Dowody Merklego dla integralności danych offline
Wprowadzenie
Idealnie byłoby przechowywać wszystko w pamięci masowej Ethereum, która jest przechowywana na tysiącach komputerów i ma niezwykle wysoką dostępność (dane nie mogą być cenzurowane) i integralność (danych nie można modyfikować w nieautoryzowany sposób), ale przechowywanie 32-bajtowego słowa kosztuje zazwyczaj 20 000 jednostek gazu. W chwili pisania tego tekstu koszt ten odpowiada 6,60 USD. Przy cenie 21 centów za bajt jest to zbyt drogie dla wielu zastosowań.
Aby rozwiązać ten problem, ekosystem Ethereum opracował wiele alternatywnych sposobów przechowywania danych w zdecentralizowany sposób Zazwyczaj wiążą się one z kompromisem między dostępnością a ceną. Jednak integralność jest zazwyczaj zapewniona.
W tym artykule dowiesz się, jak zapewnić integralność danych bez przechowywania ich na blockchainie, używając dowodów Merklego (opens in a new tab).
Jak to działa?
Teoretycznie moglibyśmy po prostu przechowywać hasz danych w łańcuchu i wysyłać wszystkie dane w transakcjach, które ich wymagają. Jest to jednak nadal zbyt drogie. Bajt danych w transakcji kosztuje około 16 jednostek gazu, obecnie około pół centa, czyli około 5 USD za kilobajt. Przy cenie 5000 USD za megabajt jest to wciąż zbyt drogie dla wielu zastosowań, nawet bez dodatkowego kosztu haszowania danych.
Rozwiązaniem jest wielokrotne haszowanie różnych podzbiorów danych, dzięki czemu dla danych, których nie trzeba wysyłać, można po prostu wysłać hasz. Robisz to za pomocą drzewa Merklego, struktury danych w formie drzewa, w której każdy węzeł jest haszem węzłów znajdujących się pod nim:
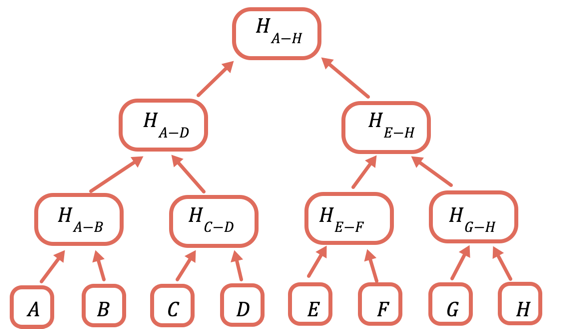
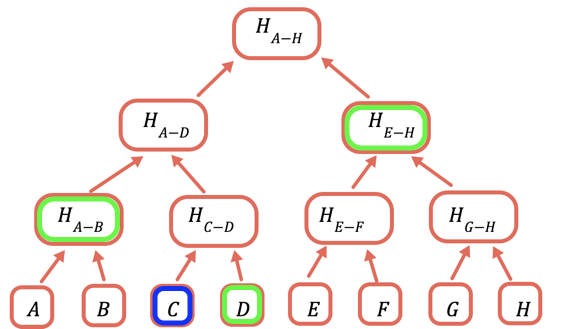
Hasz główny jest jedyną częścią, która musi być przechowywana w łańcuchu. Aby udowodnić określoną wartość, należy podać wszystkie hasze, które należy z nią połączyć, aby uzyskać hasz główny. Na przykład, aby udowodnić C, podajesz D, H(A-B) i H(E-H).
Implementacja
Przykładowy kod jest dostępny tutaj (opens in a new tab).
Kod off-chain
W tym artykule używamy JavaScript do obliczeń off-chain. Większość aplikacji zdecentralizowanych ma swój komponent off-chain napisany w JavaScript.
Tworzenie haszu głównego Merkle
Najpierw musimy dostarczyć hasz główny Merkle do łańcucha.
1const ethers = require("ethers")Używamy funkcji haszującej z pakietu ethers (opens in a new tab).
