離線資料完整性的默克爾證明
簡介
理想情況下,我們希望將所有內容儲存在以太坊儲存空間中,這些資料分佈在數千台電腦上,具有極高的可用性(資料無法被審查)和完整性(資料無法被未經授權地修改),但儲存一個 32 位元組的字組通常需要花費 20,000 燃料。在我撰寫本文時,該成本相當於 6.60 美元。以每位元組 21 美分的價格來看,這對許多用途來說太昂貴了。
為了解決這個問題,以太坊生態系開發了許多以去中心化方式儲存資料的替代方案。通常它們涉及可用性和價格之間的權衡。然而,完整性通常是有保障的。
在本文中,您將學習如何使用默克爾證明 (opens in a new tab)在不將資料儲存於區塊鏈上的情況下確保資料完整性。
它是如何運作的?
理論上,我們大可只將資料的雜湊儲存在鏈上,並在需要它的交易中傳送所有資料。然而,這仍然太昂貴了。交易中的一個位元組資料大約花費 16 燃料,目前約為半美分,或每千位元組約 5 美元。以每百萬位元組 5000 美元的價格來看,這對許多用途來說仍然太昂貴,甚至還沒算上對資料進行雜湊運算的額外成本。
解決方案是重複對資料的不同子集進行雜湊運算,因此對於您不需要傳送的資料,您只需傳送一個雜湊即可。您可以使用默克爾樹來執行此操作,這是一種樹狀資料結構,其中每個節點都是其下方節點的雜湊:
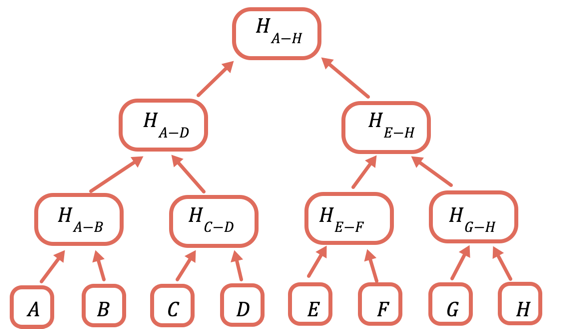
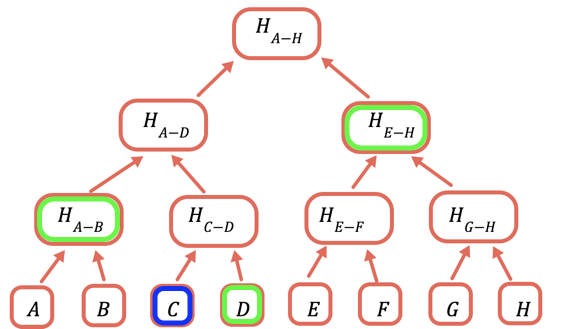
根雜湊是唯一需要儲存在鏈上的部分。為了證明某個值,您需要提供所有需要與其結合以獲得根的雜湊。例如,為了證明 C,您需要提供 D、H(A-B) 和 H(E-H)。
實作
此處提供了範例程式碼 (opens in a new tab)。
鏈下程式碼
在本文中,我們使用 JavaScript 進行鏈下計算。大多數去中心化應用程式 (dapp) 的鏈下元件都是用 JavaScript 編寫的。
建立默克爾根
首先,我們需要將默克爾根提供給鏈。
const ethers = require("ethers")
我們使用 ethers 套件中的雜湊函數 (opens in a new tab)。
// 我們必須驗證其完整性的原始資料。前兩個位元組
// 是一個使用者識別碼,最後兩個位元組是該
// 使用者目前擁有的代幣數量。
const dataArray = [
0x0bad0010, 0x60a70020, 0xbeef0030, 0xdead0040, 0xca110050, 0x0e660060,
0xface0070, 0xbad00080, 0x060d0091,
]
例如,將每個條目編碼為單個 256 位元整數會導致程式碼的可讀性低於使用 JSON。然而,這意味著在合約中擷取資料的處理量顯著減少,因此燃料成本要低得多。您可以在鏈上讀取 JSON (opens in a new tab),但如果可以避免的話,這通常是個壞主意。
// 雜湊值的陣列,型別為 BigInt
const hashArray = dataArray
在這個例子中,我們的資料一開始就是 256 位元的值,因此不需要進行處理。如果我們使用更複雜的資料結構(例如字串),我們需要確保先對資料進行雜湊運算以獲得雜湊陣列。請注意,這也是因為我們不在乎使用者是否知道其他使用者的資訊。否則我們就必須進行雜湊運算,這樣使用者 1 就不會知道使用者 0 的值,使用者 2 就不會知道使用者 3 的值,依此類推。
// 在雜湊函數預期的字串與
// 我們在其他地方使用的 BigInt 之間進行轉換。
const hash = (x) =>
BigInt(ethers.utils.keccak256("0x" + x.toString(16).padStart(64, 0)))
ethers 雜湊函數預期會收到一個帶有十六進位數字的 JavaScript 字串,例如 0x60A7,並以具有相同結構的另一個字串作為回應。然而,對於其餘的程式碼來說,使用 BigInt 會更容易,因此我們將其轉換為十六進位字串,然後再轉換回來。
// 一對數值的對稱雜湊,因此我們不在乎順序是否顛倒。
const pairHash = (a, b) => hash(hash(a) ^ hash(b))
這個函數是對稱的(a xor (opens in a new tab) b 的雜湊)。這意味著當我們檢查默克爾證明時,我們不需要擔心是將證明中的值放在計算值之前還是之後。默克爾證明檢查是在鏈上完成的,因此我們在那裡需要做的事情越少越好。
