Le protocole Ethereum subit sa plus importante mise à jour de mise à l'échelle depuis l'introduction des transactions de blobs avec l'EIP-4844. Dans le cadre de la mise à jour Fusaka, PeerDAS introduit une nouvelle façon de gérer les données de blobs, offrant une augmentation d'environ un ordre de grandeur de la capacité de disponibilité des données (DA) pour les couches 2 (l2).
En savoir plus sur la feuille de route de mise à l'échelle des blobs (s'ouvre dans un nouvel onglet)
Mise à l'échelle
La vision d'Ethereum est d'être une plateforme neutre, sécurisée et décentralisée, accessible à tous dans le monde. À mesure que l'utilisation du réseau augmente, cela nécessite d'équilibrer le trilemme de la mise à l'échelle, de la sécurité et de la décentralisation du réseau. Si Ethereum augmentait simplement les données gérées par le réseau dans sa conception actuelle, il courrait le risque de surcharger les nœuds sur lesquels Ethereum s'appuie pour sa décentralisation. La mise à l'échelle nécessite une conception de mécanisme rigoureuse qui minimise les compromis.
L'une des stratégies pour atteindre cet objectif est de permettre un écosystème diversifié de solutions de mise à l'échelle de couche 2 plutôt que de traiter toutes les transactions sur le Réseau principal de . Les ou les rollups traitent les transactions sur leurs propres chaînes séparées et utilisent Ethereum pour la vérification et la sécurité. La publication uniquement des engagements critiques pour la sécurité et la compression des charges utiles permettent aux l2 d'utiliser la capacité de DA d'Ethereum plus efficacement. En retour, la l1 transporte moins de données sans compromettre les garanties de sécurité, tandis que les l2 intègrent plus d'utilisateurs à des coûts de gaz inférieurs. Initialement, les l2 publiaient des données sous forme de calldata dans des transactions ordinaires, ce qui concurrençait les transactions de la l1 pour le gaz et n'était pas pratique pour la disponibilité des données en masse.
proto-danksharding
La première étape majeure vers la mise à l'échelle des l2 a été la mise à jour Dencun, qui a introduit le proto-danksharding (EIP-4844). Cette mise à jour a créé un nouveau type de données spécialisé pour les rollups appelé blobs. Les blobs, ou objets binaires volumineux (binary large objects), sont des éléments éphémères de données arbitraires qui ne nécessitent pas d'exécution EVM et que les nœuds ne stockent que pour une durée limitée. Ce traitement plus efficace a permis aux l2 de publier plus de données sur Ethereum et de se mettre à l'échelle encore davantage.
Bien qu'elle présente déjà de solides avantages pour la mise à l'échelle, l'utilisation de blobs n'est qu'une partie de l'objectif final. Dans le protocole actuel, chaque nœud du réseau doit encore télécharger chaque blob. Le goulot d'étranglement devient la bande passante requise pour les nœuds individuels, la quantité de données à télécharger augmentant directement avec le nombre de blobs.
Ethereum ne fait aucun compromis sur la décentralisation, et la bande passante est l'un des paramètres les plus sensibles. Même avec une puissance de calcul largement disponible pour quiconque peut se le permettre, les limitations de bande passante montante (s'ouvre dans un nouvel onglet), même dans les villes très urbaines des pays développés (comme l'Allemagne (s'ouvre dans un nouvel onglet), la Belgique (s'ouvre dans un nouvel onglet), l'Australie (s'ouvre dans un nouvel onglet) ou les États-Unis (s'ouvre dans un nouvel onglet)), pourraient restreindre les nœuds à ne pouvoir fonctionner qu'à partir de centres de données si les exigences en matière de bande passante ne sont pas soigneusement ajustées.
Les opérateurs de nœuds ont des exigences de plus en plus élevées en matière de bande passante et d'espace disque à mesure que les blobs augmentent. La taille et la quantité des blobs sont limitées par ces contraintes. Chaque blob peut transporter jusqu'à 128 ko de données avec une moyenne de 6 blobs par bloc. Ce n'était que la première étape vers une conception future qui utilise les blobs de manière encore plus efficace.
