 포함 불가).
- B의 k세대 조상의 직계 자식이어야 하며, 여기서
- 블록 B의 모든 엉클 U에 대해, B의 채굴자는 코인베이스 보상에 3.125%를 추가로 받고, U의 채굴자는 표준 코인베이스 보상의 93.75%를 받습니다.
최대 7세대까지만 엉클을 포함할 수 있는 이 제한된 버전의 GHOST가 사용된 데에는 두 가지 이유가 있습니다. 첫째, 무제한 GHOST는 특정 블록에 대해 어떤 엉클이 유효한지 계산하는 데 너무 많은 복잡성을 초래할 수 있습니다. 둘째, 이더리움에서 사용되는 보상이 포함된 무제한 GHOST는 채굴자가 공개적인 공격자의 체인이 아닌 메인 체인에서 채굴할 유인을 없애버립니다.
수수료
블록체인에 게시되는 모든 트랜잭션은 네트워크에 이를 다운로드하고 검증해야 하는 비용을 부과하므로, 남용을 방지하기 위해 일반적으로 트랜잭션 수수료를 포함하는 규제 메커니즘이 필요합니다. 비트코인에서 사용되는 기본 접근 방식은 전적으로 자발적인 수수료를 적용하여, 채굴자가 게이트키퍼 역할을 하고 동적인 최소값을 설정하도록 의존하는 것입니다. 이 접근 방식은 특히 "시장 기반"이어서 채굴자와 트랜잭션 발신자 간의 수요와 공급이 가격을 결정할 수 있다는 점 때문에 비트코인 커뮤니티에서 매우 긍정적인 평가를 받았습니다. 그러나 이러한 논리의 문제점은 트랜잭션 처리가 시장이 아니라는 것입니다. 트랜잭션 처리를 채굴자가 발신자에게 제공하는 서비스로 해석하는 것은 직관적으로 매력적이지만, 실제로는 채굴자가 포함하는 모든 트랜잭션이 네트워크의 모든 노드에 의해 처리되어야 하므로 트랜잭션 처리 비용의 대부분은 포함 여부를 결정하는 채굴자가 아니라 제3자가 부담하게 됩니다. 따라서 공유지의 비극 문제가 발생할 가능성이 매우 높습니다.
그러나 특정하게 부정확한 단순화 가정이 주어질 경우, 시장 기반 메커니즘의 이러한 결함이 마법처럼 상쇄된다는 사실이 밝혀졌습니다. 그 주장은 다음과 같습니다. 다음과 같이 가정해 보겠습니다.
- 트랜잭션은
k개의 연산을 유발하며, 이를 포함하는 모든 채굴자에게kR의 보상을 제공합니다. 여기서R는 발신자가 설정하며,k와R는 채굴자가 사전에 (대략적으로) 확인할 수 있습니다. - 하나의 연산은 모든 노드에 대해
C의 처리 비용을 가집니다(즉, 모든 노드의 효율성이 동일합니다). N개의 채굴 노드가 있으며, 각각 정확히 동일한 처리 능력을 가집니다(즉, 전체의1/N).- 채굴을 하지 않는 풀 노드는 존재하지 않습니다.
채굴자는 예상 보상이 비용보다 클 경우 트랜잭션을 기꺼이 처리할 것입니다. 따라서 채굴자가 다음 블록을 처리할 확률이 1/N이므로 예상 보상은 kR/N이며, 채굴자의 처리 비용은 단순히 kC입니다. 그러므로 채굴자는 kR/N > kC 또는 R > NC인 트랜잭션을 포함할 것입니다. 여기서 R는 발신자가 제공하는 연산당 수수료이므로 발신자가 트랜잭션에서 얻는 이익의 하한선이며, NC는 전체 네트워크가 연산을 처리하는 데 드는 총비용입니다. 따라서 채굴자는 총 공리적 이익이 비용을 초과하는 트랜잭션만 포함할 유인을 갖게 됩니다.
그러나 현실에서는 이러한 가정에서 벗어나는 몇 가지 중요한 차이가 있습니다.
- 추가적인 검증 시간이 블록 전파를 지연시켜 블록이 스테일이 될 확률을 높이기 때문에, 채굴자는 다른 검증 노드보다 트랜잭션을 처리하는 데 더 높은 비용을 지불합니다.