1// Surowe dane, których integralność musimy zweryfikować. Pierwsze dwa bajty2// to identyfikator użytkownika, a ostatnie dwa bajty to ilość tokenów, które3// użytkownik aktualnie posiada.4const dataArray = [5 0x0bad0010, 0x60a70020, 0xbeef0030, 0xdead0040, 0xca110050, 0x0e660060,6 0xface0070, 0xbad00080, 0x060d0091,7]Kodowanie każdego wpisu w pojedynczą 256-bitową liczbę całkowitą skutkuje mniej czytelnym kodem niż na przykład użycie formatu JSON. Oznacza to jednak znacznie mniej przetwarzania w celu pobrania danych w kontrakcie, a więc znacznie niższe koszty gazu. Można odczytywać JSON w łańcuchu (opens in a new tab), ale jest to zły pomysł, jeśli można go uniknąć.
1// Tablica wartości haszy jako BigInts2const hashArray = dataArrayW tym przypadku nasze dane to na początek wartości 256-bitowe, więc nie jest potrzebne żadne przetwarzanie. Jeśli użyjemy bardziej skomplikowanej struktury danych, takiej jak ciągi znaków, musimy najpierw zhaszować dane, aby uzyskać tablicę haszy. Należy zauważyć, że dzieje się tak również dlatego, że nie zależy nam na tym, aby użytkownicy znali informacje o innych użytkownikach. W przeciwnym razie musielibyśmy haszować, aby użytkownik 1 nie znał wartości dla użytkownika 0, użytkownik 2 nie znał wartości dla użytkownika 3 itd.
1// Konwertuj między ciągiem znaków, którego oczekuje funkcja haszująca, a2// BigInt, którego używamy wszędzie indziej.3const hash = (x) =>4 BigInt(ethers.utils.keccak256("0x" + x.toString(16).padStart(64, 0)))Funkcja haszująca ethers oczekuje ciągu znaków JavaScript z liczbą szesnastkową, taką jak 0x60A7, i odpowiada innym ciągiem o tej samej strukturze. Jednak w pozostałej części kodu łatwiej jest użyć BigInt, więc konwertujemy do ciągu szesnastkowego i z powrotem.
1// Symetryczny hasz pary, więc nie będziemy się przejmować, jeśli kolejność zostanie odwrócona.2const pairHash = (a, b) => hash(hash(a) ^ hash(b))Ta funkcja jest symetryczna (hasz a xor (opens in a new tab) b). Oznacza to, że sprawdzając dowód Merklego, nie musimy się martwić o to, czy umieścić wartość z dowodu przed czy po obliczonej wartości. Sprawdzanie dowodu Merklego odbywa się w łańcuchu, więc im mniej musimy tam robić, tym lepiej.
Ostrzeżenie:
Kryptografia jest trudniejsza, niż się wydaje.
Początkowa wersja tego artykułu zawierała funkcję haszującą hash(a^b).
To był zły pomysł, ponieważ oznaczał, że jeśli znałeś prawidłowe wartości a i b, mogłeś użyć b' = a^b^a', aby udowodnić dowolną pożądaną wartość a'.
Dzięki tej funkcji trzeba by obliczyć b' tak, aby hash(a') ^ hash(b') było równe znanej wartości (następnej gałęzi w drodze do haszu głównego), co jest o wiele trudniejsze.
1// Wartość oznaczająca, że dana gałąź jest pusta, nie2// ma wartości3const empty = 0nGdy liczba wartości nie jest całkowitą potęgą dwójki, musimy obsłużyć puste gałęzie. Sposób, w jaki ten program to robi, polega na umieszczeniu zera jako symbolu zastępczego.