Échantillonnage de la disponibilité des données
La disponibilité des données est la garantie que toutes les données nécessaires pour valider indépendamment la chaîne sont accessibles à tous les participants du réseau. Elle garantit que les données ont été entièrement publiées et peuvent être utilisées pour vérifier sans confiance le nouvel état de la chaîne ou les transactions entrantes.
Les blobs Ethereum fournissent une forte garantie de disponibilité des données qui assure la sécurité des l2. Pour ce faire, les nœuds Ethereum doivent télécharger et stocker les blobs dans leur intégralité. Mais que se passerait-il si nous pouvions distribuer les blobs sur le réseau plus efficacement et éviter cette limitation ?
Une approche différente pour stocker les données et garantir leur disponibilité est l'échantillonnage de la disponibilité des données (DAS). Au lieu que chaque ordinateur qui exécute Ethereum stocke entièrement chaque blob, le DAS introduit une division décentralisée du travail. Il allège le fardeau du traitement des données en répartissant des tâches plus petites et gérables sur l'ensemble du réseau de nœuds. Les blobs sont divisés en morceaux et chaque nœud ne télécharge que quelques morceaux en utilisant un mécanisme de distribution aléatoire uniforme sur tous les nœuds.
Cela introduit un nouveau problème : prouver la disponibilité et l'intégrité des données. Comment le réseau peut-il garantir que les données sont disponibles et qu'elles sont toutes correctes lorsque les nœuds individuels ne détiennent que de petits morceaux ? Un nœud malveillant pourrait fournir de fausses données et briser facilement les fortes garanties de disponibilité des données ! C'est là que la cryptographie vient à la rescousse.
Pour garantir l'intégrité des données, l'EIP-4844 a déjà été implémenté avec des engagements KZG. Ce sont des preuves cryptographiques créées lorsqu'un nouveau blob est ajouté au réseau. Une petite preuve est incluse dans chaque bloc, et les nœuds peuvent vérifier que les blobs reçus correspondent à l'engagement KZG du bloc.
Le DAS est un mécanisme qui s'appuie sur cela et garantit que les données sont à la fois correctes et disponibles. L'échantillonnage est un processus par lequel un nœud n'interroge qu'une petite partie des données et la vérifie par rapport à l'engagement. KZG est un schéma d'engagement polynomial, ce qui signifie que n'importe quel point unique sur la courbe polynomiale peut être vérifié. En ne vérifiant que quelques points sur le polynôme, le client effectuant l'échantillonnage peut avoir une forte garantie probabiliste que les données sont disponibles.
PeerDAS
PeerDAS (EIP-7594) (s'ouvre dans un nouvel onglet) est une proposition spécifique qui implémente le mécanisme DAS dans Ethereum, marquant probablement la plus grande mise à jour depuis La Fusion. PeerDAS est conçu pour étendre les données de blobs, en les divisant en colonnes et en distribuant un sous-ensemble aux nœuds.
Ethereum emprunte des mathématiques astucieuses pour y parvenir : il applique un codage d'effacement de type Reed-Solomon aux données de blobs. Les données de blobs sont représentées comme un polynôme dont les coefficients encodent les données, puis évaluent ce polynôme à des points supplémentaires pour créer un blob étendu, doublant ainsi le nombre d'évaluations. Cette redondance ajoutée permet la récupération par effacement : même si certaines évaluations manquent, le blob d'origine peut être reconstruit tant qu'au moins la moitié des données totales, y compris les morceaux étendus, sont disponibles.