- 채굴을 하지 않는 풀 노드가 실제로 존재합니다.
- 실제로는 채굴 능력 분포가 극도로 불평등해질 수 있습니다.
- 네트워크에 해를 끼치는 것을 효용 함수로 삼는 투기꾼, 정치적 적대자, 광신도들이 존재하며, 이들은 자신의 비용이 다른 검증 노드가 지불하는 비용보다 훨씬 낮아지도록 교묘하게 컨트랙트를 설정할 수 있습니다.
(1)은 채굴자가 더 적은 트랜잭션을 포함하려는 경향을 제공하고,
(2)는 NC를 증가시킵니다. 따라서 이 두 가지 효과는 적어도 부분적으로 서로
상쇄됩니다.어떻게? (새 탭에서 열림)
(3)과 (4)가 주요 문제이며, 이를 해결하기 위해 우리는 단순히
유동적인 한도(floating cap)를 도입합니다. 즉, 어떤 블록도 장기 지수 이동 평균의
BLK_LIMIT_FACTOR배보다 많은 연산을 가질 수 없습니다.
구체적으로는 다음과 같습니다.
blk.oplimit = floor((blk.parent.oplimit \* (EMAFACTOR - 1) +
floor(parent.opcount \* BLK\_LIMIT\_FACTOR)) / EMA\_FACTOR)
BLK_LIMIT_FACTOR와 EMA_FACTOR는 당분간 65536과 1.5로 설정될 상수이지만, 추가 분석 후 변경될 가능성이 높습니다.
비트코인에서 큰 블록 크기를 억제하는 또 다른 요인이 있습니다. 크기가 큰 블록은 전파하는 데 더 오래 걸리므로 스테일이 될 확률이 더 높습니다. 이더리움에서도 가스 소비가 많은 블록은 물리적으로 더 크고 검증을 위한 트랜잭션 상태 전환을 처리하는 데 더 오래 걸리기 때문에 전파하는 데 더 오랜 시간이 걸릴 수 있습니다. 이러한 지연에 따른 억제책은 비트코인에서는 중요한 고려 사항이지만, 이더리움에서는 GHOST 프로토콜 덕분에 그 중요성이 덜합니다. 따라서 규제된 블록 한도에 의존하는 것이 더 안정적인 기준선을 제공합니다.
연산 및 튜링 완전성
중요한 점은 이더리움 가상 머신(EVM)이 튜링 완전하다는 것입니다. 이는 EVM 코드가 무한 루프를 포함하여 상상할 수 있는 모든 연산을 인코딩할 수 있음을 의미합니다. EVM 코드는 두 가지 방식으로 루프를 허용합니다. 첫째, 프로그램이 코드의 이전 위치로 되돌아갈 수 있게 해주는 JUMP 명령어와 조건부 점프를 수행하는 JUMPI 명령어가 있어 while x < 27: x = x * 2와 같은 구문을 사용할 수 있습니다. 둘째, 컨트랙트가 다른 컨트랙트를 호출할 수 있어 재귀를 통한 루프가 가능해질 수 있습니다. 이는 자연스럽게 한 가지 문제로 이어집니다. 악의적인 사용자가 채굴자와 풀 노드를 무한 루프에 빠지게 하여 사실상 시스템을 마비시킬 수 있을까요? 이 문제는 컴퓨터 과학에서 정지 문제(halting problem)로 알려진 문제 때문에 발생합니다. 일반적인 경우, 주어진 프로그램이 언젠가 멈출지 여부를 알 수 있는 방법은 없습니다.
상태 전환 섹션에서 설명한 바와 같이, 우리의 해결책은 트랜잭션이 허용되는 최대 연산 단계 수를 설정하도록 요구하는 방식으로 작동합니다. 실행이 더 오래 걸리면 연산은 되돌리기(revert)되지만 수수료는 여전히 지불됩니다. 메시지도 동일한 방식으로 작동합니다. 우리의 해결책 이면에 있는 동기를 보여주기 위해 다음 예시를 고려해 보겠습니다.
- 공격자가 무한 루프를 실행하는 컨트랙트를 생성한 다음, 해당 루프를 활성화하는 트랜잭션을 채굴자에게 보냅니다. 채굴자는 트랜잭션을 처리하여 무한 루프를 실행하고 가스가 소진될 때까지 기다립니다. 실행 중 가스가 소진되어 중간에 멈추더라도 트랜잭션은 여전히 유효하며, 채굴자는 각 연산 단계에 대해 공격자에게 수수료를 청구합니다.
