PeerDAS
Протокол Ethereum претерпевает самый значительный апгрейд масштабирования с момента введения транзакций с блобами в рамках EIP-4844. В рамках апгрейда Fusaka PeerDAS представляет новый способ обработки данных блобов, обеспечивая увеличение емкости доступности данных (DA) для L2 примерно на порядок.
Подробнее о дорожной карте масштабирования блобов (opens in a new tab)
Масштабируемость
Видение Ethereum — быть нейтральной, безопасной и децентрализованной платформой, доступной для всех в мире. По мере роста использования сети требуется находить баланс между масштабируемостью, безопасностью и децентрализацией сети. Если бы Ethereum просто увеличил объем обрабатываемых данных в рамках текущей архитектуры, возник бы риск перегрузки узлов, на которые Ethereum полагается для обеспечения своей децентрализации. Масштабируемость требует разработки строгих механизмов, которые минимизируют компромиссы.
Одна из стратегий для достижения этой цели — создание разнообразной экосистемы решений для масштабирования уровня 2, вместо обработки всех транзакций в основной сети . или свертки обрабатывают транзакции в своих отдельных цепочках и используют Ethereum для верификации и обеспечения безопасности. Публикация только критически важных для безопасности обязательств и сжатие полезных данных позволяет L2 более эффективно использовать емкость доступности данных Ethereum. В свою очередь, L1 переносит меньше данных без ущерба для гарантий безопасности, в то время как L2 привлекают больше пользователей при меньших затратах на газ. Изначально L2 публиковали данные как calldata в обычных транзакциях, что конкурировало с транзакциями L1 за газ и было непрактично для массовой доступности данных.
Протоданкшардинг
Первым важным шагом к масштабированию L2 стал апгрейд Dencun, который представил Proto-Danksharding (EIP-4844). Этот апгрейд создал новый, специализированный тип данных для сверток, называемый блобами. Блобы, или большие двоичные объекты, — это эфемерные фрагменты произвольных данных, которые не требуют исполнения в EVM и хранятся узлами только в течение ограниченного времени. Эта более эффективная обработка позволила L2 публиковать больше данных в Ethereum и еще больше масштабироваться.
Несмотря на уже имеющиеся значительные преимущества для масштабирования, использование блобов является лишь частью конечной цели. В текущем протоколе каждый узел в сети по-прежнему должен загружать каждый блоб. Узким местом становится пропускная способность, требуемая от отдельных узлов, при этом объем данных, которые необходимо загрузить, напрямую увеличивается с ростом числа блобов.
Ethereum не идет на компромиссы в вопросах децентрализации, а пропускная способность является одним из самых чувствительных параметров. Даже при широкой доступности мощных вычислительных ресурсов для всех, кто может себе это позволить, ограничения пропускной способности на выгрузку (opens in a new tab) даже в крупных городах развитых стран (таких как Германия (opens in a new tab), Бельгия (opens in a new tab), Австралия (opens in a new tab) или Соединенные Штаты (opens in a new tab)) могут привести к тому, что узлы можно будет запускать только из центров обработки данных, если требования к пропускной способности не будут тщательно настроены.
По мере увеличения количества блобов у операторов узлов возрастают требования к пропускной способности и дисковому пространству. Размер и количество блобов ограничены этими условиями. Каждый блоб может нести до 128 КБ данных, в среднем 6 блобов на блок. Это был лишь первый шаг к будущей архитектуре, которая использует блобы еще более эффективно.
Выборка доступности данных (DAS)
Доступность данных — это гарантия того, что все данные, необходимые для независимой проверки цепи, доступны всем участникам сети. Она гарантирует, что данные были полностью опубликованы и могут быть использованы для бездоверительной проверки нового состояния цепи или входящих транзакций.
Блобы Ethereum обеспечивают надежную гарантию доступности данных, что обеспечивает безопасность L2. Для этого узлам Ethereum необходимо загружать и хранить блобы целиком. Но что, если мы сможем более эффективно распределять блобы в сети и избежать этого ограничения?
Другой подход к хранению данных и обеспечению их доступности — это выборка доступности данных (DAS). Вместо того чтобы каждый компьютер, на котором запущен Ethereum, полностью хранил каждый блоб, DAS вводит децентрализованное разделение труда. Это снижает нагрузку по обработке данных за счет распределения более мелких и управляемых задач по всей сети узлов. Блобы делятся на части, и каждый узел загружает только несколько частей, используя механизм равномерного случайного распределения по всем узлам.
Это создает новую проблему — доказательство доступности и целостности данных. Как сеть может гарантировать, что данные доступны и все они верны, если отдельные узлы хранят только небольшие фрагменты? Злонамеренный узел может предоставлять поддельные данные и легко нарушить надежные гарантии доступности данных! Здесь на помощь приходит криптография.
