오프체인 데이터 무결성을 위한 머클 증명
소개
이상적으로는 수천 대의 컴퓨터에 분산 저장되어 가용성(데이터를 검열할 수 없음)과 무결성(데이터를 무단으로 수정할 수 없음)이 매우 높은 이더리움 스토리지에 모든 것을 저장하고 싶지만, 32바이트 단어를 저장하는 데 일반적으로 20,000 가스가 듭니다. 이 글을 쓰는 시점에서 그 비용은 6.60달러에 해당합니다. 바이트당 21센트라는 비용은 많은 용도로 사용하기에는 너무 비쌉니다.
이 문제를 해결하기 위해 이더리움 생태계는 탈중앙화된 방식으로 데이터를 저장하는 다양한 대안을 개발했습니다. 일반적으로 이러한 방법은 가용성과 가격 사이의 절충안을 수반합니다. 하지만 무결성은 대개 보장됩니다.
이 글에서는 머클 증명 (새 탭에서 열림)을 사용하여 블록체인에 데이터를 저장하지 않고도 데이터 무결성을 보장하는 방법을 알아봅니다.
작동 방식
이론적으로는 데이터의 해시만 온체인에 저장하고, 이를 필요로 하는 트랜잭션에 모든 데이터를 보낼 수 있습니다. 하지만 이 방법 역시 너무 비쌉니다. 트랜잭션에 데이터를 추가할 때 바이트당 약 16 가스가 소모되며, 이는 현재 약 0.5센트, 킬로바이트당 약 5달러에 해당합니다. 메가바이트당 5,000달러라는 비용은 데이터를 해싱하는 추가 비용을 제외하더라도 많은 용도로 사용하기에는 여전히 너무 비쌉니다.
해결책은 데이터의 여러 하위 집합을 반복적으로 해싱하여, 전송할 필요가 없는 데이터에 대해서는 해시만 보내는 것입니다. 이는 각 노드가 그 아래에 있는 노드들의 해시로 이루어진 트리 데이터 구조인 머클 트리를 사용하여 수행합니다:
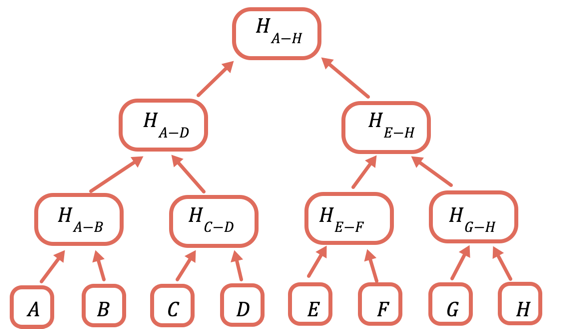
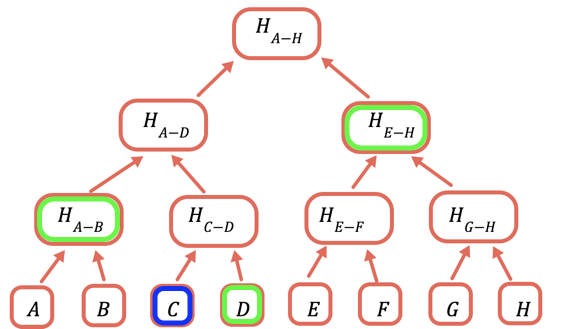
루트 해시는 온체인에 저장해야 하는 유일한 부분입니다. 특정 값을 증명하려면, 해당 값과 결합하여 루트를 얻는 데 필요한 모든 해시를 제공해야 합니다. 예를 들어, C를 증명하려면 D, H(A-B), 그리고 H(E-H)를 제공합니다.
구현
오프체인 코드
이 글에서는 오프체인 연산에 JavaScript를 사용합니다. 대부분의 탈중앙화 애플리케이션(dapp)은 오프체인 구성 요소를 JavaScript로 작성합니다.
머클 루트 생성
먼저 체인에 머클 루트를 제공해야 합니다.
const ethers = require("ethers")
ethers 패키지의 해시 함수를 사용합니다 (새 탭에서 열림).