- 공격자가 채굴자에게 매우 오랜 시간 동안 연산을 강제할 의도로 아주 긴 무한 루프를 생성합니다. 연산이 끝날 때쯤이면 이미 몇 개의 블록이 더 생성되어 채굴자가 수수료를 청구하기 위해 해당 트랜잭션을 포함하는 것이 불가능해지도록 만드는 것입니다. 그러나 공격자는 실행할 수 있는 연산 단계 수를 제한하는
STARTGAS값을 제출해야 하므로, 채굴자는 연산에 과도하게 많은 단계가 소요될 것임을 미리 알 수 있습니다. - 공격자가
send(A,contract.storage[A]); contract.storage[A] = 0와 같은 형태의 코드가 있는 컨트랙트를 발견하고, 첫 번째 단계는 실행하지만 두 번째 단계는 실행하지 못할 만큼(즉, 인출은 하지만 잔액은 줄어들지 않게 할 만큼) 딱 맞는 가스만 포함하여 트랜잭션을 보냅니다. 컨트랙트 작성자는 이러한 공격에 대한 방어를 걱정할 필요가 없습니다. 실행이 중간에 멈추면 변경 사항이 되돌려지기 때문입니다. - 금융 컨트랙트는 위험을 최소화하기 위해 9개의 독점 데이터 피드의 중앙값을 취하는 방식으로 작동합니다. 공격자가 DAO 섹션에서 설명한 가변 주소 호출(variable-address-call) 메커니즘을 통해 수정할 수 있도록 설계된 데이터 피드 중 하나를 장악하고, 이를 무한 루프가 실행되도록 변환하여 금융 컨트랙트에서 자금을 청구하려는 모든 시도가 가스 소진으로 실패하도록 강제하려 합니다. 그러나 금융 컨트랙트는 메시지에 가스 한도를 설정하여 이 문제를 방지할 수 있습니다.
튜링 완전성의 대안은 튜링 불완전성입니다. 여기서는 JUMP 및 JUMPI가 존재하지 않으며, 특정 시점에 호출 스택에 각 컨트랙트의 복사본이 하나만 존재하도록 허용됩니다. 이 시스템에서는 컨트랙트 실행 비용이 그 크기에 의해 상한이 정해지므로, 앞서 설명한 수수료 시스템과 우리 해결책의 효과에 대한 불확실성이 필요하지 않을 수 있습니다. 게다가 튜링 불완전성은 그렇게 큰 제약도 아닙니다. 우리가 내부적으로 구상한 모든 컨트랙트 예시 중 지금까지 단 하나만이 루프를 필요로 했으며, 그 루프조차도 한 줄짜리 코드를 26번 반복함으로써 제거할 수 있었습니다. 튜링 완전성의 심각한 영향과 제한적인 이점을 고려할 때, 왜 단순히 튜링 불완전한 언어를 사용하지 않는 것일까요? 그러나 현실적으로 튜링 불완전성은 문제에 대한 깔끔한 해결책과는 거리가 멉니다. 그 이유를 알아보기 위해 다음 컨트랙트들을 고려해 보겠습니다.
C0: call(C1); call(C1);
C1: call(C2); call(C2);
C2: call(C3); call(C3);
...
C49: call(C50); call(C50);
C50: (run one step of a program and record the change in storage)
이제 A에게 트랜잭션을 보냅니다. 따라서 51개의 트랜잭션만으로 250개의 연산 단계를 차지하는 컨트랙트가 만들어집니다. 채굴자들은 각 컨트랙트가 취할 수 있는 최대 연산 단계 수를 지정하는 값을 유지하고, 다른 컨트랙트를 재귀적으로 호출하는 컨트랙트에 대해 이를 계산함으로써 이러한 논리 폭탄을 사전에 탐지하려고 시도할 수 있습니다. 하지만 그렇게 하려면 채굴자들이 다른 컨트랙트를 생성하는 컨트랙트를 금지해야 합니다(위의 26개 컨트랙트의 생성 및 실행이 단일 컨트랙트로 쉽게 통합될 수 있기 때문입니다). 또 다른 문제점은 메시지의 주소 필드가 변수라는 것입니다. 따라서 일반적으로 특정 컨트랙트가 어떤 다른 컨트랙트를 호출할지 미리 아는 것조차 불가능할 수 있습니다. 결론적으로 우리는 놀라운 결론에 도달하게 됩니다. 튜링 완전성은 놀라울 정도로 관리하기 쉬우며, 튜링 불완전성은 정확히 동일한 제어 장치가 마련되어 있지 않는 한 관리하기가 똑같이 놀라울 정도로 어렵다는 것입니다. 그렇다면 차라리 프로토콜을 튜링 완전하게 두는 것이 낫지 않을까요?