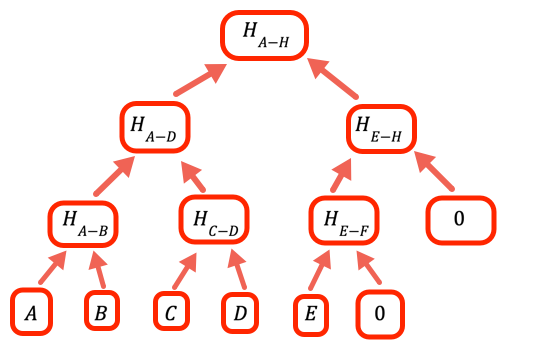
1// Oblicz jeden poziom w górę drzewa tablicy haszy, biorąc hasz2// każdej pary w sekwencji3const oneLevelUp = (inputArray) => {4 var result = []5 var inp = [...inputArray] // Aby uniknąć nadpisywania danych wejściowych // Dodaj pustą wartość, jeśli to konieczne (musimy, aby wszystkie liście były // sparowane)67 if (inp.length % 2 === 1) inp.push(empty)89 for (var i = 0; i < inp.length; i += 2)10 result.push(pairHash(inp[i], inp[i + 1]))1112 return result13} // oneLevelUpPokaż wszystkoTa funkcja „wspina się” o jeden poziom w drzewie Merklego, haszując pary wartości na bieżącej warstwie. Należy zauważyć, że nie jest to najbardziej wydajna implementacja, mogliśmy uniknąć kopiowania danych wejściowych i po prostu dodać hashEmpty w odpowiednim momencie w pętli, ale ten kod jest zoptymalizowany pod kątem czytelności.
1const getMerkleRoot = (inputArray) => {2 var result34 result = [...inputArray] // Wspinaj się po drzewie, aż zostanie tylko jedna wartość, czyli // hasz główny. // // Jeśli warstwa ma nieparzystą liczbę wpisów, // kod w oneLevelUp dodaje pustą wartość, więc jeśli mamy, na przykład, // 10 liści, będziemy mieli 5 gałęzi w drugiej warstwie, 3 // gałęzie w trzeciej, 2 w czwartej, a hasz główny jest piąty56 while (result.length > 1) result = oneLevelUp(result)78 return result[0]9}Pokaż wszystkoAby uzyskać hasz główny, wspinaj się, aż zostanie tylko jedna wartość.
Tworzenie dowodu Merklego
Dowód Merklego to wartości, które należy zhaszować wraz z udowadnianą wartością, aby otrzymać hasz główny Merkle. Wartość do udowodnienia jest często dostępna z innych danych, więc wolę podawać ją osobno, a nie jako część kodu.
1// Dowód Merklego składa się z wartości listy wpisów do2// zhaszowania. Ponieważ używamy symetrycznej funkcji haszującej, nie3// potrzebujemy lokalizacji elementu, aby zweryfikować dowód, a jedynie, aby go utworzyć4const getMerkleProof = (inputArray, n) => {5 var result = [], currentLayer = [...inputArray], currentN = n67 // Aż dotrzemy na szczyt8 while (currentLayer.length > 1) {9 // Brak warstw o nieparzystej długości10 if (currentLayer.length % 2)11 currentLayer.push(empty)1213 result.push(currentN % 214 // Jeśli currentN jest nieparzyste, dodaj do dowodu wartość przed nim15 ? currentLayer[currentN-1]16 // Jeśli jest parzyste, dodaj wartość po nim17 : currentLayer[currentN+1])18Pokaż wszystkoHaszujemy (v[0],v[1]), (v[2],v[3]), itd. Tak więc dla wartości parzystych potrzebujemy następnej, a dla nieparzystych poprzedniej.
1 // Przejdź do następnej warstwy w górę2 currentN = Math.floor(currentN/2)3 currentLayer = oneLevelUp(currentLayer)4 } // while currentLayer.length > 156 return result7} // getMerkleProofKod on-chain
Na koniec mamy kod, który sprawdza dowód. Kod on-chain jest napisany w Solidity (opens in a new tab). Optymalizacja jest tutaj o wiele ważniejsza, ponieważ gaz jest stosunkowo drogi.
1//SPDX-License-Identifier: Public Domain2pragma solidity ^0.8.0;34import "hardhat/console.sol";Napisałem to przy użyciu środowiska programistycznego Hardhat (opens in a new tab), które pozwala nam uzyskać dane wyjściowe konsoli z Solidity (opens in a new tab) podczas programowania.
12contract MerkleProof {3 uint merkleRoot;45 function getRoot() public view returns (uint) {6 return merkleRoot;7 }89 // Wyjątkowo niezabezpieczone, w kodzie produkcyjnym dostęp do10 // tej funkcji MUSI być ściśle ograniczony, prawdopodobnie do11 // właściciela12 function setRoot(uint _merkleRoot) external {13 merkleRoot = _merkleRoot;14 } // setRootPokaż wszystkoFunkcje set i get dla korzenia Merkle. Zezwalanie wszystkim na aktualizację korzenia Merkle jest wyjątkowo złym pomysłem w systemie produkcyjnym. Robię to tutaj dla uproszczenia przykładowego kodu. Nie rób tego w systemie, w którym integralność danych ma faktycznie znaczenie.