Для обеспечения целостности данных EIP-4844 уже был реализован с обязательствами KZG. Это криптографические доказательства, создаваемые при добавлении нового блоба в сеть. Небольшое доказательство включается в каждый блок, и узлы могут проверить, соответствуют ли полученные блобы обязательству KZG блока.
DAS — это механизм, который строится на основе этого и гарантирует, что данные являются как верными, так и доступными. Выборка — это процесс, при котором узел запрашивает только небольшую часть данных и проверяет ее на соответствие обязательству. KZG — это схема полиномиальных обязательств, что означает, что любая отдельная точка на полиномиальной кривой может быть проверена. Проверив всего пару точек на полиноме, клиент, выполняющий выборку, может получить надежную вероятностную гарантию того, что данные доступны.
PeerDAS
PeerDAS (EIP-7594) (opens in a new tab) — это конкретное предложение, реализующее механизм DAS в Ethereum, которое, вероятно, является крупнейшим апгрейдом со времен Слияния. PeerDAS предназначен для расширения данных блобов путем их разделения на столбцы и распределения подмножеств по узлам.
Для достижения этого Ethereum заимствует некоторые умные математические приемы: он применяет к данным блобов стирающее кодирование в стиле Рида-Соломона. Данные блоба представляются в виде полинома, коэффициенты которого кодируют данные, затем этот полином вычисляется в дополнительных точках для создания расширенного блоба, удваивая количество вычислений. Эта добавленная избыточность обеспечивает восстановление после стирания: даже если некоторые вычисления отсутствуют, исходный блоб может быть восстановлен, если доступна хотя бы половина всех данных, включая расширенные части.
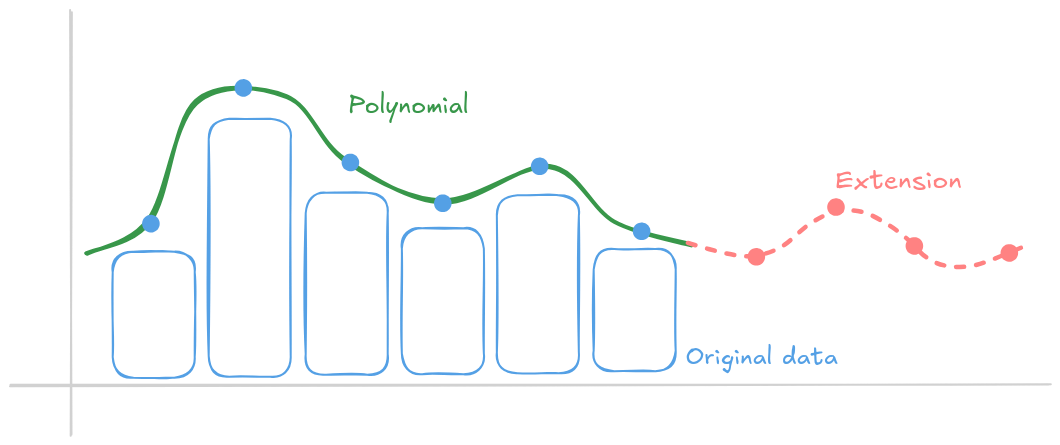
В действительности этот полином имеет тысячи коэффициентов. Обязательства KZG — это значения размером в несколько байт, что-то вроде хэша, известные всем узлам. Каждый узел, хранящий достаточное количество точек данных, может эффективно восстановить полный набор данных блоба (opens in a new tab).
Интересный факт: та же техника кодирования использовалась в DVD. Если вы поцарапали DVD, проигрыватель все равно мог его прочитать благодаря кодированию Рида-Соломона, которое добавляет недостающие части полинома.
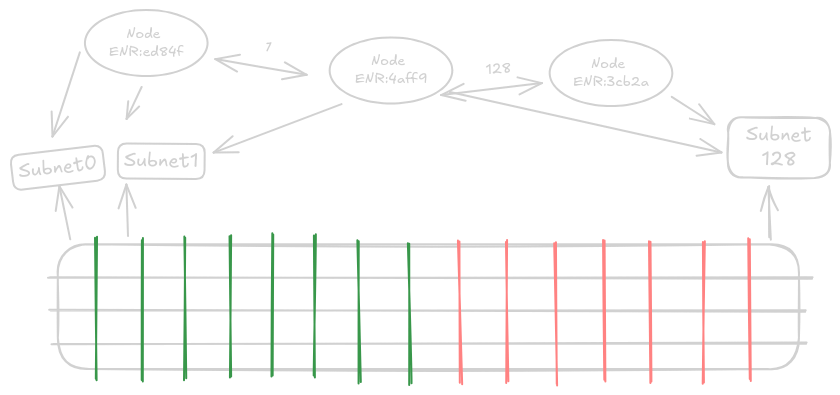
Исторически данные в блокчейнах, будь то блоки или блобы, транслировались всем узлам. С подходом PeerDAS, основанным на разделении и выборке, трансляция всего всем больше не требуется. После Fusaka сетевое взаимодействие на уровне консенсуса организовано в темы/подсети gossip: столбцы блобов назначаются определенным подсетям, и каждый узел подписывается на предопределенные подмножества и хранит только эти части.
