آف لائن ڈیٹا کی سالمیت کے لیے مرکل ثبوت
تعارف
مثالی طور پر ہم ہر چیز کو ایتھیریم اسٹوریج میں محفوظ کرنا چاہیں گے، جو ہزاروں کمپیوٹرز پر محفوظ ہوتا ہے اور اس کی دستیابی انتہائی زیادہ ہوتی ہے (ڈیٹا کو سنسر نہیں کیا جا سکتا) اور سالمیت (ڈیٹا کو غیر مجاز طریقے سے تبدیل نہیں کیا جا سکتا)، لیکن ایک 32-byte ورڈ کو اسٹور کرنے پر عام طور پر 20,000 گیس خرچ ہوتی ہے۔ جب میں یہ لکھ رہا ہوں، تو یہ لاگت $6.60 کے برابر ہے۔ 21 cents فی بائٹ کے حساب سے یہ بہت سے استعمالات کے لیے بہت مہنگا ہے۔
اس مسئلے کو حل کرنے کے لیے ایتھیریم ایکو سسٹم نے لامركزی انداز میں ڈیٹا اسٹور کرنے کے کئی متبادل طریقے تیار کیے ہیں۔ عام طور پر ان میں دستیابی اور قیمت کے درمیان سمجھوتہ شامل ہوتا ہے۔ تاہم، سالمیت کی عام طور پر یقین دہانی کرائی جاتی ہے۔
اس مضمون میں آپ سیکھیں گے کہ بلاک چین پر ڈیٹا اسٹور کیے بغیر، مرکل ثبوت (opens in a new tab) کا استعمال کرتے ہوئے ڈیٹا کی سالمیت کو کیسے یقینی بنایا جائے۔
یہ کیسے کام کرتا ہے؟
نظریاتی طور پر ہم صرف ڈیٹا کا ہیش آن چین اسٹور کر سکتے ہیں، اور وہ تمام ڈیٹا ان ٹرانزیکشنز میں بھیج سکتے ہیں جنہیں اس کا تقاضا ہوتا ہے۔ تاہم، یہ اب بھی بہت مہنگا ہے۔ ٹرانزیکشن میں ایک بائٹ ڈیٹا کی لاگت تقریباً 16 گیس ہوتی ہے، جو فی الحال تقریباً آدھا سینٹ، یا تقریباً $5 فی کلو بائٹ ہے۔ $5000 فی میگا بائٹ کے حساب سے، یہ اب بھی بہت سے استعمالات کے لیے بہت مہنگا ہے، یہاں تک کہ ڈیٹا کی ہیشنگ کی اضافی لاگت کے بغیر بھی۔
اس کا حل یہ ہے کہ ڈیٹا کے مختلف ذیلی حصوں کو بار بار ہیش کیا جائے، تاکہ جس ڈیٹا کو آپ کو بھیجنے کی ضرورت نہیں ہے اس کے لیے آپ صرف ایک ہیش بھیج سکیں۔ آپ یہ ایک مرکل ٹری کا استعمال کرتے ہوئے کرتے ہیں، جو ایک ٹری ڈیٹا اسٹرکچر ہے جہاں ہر نوڈ اپنے نیچے والے نوڈز کا ہیش ہوتا ہے:
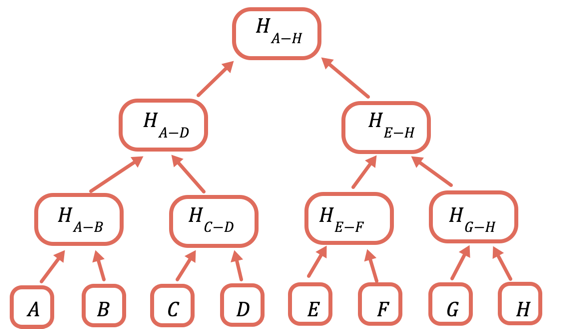
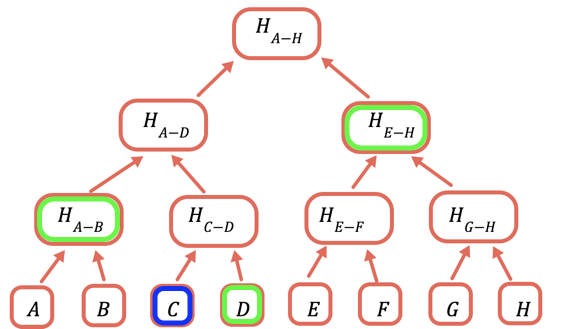
روٹ ہیش وہ واحد حصہ ہے جسے آن چین اسٹور کرنے کی ضرورت ہوتی ہے۔ کسی خاص قدر کو ثابت کرنے کے لیے، آپ وہ تمام ہیشز فراہم کرتے ہیں جنہیں روٹ حاصل کرنے کے لیے اس کے ساتھ ملانے کی ضرورت ہوتی ہے۔ مثال کے طور پر، C کو ثابت کرنے کے لیے آپ D، H(A-B)، اور H(E-H) فراہم کرتے ہیں۔
نفاذ