1 function hash(uint _a) internal pure returns(uint) {2 return uint(keccak256(abi.encode(_a)));3 }45 function pairHash(uint _a, uint _b) internal pure returns(uint) {6 return hash(hash(_a) ^ hash(_b));7 }Ta funkcja generuje hasz pary. Jest to po prostu tłumaczenie kodu JavaScript dla hash i pairHash na język Solidity.
Uwaga: To kolejny przypadek optymalizacji pod kątem czytelności. W oparciu o definicję funkcji (opens in a new tab) możliwe może być przechowywanie danych jako wartości bytes32 (opens in a new tab) i uniknięcie konwersji.
1 // Weryfikacja dowodu Merkle2 function verifyProof(uint _value, uint[] calldata _proof)3 public view returns (bool) {4 uint temp = _value;5 uint i;67 for(i=0; i<_proof.length; i++) {8 temp = pairHash(temp, _proof[i]);9 }1011 return temp == merkleRoot;12 }1314} // MarkleProofPokaż wszystkoW notacji matematycznej weryfikacja dowodu Merkle wygląda następująco: H(proof_n, H(proof_n-1, H(proof_n-2, ... H(proof_1, H(proof_0, value))...)))`. Ten kod to implementuje.
Dowody Merkle i pakiety zbiorcze nie idą w parze
Dowody Merkle nie działają dobrze z pakietami zbiorczymi. Powodem jest to, że pakiety zbiorcze zapisują wszystkie dane transakcji na L1, ale przetwarzają je na L2. Koszt wysłania dowodu Merkle z transakcją wynosi średnio 638 jednostek gazu na warstwę (obecnie bajt w danych wywołania kosztuje 16 jednostek gazu, jeśli nie jest zerem, i 4, jeśli jest zerem). Jeśli mamy 1024 słów danych, dowód Merkle wymaga dziesięciu warstw, czyli łącznie 6380 jednostek gazu.
Patrząc na przykład na Optimism (opens in a new tab), koszt gazu za zapis na L1 wynosi około 100 gwei, a koszt gazu na L2 – 0,001 gwei (to normalna cena, może wzrosnąć w przypadku przeciążenia). Tak więc za koszt jednej jednostki gazu L1 możemy wydać sto tysięcy jednostek gazu na przetwarzanie na L2. Zakładając, że nie nadpisujemy przestrzeni do przechowywania, oznacza to, że możemy zapisać około pięciu słów w przestrzeni do przechowywania na L2 za cenę jednej jednostki gazu L1. Dla pojedynczego dowodu Merkle możemy zapisać całe 1024 słowa do przestrzeni do przechowywania (zakładając, że mogą być one obliczone na łańcuchu (on-chain), a nie podane w transakcji) i nadal pozostanie nam większość gazu.
Wnioski
W prawdziwym życiu możesz nigdy nie zaimplementować drzew Merkle samodzielnie. Istnieją dobrze znane i sprawdzone biblioteki, których można używać, i ogólnie rzecz biorąc, najlepiej nie wdrażać samodzielnie prymitywów kryptograficznych. Mam jednak nadzieję, że teraz lepiej rozumiesz dowody Merkle i możesz zdecydować, kiedy warto ich używać.
Należy pamiętać, że chociaż dowody Merkle zachowują integralność, nie zachowują dostępności. Świadomość, że nikt inny nie może zabrać Twoich aktywów, jest niewielkim pocieszeniem, jeśli system przechowywania danych zdecyduje się zablokować dostęp, a Ty również nie możesz skonstruować drzewa Merkle, aby uzyskać do nich dostęp. Dlatego drzewa Merkle najlepiej stosować z jakimś rodzajem zdecentralizowanej przestrzeni do przechowywania, takiej jak IPFS.
Zobacz więcej mojej pracy tutaj (opens in a new tab).
Strona ostatnio zaktualizowana: 18 grudnia 2025