В PeerDAS расширенные данные блобов делятся на 128 частей, называемых столбцами. Данные распределяются по этим узлам через специальный протокол gossip в определенных подсетях, на которые они подписаны. Каждый обычный узел в сети участвует как минимум в 8 случайно выбранных подсетях столбцов. Получение данных только из 8 из 128 подсетей означает, что этот узел по умолчанию получает только 1/16 всех данных, но поскольку данные были расширены, это составляет 1/8 от исходных данных.
Это позволяет достичь нового теоретического предела масштабирования, в 8 раз превышающего текущую схему «каждый загружает все». Когда узлы подписываются на разные случайные подсети, обслуживающие столбцы блобов, вероятность того, что они равномерно распределены, очень высока, и, следовательно, каждый фрагмент данных существует где-то в сети. Узлы, запускающие валидаторов, обязаны подписываться на большее количество подсетей с каждым запущенным валидатором.
Каждый узел имеет уникальный случайно сгенерированный идентификатор, который обычно служит его публичной идентификацией для соединений. В PeerDAS это число используется для определения случайного набора подсетей, на которые он должен подписаться, что приводит к равномерному случайному распределению всех данных блобов.
Как только узел успешно восстанавливает исходные данные, он перераспределяет восстановленные столбцы обратно в сеть, активно устраняя любые пробелы в данных и повышая общую отказоустойчивость системы. Узлы, подключенные к валидаторам с общим балансом ≥4096 ETH, должны быть суперузлами и, следовательно, должны подписываться на все подсети столбцов данных и хранить все столбцы. Эти суперузлы будут постоянно устранять пробелы в данных. Вероятностная самовосстанавливающаяся природа протокола позволяет предоставлять надежные гарантии доступности, не ограничивая домашних операторов, хранящих лишь части данных.
Доступность данных может быть подтверждена любым узлом, хранящим лишь небольшое подмножество данных блоба, благодаря описанному выше механизму выборки. Эта доступность обеспечивается принудительно: валидаторы должны следовать новым правилам выбора форка, что означает, что они будут принимать блоки и голосовать за них только после проверки доступности данных.
Прямое влияние на пользователей (особенно на пользователей L2) — это снижение комиссий. С увеличением пространства для данных сверток в 8 раз операции пользователей в их цепи со временем становятся еще дешевле. Но снижение комиссий после Fusaka займет время и будет зависеть от BPO.
Форки только для параметров блобов (BPO)
Теоретически сеть сможет обрабатывать в 8 раз больше блобов, но увеличение количества блобов — это изменение, которое необходимо тщательно протестировать и безопасно выполнять поэтапно. Тестовые сети дают достаточную уверенность для развертывания функций в основной сети, но нам необходимо обеспечить стабильность p2p-сети, прежде чем включать значительно большее количество блобов.
Чтобы постепенно увеличивать целевое количество блобов на блок, не перегружая сеть, Fusaka вводит форки только для параметров блобов (BPO) (opens in a new tab). В отличие от обычных форков, которые требуют широкой координации экосистемы, согласия и обновлений программного обеспечения, BPO (EIP-7892) (opens in a new tab) — это предварительно запрограммированные апгрейды, которые со временем увеличивают максимальное количество блобов без вмешательства.
Это означает, что сразу после активации Fusaka и запуска PeerDAS количество блобов останется неизменным. Количество блобов начнет удваиваться каждые несколько недель, пока не достигнет максимума в 48, в то время как разработчики будут следить за тем, чтобы механизм работал, как ожидалось, и не оказывал негативного влияния на узлы, работающие в сети.
Будущие направления
PeerDAS — это лишь шаг на пути к более масштабному видению масштабирования FullDAS (opens in a new tab), или Danksharding. В то время как PeerDAS использует 1D-стирающее кодирование для каждого блоба индивидуально, полный Danksharding будет использовать более полную 2D-схему стирающего кодирования по всей матрице данных блобов. Расширение данных в двух измерениях создает еще более сильные свойства избыточности и более эффективное восстановление и проверку. Реализация FullDAS потребует значительных оптимизаций сети и протокола, а также дополнительных исследований.
Дополнительные материалы
- PeerDAS: выборка доступности одноранговых данных, Франческо Д'Амато (opens in a new tab)
- Документация по PeerDAS от Ethereum (opens in a new tab)
- Доказательство безопасности PeerDAS без AGM (opens in a new tab)
- Виталик о PeerDAS, его влиянии и тестировании Fusaka (opens in a new tab)
Последнее обновление страницы: 23 февраля 2026 г.