نمونہ کوڈ یہاں فراہم کیا گیا ہے (opens in a new tab)۔
آف چین کوڈ
اس مضمون میں ہم آف چین حسابات کے لیے JavaScript کا استعمال کرتے ہیں۔ زیادہ تر لامركزی ایپلی کیشنز کا آف چین جزو JavaScript میں ہوتا ہے۔
مرکل روٹ بنانا
سب سے پہلے ہمیں چین کو مرکل روٹ فراہم کرنے کی ضرورت ہے۔
const ethers = require("ethers")
ہم ethers پیکیج سے ہیش فنکشن استعمال کرتے ہیں (opens in a new tab)۔
// وہ خام ڈیٹا جس کی سالمیت کی ہمیں تصدیق کرنی ہے۔ پہلے دو بائٹس
// ایک صارف شناخت کنندہ ہیں، اور آخری دو بائٹس ٹوکنز کی وہ مقدار ہیں جو
// اس وقت صارف کی ملکیت میں ہیں۔
const dataArray = [
0x0bad0010, 0x60a70020, 0xbeef0030, 0xdead0040, 0xca110050, 0x0e660060,
0xface0070, 0xbad00080, 0x060d0091,
]
ہر اندراج کو ایک واحد 256-bit انٹیجر میں انکوڈ کرنے کے نتیجے میں، مثال کے طور پر، JSON استعمال کرنے کی نسبت کم پڑھنے کے قابل کوڈ بنتا ہے۔ تاہم، اس کا مطلب یہ ہے کہ کنٹریکٹ میں ڈیٹا بازیافت کرنے کے لیے نمایاں طور پر کم پروسیسنگ درکار ہوتی ہے، اس لیے گیس کی لاگت بہت کم ہوتی ہے۔ آپ آن چین JSON پڑھ سکتے ہیں (opens in a new tab)، اگر اس سے بچا جا سکے تو یہ محض ایک برا خیال ہے۔
// ہیش ویلیوز کی ایرے، BigInts کے طور پر
const hashArray = dataArray
اس صورت میں ہمارا ڈیٹا شروع سے ہی 256-bit ویلیوز پر مشتمل ہے، اس لیے کسی پروسیسنگ کی ضرورت نہیں ہے۔ اگر ہم زیادہ پیچیدہ ڈیٹا اسٹرکچر استعمال کرتے ہیں، جیسے کہ اسٹرنگز، تو ہمیں یہ یقینی بنانا ہوگا کہ ہم ہیشز کی ایک سرنی (array) حاصل کرنے کے لیے پہلے ڈیٹا کو ہیش کریں۔ نوٹ کریں کہ یہ اس لیے بھی ہے کیونکہ ہمیں اس بات کی پرواہ نہیں ہے کہ آیا صارفین دوسرے صارفین کی معلومات جانتے ہیں۔ بصورت دیگر ہمیں ہیش کرنا پڑتا تاکہ صارف 1 کو صارف 0 کی قدر معلوم نہ ہو، صارف 2 کو صارف 3 کی قدر معلوم نہ ہو، وغیرہ۔
// اس سٹرنگ کے درمیان تبدیل کریں جس کی ہیش فنکشن توقع کرتا ہے اور
// وہ BigInt جسے ہم ہر دوسری جگہ استعمال کرتے ہیں۔
const hash = (x) =>
BigInt(ethers.utils.keccak256("0x" + x.toString(16).padStart(64, 0)))
ethers ہیش فنکشن کو ہیکسا ڈیسیمل نمبر کے ساتھ ایک JavaScript اسٹرنگ ملنے کی توقع ہوتی ہے، جیسے کہ 0x60A7، اور یہ اسی ساخت کے ساتھ ایک اور اسٹرنگ کے ساتھ جواب دیتا ہے۔ تاہم، باقی کوڈ کے لیے BigInt استعمال کرنا آسان ہے، اس لیے ہم اسے ہیکسا ڈیسیمل اسٹرنگ میں تبدیل کرتے ہیں اور پھر واپس لاتے ہیں۔