// 무결성을 검증해야 하는 원시 데이터입니다. 처음 두 바이트는
// 사용자 식별자이며, 마지막 두 바이트는 사용자가
// 현재 소유하고 있는 토큰의 양입니다.
const dataArray = [
0x0bad0010, 0x60a70020, 0xbeef0030, 0xdead0040, 0xca110050, 0x0e660060,
0xface0070, 0xbad00080, 0x060d0091,
]
각 항목을 단일 256비트 정수로 인코딩하면 예를 들어 JSON을 사용하는 것보다 코드의 가독성이 떨어집니다. 하지만 이는 컨트랙트에서 데이터를 검색할 때 처리량이 훨씬 적어지므로 가스 비용이 크게 낮아짐을 의미합니다. 온체인에서 JSON을 읽을 수는 있지만 (새 탭에서 열림), 피할 수 있다면 사용하지 않는 것이 좋습니다.
// BigInt 형태의 해시 값 배열
const hashArray = dataArray
이 경우 데이터가 처음부터 256비트 값이므로 별도의 처리가 필요하지 않습니다. 문자열과 같이 더 복잡한 데이터 구조를 사용하는 경우, 먼저 데이터를 해싱하여 해시 배열을 얻어야 합니다. 이는 사용자가 다른 사용자의 정보를 알아도 상관없기 때문이기도 합니다. 그렇지 않다면 사용자 1이 사용자 0의 값을 모르고, 사용자 2가 사용자 3의 값을 모르게 하도록 해싱해야 했을 것입니다.
// 해시 함수가 예상하는 문자열과
// 다른 모든 곳에서 사용하는 BigInt 간에 변환합니다.
const hash = (x) =>
BigInt(ethers.utils.keccak256("0x" + x.toString(16).padStart(64, 0)))
ethers 해시 함수는 0x60A7와 같은 16진수 형태의 JavaScript 문자열을 입력받아 동일한 구조의 다른 문자열로 응답합니다. 하지만 나머지 코드에서는 BigInt를 사용하는 것이 더 쉬우므로, 16진수 문자열로 변환했다가 다시 되돌립니다.
// 순서가 뒤바뀌어도 상관없도록 쌍의 대칭 해시를 생성합니다.
const pairHash = (a, b) => hash(hash(a) ^ hash(b))
이 함수는 대칭적입니다(a xor (새 탭에서 열림) b의 해시). 즉, 머클 증명을 확인할 때 증명에서 가져온 값을 계산된 값의 앞이나 뒤 중 어디에 넣을지 걱정할 필요가 없습니다. 머클 증명 확인은 온체인에서 수행되므로, 그곳에서 해야 할 작업이 적을수록 좋습니다.
경고:
암호학은 보기보다 어렵습니다.
이 글의 초기 버전에는 hash(a^b)라는 해시 함수가 있었습니다.
이는 나쁜 아이디어였는데, a와 b의 합법적인 값을 알고 있다면 b' = a^b^a'를 사용하여 원하는 a' 값을 증명할 수 있었기 때문입니다.
이 함수를 사용하면 hash(a') ^ hash(b')가 알려진 값(루트로 가는 다음 분기)과 같아지도록 b'를 계산해야 하므로 훨씬 더 어렵습니다.
// 특정 브랜치가 비어 있고 값을
// 가지고 있지 않음을 나타내는 값
const empty = 0n
값의 개수가 2의 정수 거듭제곱이 아닌 경우 빈 분기를 처리해야 합니다. 이 프로그램에서는 0을 자리 표시자(placeholder)로 넣어 이를 처리합니다.