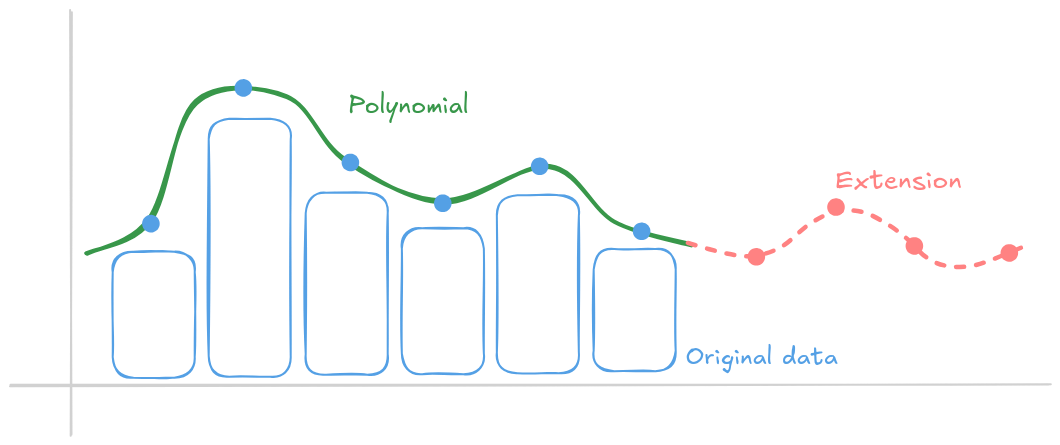
En réalité, ce polynôme a des milliers de coefficients. Les engagements KZG sont des valeurs de quelques octets, un peu comme un hash, connues de tous les nœuds. Chaque nœud détenant suffisamment de points de données peut reconstruire efficacement un ensemble complet de données de blobs (s'ouvre dans un nouvel onglet).
Fait amusant : la même technique de codage était utilisée par les DVD. Si vous rayiez un DVD, le lecteur était toujours capable de le lire grâce au codage Reed-Solomon qui ajoute les morceaux manquants du polynôme.
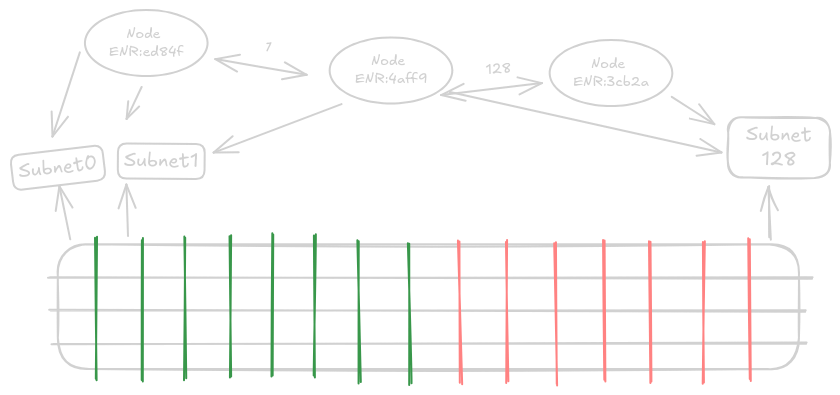
Historiquement, les données dans les blockchains, qu'il s'agisse de blocs ou de blobs, étaient diffusées à tous les nœuds. Avec l'approche de division et d'échantillonnage de PeerDAS, il n'est plus nécessaire de tout diffuser à tout le monde. Après Fusaka, la mise en réseau de la couche de consensus est organisée en sujets/sous-réseaux de protocole de commérage : les colonnes de blobs sont assignées à des sous-réseaux spécifiques, et chaque nœud s'abonne à des sous-ensembles prédéterminés et ne conserve que ces morceaux.
Avec PeerDAS, les données de blobs étendues sont divisées en 128 morceaux appelés colonnes. Les données sont distribuées à ces nœuds via un protocole de commérage dédié sur des sous-réseaux spécifiques auxquels ils s'abonnent. Chaque nœud régulier sur le réseau participe à au moins 8 sous-réseaux de colonnes choisis au hasard. Recevoir des données de seulement 8 des 128 sous-réseaux signifie que ce nœud par défaut ne reçoit que 1/16 de toutes les données, mais comme les données ont été étendues, cela représente 1/8 des données d'origine.
Cela permet une nouvelle limite théorique de mise à l'échelle de 8 fois le schéma actuel où « tout le monde télécharge tout ». Avec des nœuds s'abonnant à différents sous-réseaux aléatoires servant des colonnes de blobs, la probabilité est très élevée qu'ils soient uniformément distribués et donc que chaque morceau de données existe quelque part dans le réseau. Les nœuds exécutant des validateurs sont tenus de s'abonner à plus de sous-réseaux avec chaque validateur qu'ils exécutent.
