Comment utiliser Slither pour trouver des bugs dans les contrats intelligents
Comment utiliser Slither
Le but de ce tutoriel est de montrer comment utiliser Slither pour trouver automatiquement des bugs dans les contrats intelligents.
- Installation
- Utilisation en ligne de commande
- Introduction à l'analyse statique : Brève introduction à l'analyse statique
- API : Description de l'API Python
Installation
Slither nécessite Python >= 3.6. Il peut être installé via pip ou en utilisant Docker.
Slither via pip :
pip3 install --user slither-analyzer
Slither via Docker :
docker pull trailofbits/eth-security-toolbox
docker run -it -v "$PWD":/home/trufflecon trailofbits/eth-security-toolbox
La dernière commande exécute eth-security-toolbox dans un conteneur Docker qui a accès à votre répertoire actuel. Vous pouvez modifier les fichiers depuis votre hôte et exécuter les outils sur les fichiers depuis Docker.
À l'intérieur de Docker, exécutez :
solc-select 0.5.11
cd /home/trufflecon/
Exécuter un script
Pour exécuter un script Python avec Python 3 :
python3 script.py
Ligne de commande
Ligne de commande par rapport aux scripts définis par l'utilisateur. Slither est livré avec un ensemble de détecteurs prédéfinis qui trouvent de nombreux bugs courants. Appeler Slither depuis la ligne de commande exécutera tous les détecteurs, aucune connaissance détaillée de l'analyse statique n'est nécessaire :
slither project_paths
En plus des détecteurs, Slither possède des capacités de révision de code grâce à ses afficheurs (printers) (s'ouvre dans un nouvel onglet) et outils (s'ouvre dans un nouvel onglet).
Utilisez crytic.io (s'ouvre dans un nouvel onglet) pour accéder à des détecteurs privés et à l'intégration GitHub.
Analyse statique
Les capacités et la conception du framework d'analyse statique Slither ont été décrites dans des articles de blog (1 (s'ouvre dans un nouvel onglet), 2 (s'ouvre dans un nouvel onglet)) et un article académique (s'ouvre dans un nouvel onglet).
L'analyse statique existe sous différentes formes. Vous réalisez très probablement que les compilateurs comme clang (s'ouvre dans un nouvel onglet) et gcc (s'ouvre dans un nouvel onglet) dépendent de ces techniques de recherche, mais elles sous-tendent également Infer (s'ouvre dans un nouvel onglet), CodeClimate (s'ouvre dans un nouvel onglet), FindBugs (s'ouvre dans un nouvel onglet) et des outils basés sur des méthodes formelles comme Frama-C (s'ouvre dans un nouvel onglet) et Polyspace (s'ouvre dans un nouvel onglet).
Nous ne passerons pas en revue de manière exhaustive les techniques d'analyse statique et les chercheurs ici. Au lieu de cela, nous nous concentrerons sur ce qui est nécessaire pour comprendre comment fonctionne Slither afin que vous puissiez l'utiliser plus efficacement pour trouver des bugs et comprendre le code.
Représentation du code
Contrairement à une analyse dynamique, qui raisonne sur un seul chemin d'exécution, l'analyse statique raisonne sur tous les chemins à la fois. Pour ce faire, elle s'appuie sur une représentation de code différente. Les deux plus courantes sont l'arbre de syntaxe abstraite (AST) et le graphe de flux de contrôle (CFG).
Arbres de syntaxe abstraite (AST)
Les AST sont utilisés chaque fois que le compilateur analyse du code. C'est probablement la structure la plus basique sur laquelle l'analyse statique peut être effectuée.
En résumé, un AST est un arbre structuré où, généralement, chaque feuille contient une variable ou une constante et les nœuds internes sont des opérandes ou des opérations de flux de contrôle. Considérez le code suivant :
function safeAdd(uint a, uint b) pure internal returns(uint){
if(a + b <= a){
revert();
}
return a + b;
}
L'AST correspondant est illustré dans :
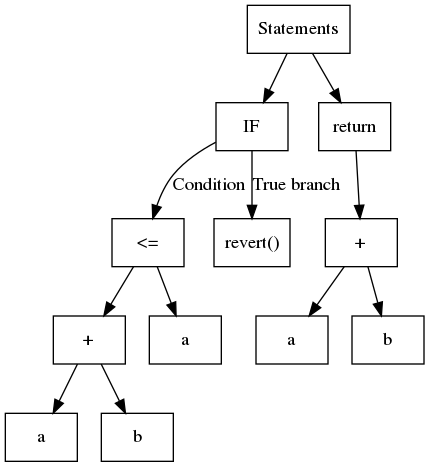
Slither utilise l'AST exporté par solc.
