Preuves de Merkle pour l'intégrité des données hors ligne
Introduction
Idéalement, nous aimerions tout stocker dans le stockage d'Ethereum, qui est réparti sur des milliers d'ordinateurs et offre une très haute disponibilité (les données ne peuvent pas être censurées) et intégrité (les données ne peuvent pas être modifiées de manière non autorisée), mais le stockage d'un mot de 32 octets coûte généralement 20 000 gaz. Au moment où j'écris ces lignes, ce coût équivaut à 6,60 $. À 21 cents par octet, c'est trop cher pour de nombreuses utilisations.
Pour résoudre ce problème, l'écosystème Ethereum a développé de nombreuses méthodes alternatives pour stocker des données de manière décentralisée. Elles impliquent généralement un compromis entre disponibilité et prix. Cependant, l'intégrité est généralement assurée.
Dans cet article, vous apprendrez comment assurer l'intégrité des données sans stocker les données sur la chaîne de blocs, en utilisant des preuves de Merkle (opens in a new tab).
Comment ça marche ?
En théorie, nous pourrions simplement stocker le hash des données onchain, et envoyer toutes les données dans les transactions qui le nécessitent. Cependant, cela reste trop cher. Un octet de données dans une transaction coûte environ 16 gaz, soit actuellement environ un demi-centime, ou environ 5 $ par kilo-octet. À 5 000 $ par mégaoctet, cela reste trop cher pour de nombreuses utilisations, même sans le coût supplémentaire du hachage des données.
La solution consiste à hacher de manière répétée différents sous-ensembles de données, de sorte que pour les données que vous n'avez pas besoin d'envoyer, vous pouvez simplement envoyer un hash. Vous faites cela en utilisant un arbre de Merkle, une structure de données en arbre où chaque nœud est un hash des nœuds en dessous de lui :
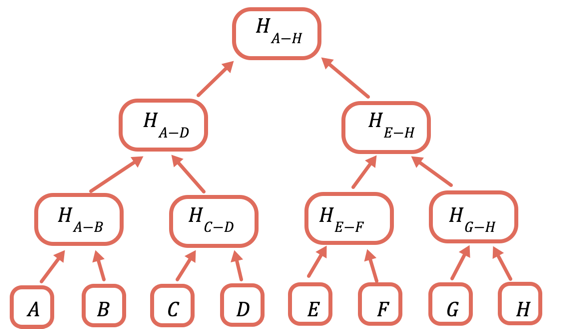
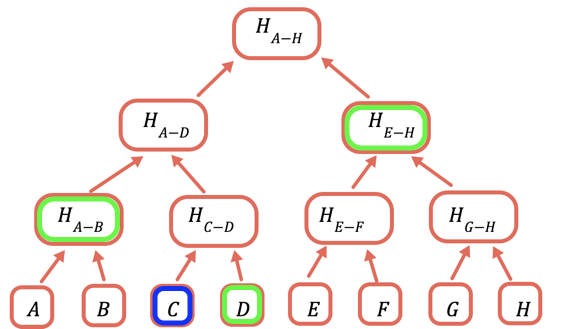
Le hash racine est la seule partie qui doit être stockée onchain. Pour prouver une certaine valeur, vous fournissez tous les hash qui doivent être combinés avec elle pour obtenir la racine. Par exemple, pour prouver C, vous fournissez D, H(A-B) et H(E-H).
Implémentation
Le code d'exemple est fourni ici (opens in a new tab).
Code hors chaîne
Dans cet article, nous utilisons JavaScript pour les calculs hors chaîne. La plupart des applications décentralisées ont leur composant hors chaîne en JavaScript.
Création de la racine de Merkle
Tout d'abord, nous devons fournir la racine de Merkle à la chaîne.
const ethers = require("ethers")
Nous utilisons la fonction de hachage du paquet ethers (opens in a new tab).