// ایک جوڑے کا سمیٹریکل ہیش تاکہ ہمیں پرواہ نہ ہو کہ آیا ترتیب الٹ گئی ہے۔
const pairHash = (a, b) => hash(hash(a) ^ hash(b))
یہ فنکشن سڈول (symmetrical) ہے (a xor (opens in a new tab) b کا ہیش)۔ اس کا مطلب یہ ہے کہ جب ہم مرکل ثبوت چیک کرتے ہیں تو ہمیں اس بات کی فکر کرنے کی ضرورت نہیں ہوتی کہ ثبوت سے حاصل کردہ قدر کو حسابی قدر سے پہلے رکھنا ہے یا بعد میں۔ مرکل ثبوت کی جانچ آن چین کی جاتی ہے، اس لیے ہمیں وہاں جتنا کم کام کرنا پڑے اتنا ہی بہتر ہے۔
انتباہ:
علمِ تشفیر جتنا لگتا ہے اس سے کہیں زیادہ مشکل ہے۔
اس مضمون کے ابتدائی ورژن میں ہیش فنکشن hash(a^b) تھا۔
یہ ایک برا خیال تھا کیونکہ اس کا مطلب یہ تھا کہ اگر آپ کو a اور b کی جائز اقدار معلوم ہوں تو آپ کسی بھی مطلوبہ a' قدر کو ثابت کرنے کے لیے b' = a^b^a' استعمال کر سکتے تھے۔
اس فنکشن کے ساتھ آپ کو b' کا حساب اس طرح لگانا ہوگا کہ hash(a') ^ hash(b') ایک معلوم قدر (روٹ کے راستے پر اگلی شاخ) کے برابر ہو، جو کہ بہت زیادہ مشکل ہے۔
// وہ ویلیو جو یہ ظاہر کرتی ہے کہ ایک مخصوص برانچ خالی ہے، اس میں
// کوئی ویلیو نہیں ہے
const empty = 0n
جب اقدار کی تعداد دو کی انٹیجر پاور (integer power) نہیں ہوتی ہے تو ہمیں خالی شاخوں کو سنبھالنے کی ضرورت ہوتی ہے۔ یہ پروگرام جس طرح سے یہ کرتا ہے وہ یہ ہے کہ صفر کو پلیس ہولڈر کے طور پر رکھتا ہے۔
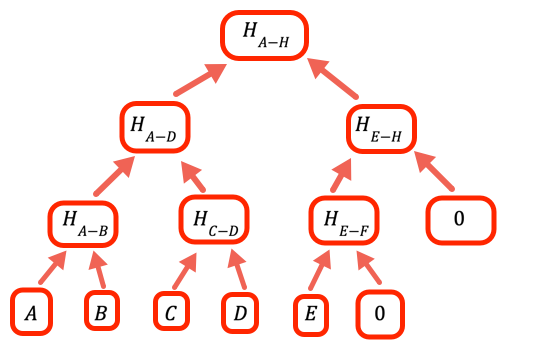
// ہیش ایرے کے ٹری میں ایک لیول اوپر کا حساب لگائیں، جس کے لیے
// ترتیب میں ہر جوڑے کا ہیش لیا جاتا ہے
const oneLevelUp = (inputArray) => {
var result = []
var inp = [...inputArray] // ان پٹ کو اوور رائٹ کرنے سے بچنے کے لیے // اگر ضروری ہو تو ایک خالی ویلیو شامل کریں (ہمیں تمام لیوز کا // جوڑا بنانا ضروری ہے)
if (inp.length % 2 === 1) inp.push(empty)
for (var i = 0; i < inp.length; i += 2)
result.push(pairHash(inp[i], inp[i + 1]))
return result
} // oneLevelUp
یہ فنکشن موجودہ لیئر پر اقدار کے جوڑوں کو ہیش کر کے مرکل ٹری میں ایک سطح "اوپر چڑھتا" ہے۔ نوٹ کریں کہ یہ سب سے زیادہ موثر نفاذ نہیں ہے، ہم ان پٹ کو کاپی کرنے سے بچ سکتے تھے اور لوپ میں مناسب ہونے پر صرف hashEmpty شامل کر سکتے تھے، لیکن یہ کوڈ پڑھنے میں آسانی کے لیے بہتر بنایا گیا ہے۔