Chaque nœud possède un identifiant unique généré aléatoirement, qui sert normalement d'identité publique pour les connexions. Dans PeerDAS, ce nombre est utilisé pour déterminer l'ensemble aléatoire de sous-réseaux auxquels il doit s'abonner, ce qui entraîne une distribution aléatoire uniforme de toutes les données de blobs.
Une fois qu'un nœud a réussi à reconstruire les données d'origine, il redistribue ensuite les colonnes récupérées dans le réseau, comblant activement les lacunes de données et améliorant la résilience globale du système. Les nœuds connectés à des validateurs avec un solde combiné ≥ 4096 ETH doivent être un supernœud et doivent donc s'abonner à tous les sous-réseaux de colonnes de données et conserver toutes les colonnes. Ces supernœuds combleront continuellement les lacunes de données. La nature probabiliste d'auto-guérison du protocole permet de fortes garanties de disponibilité tout en ne limitant pas les opérateurs à domicile qui ne détiennent que des portions des données.
La disponibilité des données peut être confirmée par n'importe quel nœud ne détenant qu'un petit sous-ensemble des données de blobs grâce au mécanisme d'échantillonnage décrit ci-dessus. Cette disponibilité est appliquée : les validateurs doivent suivre de nouvelles règles de choix de fork, ce qui signifie qu'ils n'accepteront et ne voteront pour des blocs qu'après avoir vérifié la disponibilité des données.
L'impact direct sur les utilisateurs (en particulier les utilisateurs de l2) est une baisse des frais. Avec 8 fois plus d'espace pour les données de rollup, les opérations des utilisateurs sur leur chaîne deviennent encore moins chères avec le temps. Mais la baisse des frais après Fusaka prendra du temps et dépendra des BPO.
Blob-Parameter-Only (BPO)
Le réseau sera théoriquement capable de traiter 8 fois plus de blobs, mais les augmentations de blobs sont un changement qui doit être correctement testé et exécuté en toute sécurité de manière progressive. Les réseaux de test fournissent suffisamment de confiance pour déployer les fonctionnalités sur le Réseau principal, mais nous devons assurer la stabilité du réseau p2p avant d'activer un nombre significativement plus élevé de blobs.
Pour augmenter progressivement le nombre cible de blobs par bloc sans surcharger le réseau, Fusaka introduit les forks Blob-Parameter-Only (BPO) (s'ouvre dans un nouvel onglet). Contrairement aux forks réguliers qui nécessitent une large coordination de l'écosystème, un accord et des mises à jour logicielles, les BPO (EIP-7892) (s'ouvre dans un nouvel onglet) sont des mises à jour préprogrammées qui augmentent le nombre maximum de blobs au fil du temps sans intervention.
Cela signifie qu'immédiatement après l'activation de Fusaka et le lancement de PeerDAS, le nombre de blobs restera inchangé. Le nombre de blobs commencera à doubler toutes les quelques semaines jusqu'à atteindre un maximum de 48, tandis que les développeurs surveilleront pour s'assurer que le mécanisme fonctionne comme prévu et n'a pas d'effets indésirables sur les nœuds exécutant le réseau.
Orientations futures
PeerDAS n'est qu'une étape vers une vision de mise à l'échelle plus large de FullDAS (s'ouvre dans un nouvel onglet), ou danksharding. Alors que PeerDAS utilise un codage d'effacement 1D pour chaque blob individuellement, le danksharding complet utilisera un schéma de codage d'effacement 2D plus complet sur l'ensemble de la matrice de données de blobs. L'extension des données en deux dimensions crée des propriétés de redondance encore plus fortes et une reconstruction et une vérification plus efficaces. La réalisation de FullDAS nécessitera des optimisations substantielles du réseau et du protocole, ainsi que des recherches supplémentaires.
Complément d'information
- PeerDAS : Échantillonnage de la disponibilité des données par les pairs par Francesco D'Amato (s'ouvre dans un nouvel onglet)
- Une documentation sur le PeerDAS d'Ethereum (s'ouvre dans un nouvel onglet)
- Prouver la sécurité de PeerDAS sans l'AGM (s'ouvre dans un nouvel onglet)
- Vitalik sur PeerDAS, son impact et les tests de Fusaka (s'ouvre dans un nouvel onglet)