// Les données brutes dont nous devons vérifier l'intégrité. Les deux premiers octets s
// ont un identifiant utilisateur, et les deux derniers octets la quantité de jetons que le
// utilisateur possède actuellement.
const dataArray = [
0x0bad0010, 0x60a70020, 0xbeef0030, 0xdead0040, 0xca110050, 0x0e660060,
0xface0070, 0xbad00080, 0x060d0091,
]
L'encodage de chaque entrée en un seul entier de 256 bits donne un code moins lisible que l'utilisation de JSON, par exemple. Cependant, cela signifie beaucoup moins de traitement pour récupérer les données dans le contrat, et donc des coûts en gaz beaucoup plus faibles. Vous pouvez lire du JSON onchain (opens in a new tab), c'est juste une mauvaise idée si cela peut être évité.
// Le tableau des valeurs de hash, en tant que BigInts
const hashArray = dataArray
Dans ce cas, nos données sont des valeurs de 256 bits pour commencer, donc aucun traitement n'est nécessaire. Si nous utilisons une structure de données plus compliquée, comme des chaînes de caractères, nous devons nous assurer de hacher les données d'abord pour obtenir un tableau de hash. Notez que c'est aussi parce que nous nous moquons de savoir si les utilisateurs connaissent les informations des autres utilisateurs. Sinon, nous aurions dû hacher pour que l'utilisateur 1 ne connaisse pas la valeur de l'utilisateur 0, que l'utilisateur 2 ne connaisse pas la valeur de l'utilisateur 3, etc.
// Convertir entre la chaîne que la fonction de hachage attend et le
// BigInt que nous utilisons partout ailleurs.
const hash = (x) =>
BigInt(ethers.utils.keccak256("0x" + x.toString(16).padStart(64, 0)))
La fonction de hachage d'ethers s'attend à recevoir une chaîne JavaScript avec un nombre hexadécimal, tel que 0x60A7, et répond avec une autre chaîne ayant la même structure. Cependant, pour le reste du code, il est plus facile d'utiliser BigInt, nous convertissons donc en chaîne hexadécimale et vice versa.
// Hash symétrique d'une paire pour que nous ne nous souciions pas de savoir si l'ordre est inversé.
const pairHash = (a, b) => hash(hash(a) ^ hash(b))
Cette fonction est symétrique (hash de a xor (opens in a new tab) b). Cela signifie que lorsque nous vérifions la preuve de Merkle, nous n'avons pas à nous soucier de savoir s'il faut mettre la valeur de la preuve avant ou après la valeur calculée. La vérification de la preuve de Merkle se fait onchain, donc moins nous avons à y faire, mieux c'est.
Avertissement :
La cryptographie est plus difficile qu'il n'y paraît.
La version initiale de cet article utilisait la fonction de hachage hash(a^b).
C'était une mauvaise idée car cela signifiait que si vous connaissiez les valeurs légitimes de a et b, vous pouviez utiliser b' = a^b^a' pour prouver n'importe quelle valeur a' souhaitée.
Avec cette fonction, vous devriez calculer b' de telle sorte que hash(a') ^ hash(b') soit égal à une valeur connue (la branche suivante sur le chemin vers la racine), ce qui est beaucoup plus difficile.
// La valeur pour indiquer qu'une certaine branche est vide, n'a pas
// de valeur
const empty = 0n
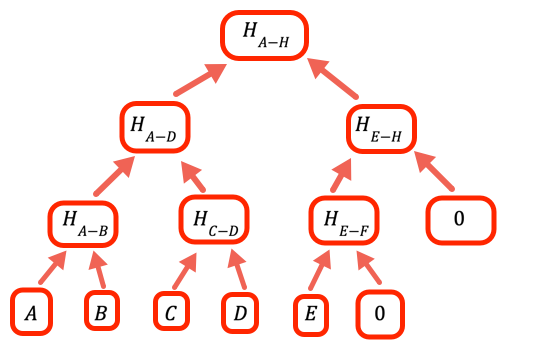
Lorsque le nombre de valeurs n'est pas une puissance entière de deux, nous devons gérer les branches vides. La façon dont ce programme procède est de mettre zéro comme espace réservé.