const getMerkleRoot = (inputArray) => {
var result
result = [...inputArray] // ٹری میں اوپر جائیں جب تک کہ صرف ایک ویلیو نہ رہ جائے، جو کہ // روٹ ہے۔ // // اگر کسی لیئر میں اندراجات کی تعداد طاق (odd) ہے تو // oneLevelUp میں موجود کوڈ ایک خالی ویلیو کا اضافہ کرتا ہے، لہذا اگر ہمارے پاس، مثال کے طور پر، // 10 لیوز ہیں تو دوسری لیئر میں 5 برانچز ہوں گی، تیسری میں 3 // برانچز، چوتھی میں 2 اور روٹ پانچویں ہوگی
while (result.length > 1) result = oneLevelUp(result)
return result[0]
}
روٹ حاصل کرنے کے لیے، اس وقت تک اوپر چڑھیں جب تک کہ صرف ایک قدر باقی نہ رہ جائے۔
مرکل ثبوت بنانا
مرکل ثبوت وہ اقدار ہیں جنہیں ثابت کی جانے والی قدر کے ساتھ ہیش کیا جاتا ہے تاکہ مرکل روٹ واپس حاصل کیا جا سکے۔ ثابت کرنے والی قدر اکثر دوسرے ڈیٹا سے دستیاب ہوتی ہے، اس لیے میں اسے کوڈ کے حصے کے بجائے الگ سے فراہم کرنے کو ترجیح دیتا ہوں۔
// ایک مرکل ثبوت ان اندراجات کی فہرست کی ویلیو پر مشتمل ہوتا ہے جن کے ساتھ
// ہیش کرنا ہے۔ چونکہ ہم ایک سمیٹریکل ہیش فنکشن استعمال کرتے ہیں، اس لیے ہمیں
// ثبوت کی تصدیق کے لیے آئٹم کی لوکیشن کی ضرورت نہیں ہوتی، صرف اسے بنانے کے لیے ہوتی ہے
const getMerkleProof = (inputArray, n) => {
var result = [], currentLayer = [...inputArray], currentN = n
// جب تک ہم ٹاپ پر نہ پہنچ جائیں
while (currentLayer.length > 1) {
// کوئی طاق لمبائی والی لیئرز نہیں
if (currentLayer.length % 2)
currentLayer.push(empty)
result.push(currentN % 2
// اگر currentN طاق ہے، تو اس سے پہلے والی ویلیو کے ساتھ ثبوت میں شامل کریں
? currentLayer[currentN-1]
// اگر یہ جفت ہے، تو اس کے بعد والی ویلیو شامل کریں
: currentLayer[currentN+1])
ہم (v[0],v[1])، (v[2],v[3])، وغیرہ کو ہیش کرتے ہیں۔ لہذا جفت (even) اقدار کے لیے ہمیں اگلی قدر کی ضرورت ہوتی ہے، اور طاق (odd) اقدار کے لیے پچھلی قدر کی۔
// اگلی لیئر میں اوپر جائیں
currentN = Math.floor(currentN/2)
currentLayer = oneLevelUp(currentLayer)
} // while currentLayer.length > 1
return result