警告:
密碼學比看起來更難。
本文的初始版本使用了雜湊函數 hash(a^b)。
這是一個糟糕的主意,因為這意味著如果您知道 a 和 b 的合法值,您就可以使用 b' = a^b^a' 來證明任何想要的 a' 值。
使用這個函數,您必須計算 b' 使得 hash(a') ^ hash(b') 等於一個已知值(通往根的下一個分支),這要困難得多。
// 用來表示某個分支為空、沒有
// 值的數值
const empty = 0n
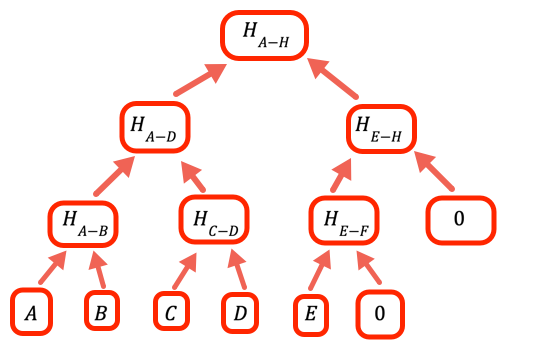
當值的數量不是二的整數次方時,我們需要處理空分支。這個程式的做法是將零作為佔位符。
// 透過取得以下項目的雜湊來計算雜湊陣列在樹中的上一層:
// 序列中的每一對
const oneLevelUp = (inputArray) => {
var result = []
var inp = [...inputArray] // 為了避免覆寫輸入 // 必要時加入一個空值(我們需要所有的葉節點都 // 成對)
if (inp.length % 2 === 1) inp.push(empty)
for (var i = 0; i < inp.length; i += 2)
result.push(pairHash(inp[i], inp[i + 1]))
return result
} // oneLevelUp
這個函數透過對目前層級的值對進行雜湊運算,在默克爾樹中「向上爬」一層。請注意,這不是最有效率的實作方式,我們本可以避免複製輸入,只需在迴圈中適當的時候加上 hashEmpty 即可,但這段程式碼是為了可讀性而最佳化的。
const getMerkleRoot = (inputArray) => {
var result
result = [...inputArray] // 向上攀爬該樹,直到只剩下一個值,那就是 // 根節點。 // // 如果某一層有奇數個項目,// oneLevelUp 中的程式碼會加入一個空值,因此舉例來說,如果我們有 // 10 個葉節點,我們在第二層會有 5 個分支,在第三層會有 3 個 // 分支,在第四層會有 2 個,而根節點是第五層
while (result.length > 1) result = oneLevelUp(result)
return result[0]
}
為了獲得根,不斷向上爬,直到只剩下一個值。
建立默克爾證明
默克爾證明是將要證明的值與其他值一起進行雜湊運算,以重新獲得默克爾根。要證明的值通常可以從其他資料中取得,因此我傾向於單獨提供它,而不是作為程式碼的一部分。
// 默克爾證明包含要與之進行
// 雜湊的項目清單值。因為我們使用對稱的雜湊函數,所以我們不
// 需要項目的位置來驗證證明,只有在建立證明時才需要
const getMerkleProof = (inputArray, n) => {
var result = [], currentLayer = [...inputArray], currentN = n
// 直到我們到達頂部
while (currentLayer.length > 1) {
// 沒有奇數長度的層
if (currentLayer.length % 2)
currentLayer.push(empty)
result.push(currentN % 2
// 如果 currentN 是奇數,則將其前面的值加入到證明中
? currentLayer[currentN-1]
// 如果是偶數,則加入其後面的值
: currentLayer[currentN+1])
我們對 (v[0],v[1])、(v[2],v[3]) 等進行雜湊運算。因此,對於偶數值,我們需要下一個值;對於奇數值,我們需要前一個值。
// 移動到上一層
currentN = Math.floor(currentN/2)
currentLayer = oneLevelUp(currentLayer)
} // while currentLayer.length > 1
return result
} // getMerkleProof
鏈上程式碼
最後,我們有檢查證明的程式碼。鏈上程式碼是用 Solidity (opens in a new tab) 編寫的。在這裡,最佳化要重要得多,因為燃料相對昂貴。