// Calculer un niveau plus haut dans l'arbre d'un tableau de hash en prenant le hash de
// chaque paire en séquence
const oneLevelUp = (inputArray) => {
var result = []
var inp = [...inputArray] // Pour éviter d'écraser l'entrée // Ajouter une valeur vide si nécessaire (nous avons besoin que toutes les feuilles soient // appariées)
if (inp.length % 2 === 1) inp.push(empty)
for (var i = 0; i < inp.length; i += 2)
result.push(pairHash(inp[i], inp[i + 1]))
return result
} // oneLevelUp
Cette fonction « grimpe » d'un niveau dans l'arbre de Merkle en hachant les paires de valeurs de la couche actuelle. Notez que ce n'est pas l'implémentation la plus efficace, nous aurions pu éviter de copier l'entrée et simplement ajouter hashEmpty au moment opportun dans la boucle, mais ce code est optimisé pour la lisibilité.
const getMerkleRoot = (inputArray) => {
var result
result = [...inputArray] // Grimper dans l'arbre jusqu'à ce qu'il n'y ait plus qu'une seule valeur, qui est la // racine. // // Si une couche a un nombre impair d'entrées, le // code dans oneLevelUp ajoute une valeur vide, donc si nous avons, par exemple, // 10 feuilles, nous aurons 5 branches dans la deuxième couche, 3 // branches dans la troisième, 2 dans la quatrième et la racine est la cinquième
while (result.length > 1) result = oneLevelUp(result)
return result[0]
}
Pour obtenir la racine, grimpez jusqu'à ce qu'il ne reste plus qu'une seule valeur.
Création d'une preuve de Merkle
Une preuve de Merkle correspond aux valeurs à hacher avec la valeur prouvée pour retrouver la racine de Merkle. La valeur à prouver est souvent disponible à partir d'autres données, je préfère donc la fournir séparément plutôt que de l'inclure dans le code.
// Une preuve de Merkle consiste en la valeur de la liste des entrées à
// hacher avec. Parce que nous utilisons une fonction de hachage symétrique, nous n'avons pas
// besoin de l'emplacement de l'élément pour vérifier la preuve, seulement pour la créer
const getMerkleProof = (inputArray, n) => {
var result = [], currentLayer = [...inputArray], currentN = n
// Jusqu'à ce que nous atteignions le sommet
while (currentLayer.length > 1) {
// Pas de couches de longueur impaire
if (currentLayer.length % 2)
currentLayer.push(empty)
result.push(currentN % 2
// Si currentN est impair, ajouter avec la valeur qui le précède à la preuve
? currentLayer[currentN-1]
// S'il est pair, ajouter la valeur qui le suit
: currentLayer[currentN+1])
Nous hachons (v[0],v[1]), (v[2],v[3]), etc. Donc pour les valeurs paires, nous avons besoin de la suivante, pour les valeurs impaires, de la précédente.
// Passer à la couche supérieure
currentN = Math.floor(currentN/2)
currentLayer = oneLevelUp(currentLayer)
} // while currentLayer.length > 1
return result
} // getMerkleProof
Code onchain
Enfin, nous avons le code qui vérifie la preuve. Le code onchain est écrit en Solidity (opens in a new tab). L'optimisation est beaucoup plus importante ici car le gaz est relativement cher.