Bien que simple à construire, l'AST est une structure imbriquée. Parfois, ce n'est pas la plus simple à analyser. Par exemple, pour identifier les opérations utilisées par l'expression a + b <= a, vous devez d'abord analyser <= puis +. Une approche courante consiste à utiliser ce qu'on appelle le patron de conception visiteur (visitor pattern), qui navigue à travers l'arbre de manière récursive. Slither contient un visiteur générique dans ExpressionVisitor (s'ouvre dans un nouvel onglet).
Le code suivant utilise ExpressionVisitor pour détecter si l'expression contient une addition :
from slither.visitors.expression.expression import ExpressionVisitor
from slither.core.expressions.binary_operation import BinaryOperationType
class HasAddition(ExpressionVisitor):
def result(self):
return self._result
def _post_binary_operation(self, expression):
if expression.type == BinaryOperationType.ADDITION:
self._result = True
visitor = HasAddition(expression) # expression est l'expression à tester
print(f'The expression {expression} has a addition: {visitor.result()}')
Graphe de flux de contrôle (CFG)
La deuxième représentation de code la plus courante est le graphe de flux de contrôle (CFG). Comme son nom l'indique, il s'agit d'une représentation basée sur un graphe qui expose tous les chemins d'exécution. Chaque nœud contient une ou plusieurs instructions. Les arêtes du graphe représentent les opérations de flux de contrôle (if/then/else, boucle, etc.). Le CFG de notre exemple précédent est :
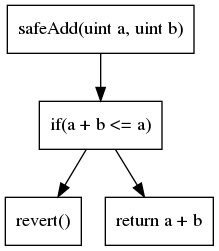
Le CFG est la représentation sur laquelle la plupart des analyses sont construites.
De nombreuses autres représentations de code existent. Chaque représentation a des avantages et des inconvénients selon l'analyse que vous souhaitez effectuer.
Analyse
Le type d'analyses le plus simple que vous pouvez effectuer avec Slither sont les analyses syntaxiques.
Analyse syntaxique
Slither peut naviguer à travers les différents composants du code et leur représentation pour trouver des incohérences et des failles en utilisant une approche de type reconnaissance de motifs (pattern matching).
Par exemple, les détecteurs suivants recherchent des problèmes liés à la syntaxe :
-
Masquage de variable d'état (State variable shadowing) (s'ouvre dans un nouvel onglet) : itère sur toutes les variables d'état et vérifie si l'une d'elles masque une variable d'un contrat hérité (state.py#L51-L62 (s'ouvre dans un nouvel onglet))
-
Interface ERC-20 incorrecte (s'ouvre dans un nouvel onglet) : recherche des signatures de fonction ERC-20 incorrectes (incorrect_erc20_interface.py#L34-L55 (s'ouvre dans un nouvel onglet))
Analyse sémantique
Contrairement à l'analyse syntaxique, une analyse sémantique ira plus loin et analysera le « sens » du code. Cette famille comprend quelques grands types d'analyses. Elles conduisent à des résultats plus puissants et utiles, mais sont également plus complexes à écrire.
Les analyses sémantiques sont utilisées pour les détections de vulnérabilités les plus avancées.
Analyse des dépendances de données
Une variable variable_a est dite dépendante des données de variable_b s'il existe un chemin pour lequel la valeur de variable_a est influencée par variable_b.
Dans le code suivant, variable_a est dépendante de variable_b :
// ...
variable_a = variable_b + 1;
Slither est doté de capacités intégrées de dépendance de données (s'ouvre dans un nouvel onglet), grâce à sa représentation intermédiaire (abordée dans une section ultérieure).