} // getMerkleProof
آن چین کوڈ
آخر میں ہمارے پاس وہ کوڈ ہے جو ثبوت کی جانچ کرتا ہے۔ آن چین کوڈ Solidity (opens in a new tab) میں لکھا گیا ہے۔ یہاں آپٹیمائزیشن بہت زیادہ اہم ہے کیونکہ گیس نسبتاً مہنگی ہے۔
//SPDX-License-Identifier: Public Domain
pragma solidity ^0.8.0;
import "hardhat/console.sol";
میں نے اسے Hardhat ڈیولپمنٹ انوائرنمنٹ (opens in a new tab) کا استعمال کرتے ہوئے لکھا ہے، جو ہمیں ڈیولپمنٹ کے دوران Solidity سے کنسول آؤٹ پٹ (opens in a new tab) حاصل کرنے کی سہولت دیتا ہے۔
contract MerkleProof {
uint merkleRoot;
function getRoot() public view returns (uint) {
return merkleRoot;
}
// انتہائی غیر محفوظ، پروڈکشن کوڈ میں
// اس فنکشن تک رسائی کو سختی سے محدود کیا جانا چاہیے، غالباً ایک
// مالک تک
function setRoot(uint _merkleRoot) external {
merkleRoot = _merkleRoot;
} // setRoot
مرکل روٹ کے لیے سیٹ (Set) اور گیٹ (get) فنکشنز۔ پروڈکشن سسٹم میں ہر کسی کو مرکل روٹ اپ ڈیٹ کرنے کی اجازت دینا ایک انتہائی برا خیال ہے۔ میں یہاں نمونہ کوڈ کی سادگی کی خاطر ایسا کر رہا ہوں۔ ایسے سسٹم پر ایسا نہ کریں جہاں ڈیٹا کی سالمیت واقعی اہمیت رکھتی ہو۔
function hash(uint _a) internal pure returns(uint) {
return uint(keccak256(abi.encode(_a)));
}
function pairHash(uint _a, uint _b) internal pure returns(uint) {
return hash(hash(_a) ^ hash(_b));
}
یہ فنکشن ایک پیئر ہیش (pair hash) تیار کرتا ہے۔ یہ صرف hash اور pairHash کے لیے JavaScript کوڈ کا Solidity ترجمہ ہے۔
نوٹ: یہ پڑھنے میں آسانی کے لیے آپٹیمائزیشن کی ایک اور مثال ہے۔ فنکشن کی تعریف (opens in a new tab) کی بنیاد پر، ڈیٹا کو bytes32 (opens in a new tab) ویلیو کے طور پر اسٹور کرنا اور تبادلوں (conversions) سے بچنا ممکن ہو سکتا ہے۔
// ایک مرکل ثبوت کی تصدیق کریں
function verifyProof(uint _value, uint[] calldata _proof)
public view returns (bool) {
uint temp = _value;
uint i;
for(i=0; i<_proof.length; i++) {
temp = pairHash(temp, _proof[i]);
}
return temp == merkleRoot;
}
} // MarkleProof
ریاضیاتی اشارے (mathematical notation) میں مرکل ثبوت کی تصدیق اس طرح نظر آتی ہے: H(proof_n, H(proof_n-1, H(proof_n-2, ... H(proof_1, H(proof_0, value))...)))۔ یہ کوڈ اسے نافذ کرتا ہے۔