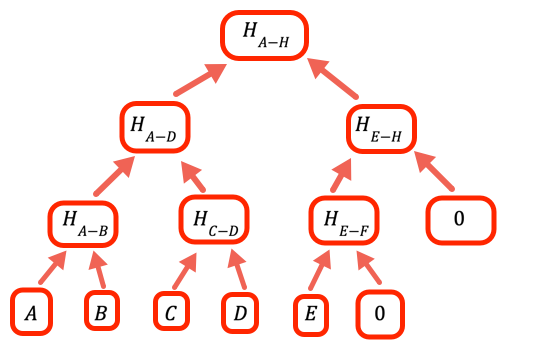
// 해시 배열 트리의 한 레벨 위를 계산하기 위해
// 순서대로 각 쌍의 해시를 취합니다
const oneLevelUp = (inputArray) => {
var result = []
var inp = [...inputArray] // 입력값을 덮어쓰는 것을 방지하기 위해 // 필요한 경우 빈 값을 추가합니다 (모든 리프는 // 쌍을 이루어야 합니다)
if (inp.length % 2 === 1) inp.push(empty)
for (var i = 0; i < inp.length; i += 2)
result.push(pairHash(inp[i], inp[i + 1]))
return result
} // oneLevelUp
이 함수는 현재 레이어에 있는 값의 쌍을 해싱하여 머클 트리에서 한 단계 "올라갑니다". 이것이 가장 효율적인 구현은 아니며, 입력 복사를 피하고 루프에서 적절할 때 hashEmpty를 추가할 수도 있었지만, 이 코드는 가독성을 위해 최적화되었습니다.
const getMerkleRoot = (inputArray) => {
var result
result = [...inputArray] // 값이 하나만 남을 때까지 트리를 올라갑니다. 이 값이 // 루트입니다. // // 레이어의 항목 수가 홀수인 경우 // oneLevelUp의 코드가 빈 값을 추가하므로, 예를 들어 // 10개의 리프가 있다면 두 번째 레이어에는 5개의 브랜치, 세 번째 레이어에는 3개의 // 브랜치, 네 번째 레이어에는 2개의 브랜치가 있고 루트는 다섯 번째가 됩니다.
while (result.length > 1) result = oneLevelUp(result)
return result[0]
}
루트를 얻으려면 값이 하나만 남을 때까지 올라갑니다.
머클 증명 생성
머클 증명은 머클 루트를 다시 얻기 위해 증명하려는 값과 함께 해싱할 값들입니다. 증명할 값은 종종 다른 데이터에서 얻을 수 있으므로, 코드의 일부로 포함하기보다는 별도로 제공하는 것을 선호합니다.
// 머클 증명은 함께 해시할 항목 목록의 값으로
// 구성됩니다. 대칭 해시 함수를 사용하기 때문에, 증명을 검증할 때는
// 항목의 위치가 필요하지 않으며, 증명을 생성할 때만 필요합니다
const getMerkleProof = (inputArray, n) => {
var result = [], currentLayer = [...inputArray], currentN = n
// 최상단에 도달할 때까지
while (currentLayer.length > 1) {
// 홀수 길이의 레이어는 없습니다
if (currentLayer.length % 2)
currentLayer.push(empty)
result.push(currentN % 2
// currentN이 홀수이면, 그 이전 값을 증명에 추가합니다
? currentLayer[currentN-1]
// 짝수이면, 그 이후 값을 추가합니다
: currentLayer[currentN+1])
우리는 (v[0],v[1]), (v[2],v[3]) 등을 해싱합니다. 따라서 짝수 값의 경우 다음 값이 필요하고, 홀수 값의 경우 이전 값이 필요합니다.
// 다음 상위 레이어로 이동합니다
currentN = Math.floor(currentN/2)
currentLayer = oneLevelUp(currentLayer)
} // while currentLayer.length > 1
return result
} // getMerkleProof
온체인 코드
마지막으로 증명을 확인하는 코드가 있습니다. 온체인 코드는 Solidity (새 탭에서 열림)로 작성되었습니다. 가스가 상대적으로 비싸기 때문에 여기서는 최적화가 훨씬 더 중요합니다.
//SPDX-License-Identifier: Public Domain
pragma solidity ^0.8.0;
import "hardhat/console.sol";
저는 개발 중에 Solidity에서 콘솔 출력 (새 탭에서 열림)을 할 수 있게 해주는 Hardhat 개발 환경 (새 탭에서 열림)을 사용하여 이를 작성했습니다.
contract MerkleProof {
uint merkleRoot;
function getRoot() public view returns (uint) {
return merkleRoot;
}
// 매우 안전하지 않으므로, 프로덕션 코드에서는 이 함수에 대한 접근을
// 엄격하게 제한해야 하며, 아마도 소유자(제한해야 합니다)로
// owner
function setRoot(uint _merkleRoot) external {
merkleRoot = _merkleRoot;
} // setRoot
머클 루트를 위한 설정(set) 및 가져오기(get) 함수입니다. 프로덕션 시스템에서 누구나 머클 루트를 업데이트할 수 있게 하는 것은 매우 나쁜 생각입니다. 여기서는 샘플 코드의 단순성을 위해 그렇게 했습니다. 데이터 무결성이 실제로 중요한 시스템에서는 이렇게 하지 마세요.