통화 및 발행
이더리움 네트워크에는 자체 내장 통화인 이더(ether)가 포함되어 있습니다. 이더는 다양한 유형의 디지털 자산 간의 효율적인 교환을 허용하는 기본 유동성 계층을 제공하는 동시에, 더 중요하게는 트랜잭션 수수료를 지불하는 메커니즘을 제공하는 이중 목적을 수행합니다. 편의를 도모하고 향후 논쟁(비트코인의 현재 mBTC/uBTC/satoshi 논쟁 참조)을 피하기 위해, 단위 명칭은 미리 지정됩니다.
- 1: Wei
- 1012: 사보
- 1015: 피니
- 1018: 이더
이는 "달러"와 "센트" 또는 "BTC"와 "사토시" 개념의 확장된 버전으로 이해해야 합니다. 가까운 미래에 "이더"는 일반적인 트랜잭션에, "피니"는 소액 결제에, "사보"와 "Wei"는 수수료 및 프로토콜 구현과 관련된 기술적 논의에 사용될 것으로 예상합니다. 나머지 단위는 나중에 유용해질 수 있으며 현시점에서는 클라이언트에 포함되지 않아야 합니다.
발행 모델은 다음과 같습니다.
- 이더는 BTC당 1000~2000 이더의 가격으로 통화 판매를 통해 출시될 것입니다. 이는 이더리움 조직에 자금을 지원하고 개발 비용을 지불하기 위한 메커니즘으로, 마스터코인(Mastercoin)이나 NXT와 같은 다른 플랫폼에서 성공적으로 사용된 바 있습니다. 초기 구매자는 더 큰 할인 혜택을 받게 됩니다. 판매를 통해 받은 BTC는 전액 개발자에게 급여와 포상금을 지급하는 데 사용되며, 이더리움 및 암호화폐 생태계의 다양한 영리 및 비영리 프로젝트에 투자될 것입니다.
- 총 판매량의 0.099배(60,102,216 ETH)는 초기 기여자에게 보상하고 제네시스 블록 이전의 ETH 표시 비용을 지불하기 위해 조직에 할당됩니다.
- 총 판매량의 0.099배는 장기 준비금으로 유지됩니다.
- 그 이후로는 매년 총 판매량의 0.26배가 채굴자에게 영구적으로 할당됩니다.
| 그룹 | 출시 시점 | 1년 후 | 5년 후 |
|---|---|---|---|
| 통화 단위 | 1.198X | 1.458X | 2.498X |
| 구매자 | 83.5% | 68.6% | 40.0% |
| 사전 판매에 사용된 준비금 | 8.26% | 6.79% | 3.96% |
| 사후 판매에 사용된 준비금 | 8.26% | 6.79% | 3.96% |
| 채굴자 | 0% | 17.8% | 52.0% |
장기 공급 증가율(퍼센트)
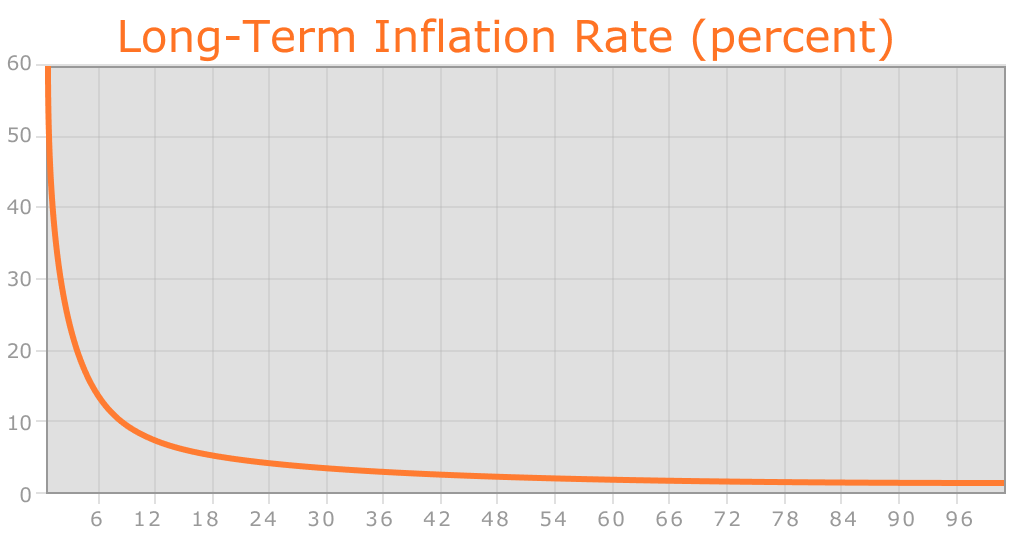
선형적인 통화 발행에도 불구하고, 비트코인과 마찬가지로 시간이 지남에 따라 공급 증가율은 결국 0에 수렴합니다.