//SPDX-License-Identifier: Public Domain
pragma solidity ^0.8.0;
import "hardhat/console.sol";
J'ai écrit ceci en utilisant l'environnement de développement Hardhat (opens in a new tab), qui nous permet d'avoir une sortie console depuis Solidity (opens in a new tab) pendant le développement.
contract MerkleProof {
uint merkleRoot;
function getRoot() public view returns (uint) {
return merkleRoot;
}
// Extrêmement peu sécurisé, dans le code de production l'accès à
// cette fonction DOIT ÊTRE strictement limité, probablement à un
// propriétaire
function setRoot(uint _merkleRoot) external {
merkleRoot = _merkleRoot;
} // setRoot
Fonctions de définition (set) et d'obtention (get) pour la racine de Merkle. Laisser tout le monde mettre à jour la racine de Merkle est une très mauvaise idée dans un système en production. Je le fais ici par souci de simplicité pour le code d'exemple. Ne le faites pas sur un système où l'intégrité des données compte vraiment.
function hash(uint _a) internal pure returns(uint) {
return uint(keccak256(abi.encode(_a)));
}
function pairHash(uint _a, uint _b) internal pure returns(uint) {
return hash(hash(_a) ^ hash(_b));
}
Cette fonction génère un hash de paire. C'est juste la traduction en Solidity du code JavaScript pour hash et pairHash.
Remarque : C'est un autre cas d'optimisation pour la lisibilité. D'après la définition de la fonction (opens in a new tab), il pourrait être possible de stocker les données en tant que valeur bytes32 (opens in a new tab) et d'éviter les conversions.
// Vérifier une preuve de Merkle
function verifyProof(uint _value, uint[] calldata _proof)
public view returns (bool) {
uint temp = _value;
uint i;
for(i=0; i<_proof.length; i++) {
temp = pairHash(temp, _proof[i]);
}
return temp == merkleRoot;
}
} // MarkleProof
En notation mathématique, la vérification de la preuve de Merkle ressemble à ceci : H(proof_n, H(proof_n-1, H(proof_n-2, ... H(proof_1, H(proof_0, value))...))). Ce code l'implémente.
Les preuves de Merkle et les rollup ne font pas bon ménage
Les preuves de Merkle ne fonctionnent pas bien avec les rollup. La raison est que les rollup écrivent toutes les données de transaction sur la couche 1 (l1), mais les traitent sur la couche 2 (l2). Le coût d'envoi d'une preuve de Merkle avec une transaction s'élève en moyenne à 638 gaz par couche (actuellement, un octet dans les données d'appel coûte 16 gaz s'il n'est pas nul, et 4 s'il est nul). Si nous avons 1024 mots de données, une preuve de Merkle nécessite dix couches, soit un total de 6380 gaz.
Si l'on regarde par exemple Optimism (opens in a new tab), l'écriture de gaz l1 coûte environ 100 gwei et le gaz l2 coûte 0,001 gwei (c'est le prix normal, il peut augmenter avec la congestion). Donc, pour le coût d'un gaz l1, nous pouvons dépenser cent mille gaz en traitement l2. En supposant que nous n'écrasons pas le stockage, cela signifie que nous pouvons écrire environ cinq mots dans le stockage sur l2 pour le prix d'un gaz l1. Pour une seule preuve de Merkle, nous pouvons écrire l'intégralité des 1024 mots dans le stockage (en supposant qu'ils puissent être calculés onchain pour commencer, plutôt que fournis dans une transaction) et il nous restera encore la majeure partie du gaz.
Conclusion
Dans la vraie vie, vous n'implémenterez peut-être jamais d'arbres de Merkle vous-même. Il existe des bibliothèques bien connues et auditées que vous pouvez utiliser et, de manière générale, il est préférable de ne pas implémenter de primitives cryptographiques par vous-même. Mais j'espère que vous comprenez maintenant mieux les preuves de Merkle et que vous pouvez décider quand il vaut la peine de les utiliser.
Notez que bien que les preuves de Merkle préservent l'intégrité, elles ne préservent pas la disponibilité. Savoir que personne d'autre ne peut prendre vos actifs est une maigre consolation si le stockage de données décide d'interdire l'accès et que vous ne pouvez pas non plus construire un arbre de Merkle pour y accéder. Les arbres de Merkle sont donc mieux utilisés avec une sorte de stockage décentralisé, tel qu'IPFS.