function hash(uint _a) internal pure returns(uint) {
return uint(keccak256(abi.encode(_a)));
}
function pairHash(uint _a, uint _b) internal pure returns(uint) {
return hash(hash(_a) ^ hash(_b));
}
이 함수는 쌍 해시를 생성합니다. 이는 hash 및 pairHash에 대한 JavaScript 코드를 Solidity로 번역한 것일 뿐입니다.
참고: 이것은 가독성을 위한 최적화의 또 다른 사례입니다. 함수 정의 (새 탭에서 열림)에 따르면, 데이터를 bytes32 (새 탭에서 열림) 값으로 저장하여 변환을 피할 수도 있습니다.
// 머클 증명 검증
function verifyProof(uint _value, uint[] calldata _proof)
public view returns (bool) {
uint temp = _value;
uint i;
for(i=0; i<_proof.length; i++) {
temp = pairHash(temp, _proof[i]);
}
return temp == merkleRoot;
}
} // MarkleProof
수학적 표기법으로 머클 증명 검증은 다음과 같습니다: H(proof_n, H(proof_n-1, H(proof_n-2, ... H(proof_1, H(proof_0, value))...))). 이 코드는 이를 구현합니다.
머클 증명과 롤업은 어울리지 않습니다
머클 증명은 롤업과 잘 맞지 않습니다. 그 이유는 롤업이 모든 트랜잭션 데이터를 레이어 1 (l1)에 기록하지만 처리는 레이어 2 (l2)에서 하기 때문입니다. 트랜잭션과 함께 머클 증명을 보내는 비용은 레이어당 평균 638 가스입니다(현재 콜 데이터의 1바이트는 0이 아니면 16 가스, 0이면 4 가스가 소모됩니다). 1024 단어의 데이터가 있는 경우, 머클 증명에는 10개의 레이어가 필요하며 총 6380 가스가 소모됩니다.
예를 들어 옵티미즘 (새 탭에서 열림)을 살펴보면, 레이어 1 (l1) 가스 기록 비용은 약 100 Gwei이고 레이어 2 (l2) 가스 비용은 0.001 Gwei입니다(이는 정상 가격이며 혼잡 시 상승할 수 있습니다). 따라서 레이어 1 (l1) 가스 1개의 비용으로 레이어 2 (l2) 처리에서 10만 가스를 사용할 수 있습니다. 스토리지를 덮어쓰지 않는다고 가정할 때, 이는 레이어 1 (l1) 가스 1개의 가격으로 레이어 2 (l2) 스토리지에 약 5개의 단어를 기록할 수 있음을 의미합니다. 단일 머클 증명의 경우, 전체 1024 단어를 스토리지에 기록하고도(트랜잭션에서 제공되는 것이 아니라 처음부터 온체인에서 계산할 수 있다고 가정할 때) 가스가 대부분 남게 됩니다.
결론
실제 환경에서는 머클 트리를 직접 구현할 일이 없을 수도 있습니다. 사용할 수 있는 잘 알려지고 감사받은 라이브러리들이 있으며, 일반적으로 암호학 원형(cryptographic primitives)을 직접 구현하지 않는 것이 가장 좋습니다. 하지만 이제 머클 증명을 더 잘 이해하고 언제 사용하는 것이 가치 있는지 결정할 수 있기를 바랍니다.
머클 증명은 무결성을 보존하지만 가용성을 보존하지는 않는다는 점에 유의하세요. 데이터 스토리지가 접근을 거부하기로 결정하고 접근을 위한 머클 트리를 구성할 수도 없다면, 다른 사람이 내 자산을 가져갈 수 없다는 사실은 작은 위안에 불과합니다. 따라서 머클 트리는 IPFS와 같은 일종의 탈중앙화된 스토리지와 함께 사용하는 것이 가장 좋습니다.