위 모델에서 두 가지 주요 선택 사항은 (1) 기부금 풀(endowment pool)의 존재와 규모, (2) 비트코인처럼 상한이 있는 공급이 아니라 영구적으로 증가하는 선형 공급의 존재입니다. 기부금 풀의 정당성은 다음과 같습니다. 만약 기부금 풀이 존재하지 않고 동일한 인플레이션율을 제공하기 위해 선형 발행량이 0.217배로 줄어든다면, 이더의 총량은 16.5% 줄어들고 각 단위의 가치는 19.8% 더 높아질 것입니다. 따라서 균형 상태에서는 판매 시 19.8% 더 많은 이더가 구매될 것이므로, 각 단위는 다시 이전과 정확히 동일한 가치를 갖게 될 것입니다. 또한 조직은 1.198배 더 많은 BTC를 보유하게 되며, 이는 원래의 BTC와 추가적인 0.198배라는 두 부분으로 나뉘는 것으로 간주할 수 있습니다. 따라서 이 상황은 기부금과 정확히 동일하지만 한 가지 중요한 차이점이 있습니다. 조직이 순수하게 BTC만 보유하게 되므로 이더 단위의 가치를 지지할 유인이 없다는 것입니다.
영구적인 선형 공급 증가 모델은 일부에서 비트코인의 과도한 부의 집중이라고 보는 위험을 줄여주며, 현재와 미래 시대에 사는 개인들에게 통화 단위를 획득할 공정한 기회를 제공합니다. 동시에 백분율로 나타낸 "공급 증가율"은 시간이 지남에 따라 여전히 0에 수렴하기 때문에 이더를 획득하고 보유할 강력한 유인을 유지합니다. 또한 부주의, 사망 등으로 인해 시간이 지남에 따라 코인은 항상 유실되며, 코인 유실은 연간 총공급량의 일정 비율로 모델링할 수 있습니다. 따라서 유통되는 총 통화 공급량은 결국 연간 발행량을 유실률로 나눈 값에서 안정화될 것이라고 이론화합니다(예: 유실률이 1%일 때 공급량이 26X에 도달하면 매년 0.26X가 채굴되고 0.26X가 유실되어 균형을 이룹니다).
향후 이더리움은 보안을 위해 지분 증명(PoS) 모델로 전환할 가능성이 높으며, 이 경우 발행 요구량이 연간 0에서 0.05X 사이로 줄어들게 됩니다. 이더리움 조직이 자금을 잃거나 다른 이유로 사라질 경우를 대비하여, 우리는 "사회적 계약"을 열어둡니다. 누구든 미래의 이더리움 후보 버전을 만들 권리가 있으며, 유일한 조건은 이더의 수량이 최대 60102216 * (1.198 + 0.26 * n) 이하여야 한다는 것입니다. 여기서 n는 제네시스 블록 이후의 연수입니다. 제작자는 개발 비용을 지불하기 위해 PoS 기반 공급 확장과 최대 허용 공급 확장 간의 차이 중 일부 또는 전부를 크라우드 세일하거나 다른 방식으로 할당할 수 있습니다. 사회적 계약을 준수하지 않는 후보 업그레이드는 정당하게 규정을 준수하는 버전으로 포크될 수 있습니다.