مرکل ثبوت اور رول اپس آپس میں نہیں ملتے
مرکل ثبوت رول اپس کے ساتھ اچھی طرح کام نہیں کرتے۔ اس کی وجہ یہ ہے کہ رول اپس تمام ٹرانزیکشن ڈیٹا لیئر ۱ (l1) پر لکھتے ہیں، لیکن لیئر ۲ (l2) پر پروسیس کرتے ہیں۔ ٹرانزیکشن کے ساتھ مرکل ثبوت بھیجنے کی لاگت اوسطاً 638 گیس فی لیئر ہوتی ہے (فی الحال کال ڈیٹا میں ایک بائٹ کی لاگت 16 گیس ہوتی ہے اگر یہ صفر نہ ہو، اور 4 اگر یہ صفر ہو)۔ اگر ہمارے پاس ڈیٹا کے 1024 ورڈز ہیں، تو مرکل ثبوت کے لیے دس لیئرز، یا کل 6380 گیس درکار ہوتی ہے۔
مثال کے طور پر آپٹیمزم (opens in a new tab) کو دیکھیں، لیئر ۱ (l1) گیس لکھنے کی لاگت تقریباً 100 Gwei ہے اور لیئر ۲ (l2) گیس کی لاگت 0.001 Gwei ہے (یہ عام قیمت ہے، رش کے ساتھ یہ بڑھ سکتی ہے)۔ لہذا ایک لیئر ۱ (l1) گیس کی لاگت کے بدلے ہم لیئر ۲ (l2) پروسیسنگ پر ایک لاکھ گیس خرچ کر سکتے ہیں۔ یہ فرض کرتے ہوئے کہ ہم اسٹوریج کو اوور رائٹ نہیں کرتے، اس کا مطلب یہ ہے کہ ہم ایک لیئر ۱ (l1) گیس کی قیمت پر لیئر ۲ (l2) پر اسٹوریج میں تقریباً پانچ ورڈز لکھ سکتے ہیں۔ ایک واحد مرکل ثبوت کے لیے ہم پورے 1024 ورڈز کو اسٹوریج میں لکھ سکتے ہیں (یہ فرض کرتے ہوئے کہ ان کا حساب شروع سے ہی آن چین لگایا جا سکتا ہے، بجائے اس کے کہ انہیں ٹرانزیکشن میں فراہم کیا جائے) اور پھر بھی زیادہ تر گیس بچ جائے گی۔
نتیجہ
حقیقی زندگی میں آپ شاید کبھی بھی خود سے مرکل ٹریز نافذ نہ کریں۔ ایسی مشہور اور آڈٹ شدہ لائبریریاں موجود ہیں جنہیں آپ استعمال کر سکتے ہیں اور عام طور پر بات کی جائے تو بہتر یہی ہے کہ آپ خود سے کرپٹوگرافک پریمیٹیوز (cryptographic primitives) نافذ نہ کریں۔ لیکن مجھے امید ہے کہ اب آپ مرکل ثبوت کو بہتر طور پر سمجھتے ہیں اور فیصلہ کر سکتے ہیں کہ انہیں کب استعمال کرنا فائدہ مند ہے۔
نوٹ کریں کہ اگرچہ مرکل ثبوت سالمیت کو برقرار رکھتے ہیں، لیکن وہ دستیابی کو برقرار نہیں رکھتے۔ یہ جاننا کہ کوئی اور آپ کے اثاثے نہیں لے سکتا، ایک چھوٹی سی تسلی ہے اگر ڈیٹا اسٹوریج رسائی کی اجازت نہ دینے کا فیصلہ کرے اور آپ ان تک رسائی کے لیے مرکل ٹری بھی نہ بنا سکیں۔ لہذا مرکل ٹریز کو کسی قسم کے لامركزی اسٹوریج، جیسے کہ IPFS، کے ساتھ استعمال کرنا بہترین ہے۔