Un exemple d'utilisation de la dépendance de données peut être trouvé dans le détecteur d'égalité stricte dangereuse (s'ouvre dans un nouvel onglet). Ici, Slither recherchera une comparaison d'égalité stricte avec une valeur dangereuse (incorrect_strict_equality.py#L86-L87 (s'ouvre dans un nouvel onglet)), et informera l'utilisateur qu'il devrait utiliser >= ou <= plutôt que ==, pour empêcher un attaquant de piéger le contrat. Entre autres, le détecteur considérera comme dangereuse la valeur de retour d'un appel à balanceOf(address) (incorrect_strict_equality.py#L63-L64 (s'ouvre dans un nouvel onglet)), et utilisera le moteur de dépendance de données pour suivre son utilisation.
Calcul de point fixe
Si votre analyse navigue à travers le CFG et suit les arêtes, vous êtes susceptible de voir des nœuds déjà visités. Par exemple, si une boucle est présentée comme indiqué ci-dessous :
for(uint i; i < range; ++){
variable_a += 1
}
Votre analyse devra savoir quand s'arrêter. Il y a deux stratégies principales ici : (1) itérer sur chaque nœud un nombre fini de fois, (2) calculer ce qu'on appelle un point fixe (fixpoint). Un point fixe signifie fondamentalement que l'analyse de ce nœud ne fournit aucune information significative.
Un exemple de point fixe utilisé peut être trouvé dans les détecteurs de réentrance : Slither explore les nœuds, et recherche les appels externes, les écritures et les lectures dans le stockage. Une fois qu'il a atteint un point fixe (reentrancy.py#L125-L131 (s'ouvre dans un nouvel onglet)), il arrête l'exploration, et analyse les résultats pour voir si une réentrance est présente, à travers différents modèles de réentrance (reentrancy_benign.py (s'ouvre dans un nouvel onglet), reentrancy_read_before_write.py (s'ouvre dans un nouvel onglet), reentrancy_eth.py (s'ouvre dans un nouvel onglet)).
L'écriture d'analyses utilisant un calcul de point fixe efficace nécessite une bonne compréhension de la façon dont l'analyse propage ses informations.
Représentation intermédiaire
Une représentation intermédiaire (IR) est un langage censé être plus propice à l'analyse statique que l'original. Slither traduit Solidity vers sa propre IR : SlithIR (s'ouvre dans un nouvel onglet).
Comprendre SlithIR n'est pas nécessaire si vous souhaitez uniquement écrire des vérifications de base. Cependant, cela vous sera utile si vous prévoyez d'écrire des analyses sémantiques avancées. Les afficheurs (printers) SlithIR (s'ouvre dans un nouvel onglet) et SSA (s'ouvre dans un nouvel onglet) vous aideront à comprendre comment le code est traduit.
Bases de l'API
Slither possède une API qui vous permet d'explorer les attributs de base du contrat et de ses fonctions.
Pour charger une base de code :
from slither import Slither
slither = Slither('/path/to/project')
Explorer les contrats et les fonctions
Un objet Slither possède :
contracts (list(Contract): liste des contratscontracts_derived (list(Contract): liste des contrats qui ne sont pas hérités par un autre contrat (sous-ensemble de contrats)get_contract_from_name (str): Retourne un contrat à partir de son nom
Un objet Contract possède :
name (str): Nom du contratfunctions (list(Function)): Liste des fonctionsmodifiers (list(Modifier)): Liste des fonctionsall_functions_called (list(Function/Modifier)): Liste de toutes les fonctions internes accessibles par le contratinheritance (list(Contract)): Liste des contrats héritésget_function_from_signature (str): Retourne une fonction (Function) à partir de sa signatureget_modifier_from_signature (str): Retourne un modificateur (Modifier) à partir de sa signatureget_state_variable_from_name (str): Retourne une variable d'état (StateVariable) à partir de son nom
Un objet Function ou Modifier possède :
name (str): Nom de la fonctioncontract (contract): le contrat où la fonction est déclaréenodes (list(Node)): Liste des nœuds composant le CFG de la fonction/du modificateurentry_point (Node): Point d'entrée du CFGvariables_read (list(Variable)): Liste des variables luesvariables_written (list(Variable)): Liste des variables écritesstate_variables_read (list(StateVariable)): Liste des variables d'état lues (sous-ensemble de variables lues)state_variables_written (list(StateVariable)): Liste des variables d'état écrites (sous-ensemble de variables écrites)