채굴 중앙화
비트코인 채굴 알고리즘은 채굴자들이 약간 수정된 버전의 블록 헤더에 대해 SHA256을 수백만 번 반복해서 계산하도록 하여, 마침내 한 노드가 목표값(현재 약 2192)보다 작은 해시를 가진 버전을 찾아내는 방식으로 작동합니다. 그러나 이 채굴 알고리즘은 두 가지 형태의 중앙화에 취약합니다. 첫째, 채굴 생태계는 비트코인 채굴이라는 특정 작업에 맞게 설계되어 수천 배 더 효율적인 컴퓨터 칩인 ASIC(주문형 반도체)에 의해 지배되고 있습니다. 이는 비트코인 채굴이 더 이상 고도로 탈중앙화되고 평등한 활동이 아니며, 효과적으로 참여하려면 수백만 달러의 자본이 필요함을 의미합니다. 둘째, 대부분의 비트코인 채굴자는 실제로 로컬에서 블록 검증을 수행하지 않습니다. 대신 중앙화된 마이닝 풀에 의존하여 블록 헤더를 제공받습니다. 이 문제는 틀림없이 더 심각합니다. 이 글을 쓰는 시점을 기준으로 상위 3개 마이닝 풀이 비트코인 네트워크 처리 능력의 약 50%를 간접적으로 통제하고 있습니다. 비록 풀이나 연합이 51% 공격을 시도할 경우 채굴자들이 다른 마이닝 풀로 전환할 수 있다는 사실로 인해 완화되기는 하지만 말입니다.
이더리움의 현재 의도는 채굴자가 상태에서 무작위 데이터를 가져오고, 블록체인의 마지막 N개 블록에서 무작위로 선택된 일부 트랜잭션을 계산한 다음, 그 결과의 해시를 반환하도록 요구하는 채굴 알고리즘을 사용하는 것입니다. 여기에는 두 가지 중요한 이점이 있습니다. 첫째, 이더리움 컨트랙트는 모든 종류의 연산을 포함할 수 있으므로, 이더리움 ASIC은 본질적으로 일반 연산을 위한 ASIC, 즉 더 나은 CPU가 될 것입니다. 둘째, 채굴에는 전체 블록체인에 대한 접근이 필요하므로 채굴자는 전체 블록체인을 저장하고 최소한 모든 트랜잭션을 검증할 수 있어야 합니다. 이는 중앙화된 마이닝 풀의 필요성을 제거합니다. 마이닝 풀이 보상 분배의 무작위성을 고르게 하는 정당한 역할을 계속 수행할 수는 있지만, 이 기능은 중앙 통제가 없는 피어 투 피어 풀에서도 똑같이 잘 수행될 수 있습니다.
이 모델은 아직 검증되지 않았으며, 컨트랙트 실행을 채굴 알고리즘으로 사용할 때 특정 교묘한 최적화를 피하는 과정에서 어려움이 있을 수 있습니다. 그러나 이 알고리즘의 특히 흥미로운 특징 중 하나는 특정 ASIC을 방해하기 위해 특별히 설계된 다수의 컨트랙트를 블록체인에 도입함으로써 누구나 "우물에 독을 풀 수(poison the well)" 있다는 점입니다. ASIC 제조업체들이 서로를 공격하기 위해 이러한 속임수를 사용할 경제적 유인이 존재합니다. 따라서 우리가 개발 중인 해결책은 궁극적으로 순수한 기술적 해결책이라기보다는 적응형 경제적 인간 해결책입니다.
확장성
이더리움에 대한 일반적인 우려 중 하나는 확장성 문제입니다. 비트코인과 마찬가지로 이더리움도 모든 트랜잭션이 네트워크의 모든 노드에 의해 처리되어야 한다는 결함을 안고 있습니다. 비트코인의 경우 현재 블록체인 크기는 약 15GB이며 시간당 약 1MB씩 증가하고 있습니다. 만약 비트코인 네트워크가 Visa의 초당 2000건의 트랜잭션을 처리한다면, 3초당 1MB(시간당 1GB, 연간 8TB)씩 증가할 것입니다. 이더리움도 비슷한 성장 패턴을 겪을 가능성이 높습니다. 비트코인처럼 단순한 통화가 아니라 이더리움 블록체인 위에 많은 애플리케이션이 존재할 것이라는 사실 때문에 상황이 더 악화될 수 있지만, 이더리움 풀 노드는 전체 블록체인 기록 대신 상태만 저장하면 된다는 사실로 인해 완화됩니다.