//SPDX-License-Identifier: Public Domain
pragma solidity ^0.8.0;
import "hardhat/console.sol";
我使用 Hardhat 開發環境 (opens in a new tab)編寫了這段程式碼,這讓我們在開發時可以有來自 Solidity 的主控台輸出 (opens in a new tab)。
contract MerkleProof {
uint merkleRoot;
function getRoot() public view returns (uint) {
return merkleRoot;
}
// 極度不安全,在正式環境的程式碼中,對
// 此函數的存取必須受到嚴格限制,可能僅限於
// 擁有者
function setRoot(uint _merkleRoot) external {
merkleRoot = _merkleRoot;
} // setRoot
默克爾根的設定 (set) 和取得 (get) 函數。在生產系統中讓每個人都能更新默克爾根是一個_極度糟糕的主意_。我在這裡這樣做是為了簡化範例程式碼。不要在真正重視資料完整性的系統上這樣做。
function hash(uint _a) internal pure returns(uint) {
return uint(keccak256(abi.encode(_a)));
}
function pairHash(uint _a, uint _b) internal pure returns(uint) {
return hash(hash(_a) ^ hash(_b));
}
這個函數產生一個配對雜湊。它只是 hash 和 pairHash 的 JavaScript 程式碼的 Solidity 翻譯版本。
注意: 這是另一個為了可讀性而最佳化的例子。根據函數定義 (opens in a new tab),或許可以將資料儲存為 bytes32 (opens in a new tab) 值並避免轉換。
// 驗證默克爾證明
function verifyProof(uint _value, uint[] calldata _proof)
public view returns (bool) {
uint temp = _value;
uint i;
for(i=0; i<_proof.length; i++) {
temp = pairHash(temp, _proof[i]);
}
return temp == merkleRoot;
}
} // MarkleProof
在數學符號中,默克爾證明驗證看起來像這樣:H(proof_n, H(proof_n-1, H(proof_n-2, ... H(proof_1, H(proof_0, value))...)))。這段程式碼實作了它。
默克爾證明與匯總無法混用
默克爾證明與匯總搭配得不好。原因是匯總將所有交易資料寫入第一層 (L1),但在第二層 (L2) 上進行處理。在交易中傳送默克爾證明的成本平均每層為 638 燃料(目前呼叫資料中的一個位元組如果不為零則花費 16 燃料,如果為零則花費 4 燃料)。如果我們有 1024 個字組的資料,默克爾證明需要十層,總共 6380 燃料。
以 Optimism (opens in a new tab) 為例,寫入 L1 燃料大約花費 100 Gwei,而 L2 燃料花費 0.001 Gwei(這是正常價格,可能會隨著網路擁塞而上漲)。因此,花費一個 L1 燃料的成本,我們可以在 L2 處理上花費十萬燃料。假設我們不覆寫儲存空間,這意味著我們可以用一個 L1 燃料的價格在 L2 上將大約五個字組寫入儲存空間。對於單個默克爾證明,我們可以將整個 1024 個字組寫入儲存空間(假設它們一開始就可以在鏈上計算,而不是在交易中提供),並且仍然剩下大部分的燃料。
結論
在現實生活中,您可能永遠不會自己實作默克爾樹。有眾所周知且經過稽核的函式庫可供使用,一般來說,最好不要自己實作密碼學原語。但我希望現在您對默克爾證明有更好的了解,並能決定何時值得使用它們。
請注意,雖然默克爾證明保留了_完整性_,但它們並不保留_可用性_。如果資料儲存決定不允許存取,而您也無法建構默克爾樹來存取它們,那麼知道沒有其他人可以拿走您的資產也只是微小的安慰。因此,默克爾樹最好與某種去中心化儲存(例如 IPFS)一起使用。