이렇게 큰 블록체인 크기의 문제는 중앙화 위험입니다. 블록체인 크기가 예를 들어 100TB로 증가한다면, 극소수의 대기업만이 풀 노드를 운영하고 모든 일반 사용자는 라이트 SPV 노드를 사용하는 시나리오가 유력해집니다. 이러한 상황에서는 풀 노드들이 담합하여 수익성 있는 방식(예: 블록 보상 변경, 자신들에게 BTC 지급)으로 속이기로 합의할 수 있다는 잠재적인 우려가 발생합니다. 라이트 노드는 이를 즉시 감지할 방법이 없습니다. 물론 최소한 하나의 정직한 풀 노드가 존재할 가능성이 높으며, 몇 시간 후 레딧(Reddit)과 같은 채널을 통해 사기에 대한 정보가 흘러나오겠지만, 그때는 이미 너무 늦었을 것입니다. 해당 블록을 블랙리스트에 올리기 위한 노력을 조직하는 것은 일반 사용자의 몫이 되며, 이는 성공적인 51% 공격을 수행하는 것과 비슷한 규모의 거대하고 실현 불가능할 가능성이 높은 조정 문제입니다. 비트코인의 경우 현재 이것이 문제이지만, 피터 토드(Peter Todd)가 제안한 (새 탭에서 열림) 블록체인 수정안이 이 문제를 완화할 것입니다.
단기적으로 이더리움은 이 문제에 대처하기 위해 두 가지 추가 전략을 사용할 것입니다. 첫째, 블록체인 기반 채굴 알고리즘으로 인해 최소한 모든 채굴자는 풀 노드가 되어야 하므로 풀 노드 수의 하한선이 생성됩니다. 그러나 두 번째이자 더 중요한 것은, 각 트랜잭션을 처리한 후 블록체인에 중간 상태 트리 루트를 포함시킬 것이라는 점입니다. 블록 검증이 중앙화되더라도 정직한 검증 노드가 하나라도 존재하는 한, 검증 프로토콜을 통해 중앙화 문제를 우회할 수 있습니다. 채굴자가 유효하지 않은 블록을 게시하는 경우, 해당 블록은 형식이 잘못되었거나 상태 S[n]가 올바르지 않아야 합니다. S[0]가 올바른 것으로 알려져 있으므로, S[i-1]는 올바르지만 잘못된 첫 번째 상태 S[i]가 존재해야 합니다. 검증 노드는 인덱스 i와 함께 APPLY(S[i-1],TX[i]) -> S[i]를 처리하는 데 필요한 패트리샤 트리 노드의 하위 집합으로 구성된 "무효성 증명(proof of invalidity)"을 제공할 것입니다. 노드들은 해당 노드들을 사용하여 연산의 그 부분을 실행하고, 생성된 S[i]가 제공된 S[i]와 일치하지 않음을 확인할 수 있습니다.
또 다른 더 정교한 공격은 악의적인 채굴자가 불완전한 블록을 게시하여 블록의 유효성 여부를 판단할 전체 정보조차 존재하지 않게 만드는 것입니다. 이에 대한 해결책은 챌린지-응답(challenge-response) 프로토콜입니다. 검증 노드는 대상 트랜잭션 인덱스 형태로 "챌린지"를 발행하고, 이를 수신한 라이트 노드는 채굴자이든 다른 검증자이든 다른 노드가 유효성 증명으로 패트리샤 노드의 하위 집합을 제공할 때까지 해당 블록을 신뢰할 수 없는 것으로 취급합니다.
결론
이더리움 프로토콜은 원래 암호화폐의 업그레이드 버전으로 고안되었으며, 고도로 일반화된 프로그래밍 언어를 통해 블록체인 상의 에스크로, 인출 한도, 금융 컨트랙트, 도박 시장 등과 같은 고급 기능을 제공합니다. 이더리움 프로토콜은 어떤 애플리케이션도 직접 "지원"하지는 않지만, 튜링 완전한 프로그래밍 언어의 존재는 이론적으로 모든 트랜잭션 유형이나 애플리케이션에 대해 임의의 컨트랙트를 생성할 수 있음을 의미합니다. 그러나 이더리움에서 더 흥미로운 점은 이더리움 프로토콜이 단순한 통화를 훨씬 넘어선다는 것입니다. 탈중앙화된 파일 스토리지, 탈중앙화된 컴퓨팅, 탈중앙화된 예측 시장을 비롯한 수십 가지 다른 개념을 둘러싼 프로토콜은 컴퓨팅 산업의 효율성을 크게 높일 수 있는 잠재력을 가지고 있으며, 최초로 경제적 계층을 추가하여 다른 피어 투 피어 프로토콜에 엄청난 활력을 불어넣을 수 있습니다. 마지막으로, 돈과 전혀 관련이 없는 상당수의 애플리케이션도 존재합니다.
이더리움 프로토콜에 의해 구현된 임의의 상태 변환 함수라는 개념은 고유한 잠재력을 가진 플랫폼을 제공합니다. 데이터 스토리지, 도박 또는 금융 분야의 특정 애플리케이션을 위해 의도된 폐쇄적이고 단일 목적의 프로토콜이 아니라, 이더리움은 설계상 개방형이며, 향후 수년 동안 수많은 금융 및 비금융 프로토콜의 기반 계층 역할을 하기에 매우 적합하다고 믿습니다.
주석 및 추가 자료
주석
- 숙련된 독자라면 비트코인 주소가 사실 공개키 자체가 아니라 타원 곡선 공개키의 해시라는 점을 눈치챘을 것입니다. 하지만 공개키 해시를 공개키 자체로 부르는 것은 사실 암호학적으로 완벽하게 타당한 용어 사용입니다. 이는 비트코인의 암호학이 맞춤형 디지털 서명 알고리즘으로 간주될 수 있기 때문입니다. 이 알고리즘에서 공개키는 ECC 공개키의 해시로 구성되고, 서명은 ECC 서명과 연결된 ECC 공개키로 구성되며, 검증 알고리즘은 서명에 있는 ECC 공개키를 공개키로 제공된 ECC 공개키 해시와 대조하여 확인한 다음 ECC 공개키에 대해 ECC 서명을 검증하는 과정을 포함합니다.
- 엄밀히 말하면, 이전 11개 블록의 중앙값입니다.
- 내부적으로 2와 "CHARLIE"는 모두 숫자이며, 후자는 빅 엔디언 256진법으로 표현됩니다. 숫자는 최소 0에서 최대 2256-1까지 가능합니다.
추가 자료
- 내재 가치 (새 탭에서 열림)
- 스마트 자산 (새 탭에서 열림)
- 스마트 컨트랙트 (새 탭에서 열림)
- B-money (새 탭에서 열림)
- 재사용 가능한 작업증명 (새 탭에서 열림)
- 소유자 권한이 있는 안전한 재산권 (새 탭에서 열림)
- 비트코인 백서 (새 탭에서 열림)
- Namecoin (새 탭에서 열림)
- 주코의 삼각형 (새 탭에서 열림)
- 컬러드 코인 백서 (새 탭에서 열림)
- 마스터코인 백서 (새 탭에서 열림)
- 탈중앙화된 자율 기업, 비트코인 매거진 (새 탭에서 열림)
- 단순 지불 검증 (새 탭에서 열림)
- 머클 트리 (새 탭에서 열림)
- 패트리샤 트리 (새 탭에서 열림)
- GHOST (새 탭에서 열림)
- StorJ와 자율 에이전트, 제프 가직(Jeff Garzik) (새 탭에서 열림)
- 튜링 페스티벌에서의 마이크 헌(Mike Hearn)의 스마트 자산 강연 (새 탭에서 열림)
- 이더리움 RLP
- 이더리움 머클 패트리샤 트리
- 피터 토드의 머클 합 트리 (새 탭에서 열림)
백서의 역사에 대해서는 이 위키 (새 탭에서 열림)를 참조하세요.
이더리움은 다른 많은 커뮤니티 주도 오픈 소스 소프트웨어 프로젝트와 마찬가지로 초기 구상 이후 계속 발전해 왔습니다. 이더리움의 최신 개발 현황과 프로토콜 변경 방식에 대해 알아보려면 이 가이드를 읽어보시길 권장합니다.