Jak używać narzędzia Slither do znajdowania błędów w inteligentnych kontraktach
Jak używać narzędzia Slither
Celem tego samouczka jest pokazanie, jak używać narzędzia Slither do automatycznego znajdowania błędów w inteligentnych kontraktach.
- Instalacja
- Użycie wiersza poleceń
- Wprowadzenie do analizy statycznej: Krótkie wprowadzenie do analizy statycznej
- API: Opis API w języku Python
Instalacja
Slither wymaga języka Python w wersji >= 3.6. Można go zainstalować za pomocą pip lub używając narzędzia Docker.
Instalacja Slither przez pip:
pip3 install --user slither-analyzer
Instalacja Slither przez Docker:
docker pull trailofbits/eth-security-toolbox
docker run -it -v "$PWD":/home/trufflecon trailofbits/eth-security-toolbox
Ostatnie polecenie uruchamia eth-security-toolbox w kontenerze Docker, który ma dostęp do Twojego bieżącego katalogu. Możesz zmieniać pliki na swoim hoście i uruchamiać narzędzia na plikach z poziomu Dockera.
Wewnątrz Dockera uruchom:
solc-select 0.5.11
cd /home/trufflecon/
Uruchamianie skryptu
Aby uruchomić skrypt w języku Python za pomocą Python 3:
python3 script.py
Wiersz poleceń
Wiersz poleceń a skrypty zdefiniowane przez użytkownika. Slither jest dostarczany z zestawem predefiniowanych detektorów, które znajdują wiele typowych błędów. Wywołanie narzędzia Slither z wiersza poleceń uruchomi wszystkie detektory, bez konieczności posiadania szczegółowej wiedzy na temat analizy statycznej:
slither project_paths
Oprócz detektorów, Slither posiada możliwości przeglądu kodu dzięki swoim modułom wypisywania (printers) (otwiera się w nowej karcie) i narzędziom (otwiera się w nowej karcie).
Użyj crytic.io (otwiera się w nowej karcie), aby uzyskać dostęp do prywatnych detektorów i integracji z GitHub.
Analiza statyczna
Możliwości i projekt frameworka do analizy statycznej Slither zostały opisane we wpisach na blogu (1 (otwiera się w nowej karcie), 2 (otwiera się w nowej karcie)) oraz w artykule naukowym (otwiera się w nowej karcie).
Analiza statyczna występuje w różnych odmianach. Prawdopodobnie zdajesz sobie sprawę, że kompilatory takie jak clang (otwiera się w nowej karcie) i gcc (otwiera się w nowej karcie) opierają się na tych technikach badawczych, ale stanowią one również podstawę dla narzędzi takich jak Infer (otwiera się w nowej karcie), CodeClimate (otwiera się w nowej karcie), FindBugs (otwiera się w nowej karcie) oraz narzędzi opartych na metodach formalnych, takich jak Frama-C (otwiera się w nowej karcie) i Polyspace (otwiera się w nowej karcie).
Nie będziemy tutaj wyczerpująco omawiać technik analizy statycznej ani badań. Zamiast tego skupimy się na tym, co jest potrzebne do zrozumienia, jak działa Slither, abyś mógł skuteczniej używać go do znajdowania błędów i rozumienia kodu.
Reprezentacja kodu
W przeciwieństwie do analizy dynamicznej, która wnioskuje o pojedynczej ścieżce wykonania, analiza statyczna wnioskuje o wszystkich ścieżkach jednocześnie. Aby to zrobić, opiera się na innej reprezentacji kodu. Dwie najpopularniejsze to drzewo składni abstrakcyjnej (AST - Abstract Syntax Tree) i graf przepływu sterowania (CFG - Control Flow Graph).
Drzewa składni abstrakcyjnej (AST)
AST są używane za każdym razem, gdy kompilator parsuje kod. Jest to prawdopodobnie najbardziej podstawowa struktura, na której można przeprowadzić analizę statyczną.
W skrócie, AST to ustrukturyzowane drzewo, w którym zazwyczaj każdy liść zawiera zmienną lub stałą, a węzły wewnętrzne to operandy lub operacje przepływu sterowania. Rozważmy następujący kod:
function safeAdd(uint a, uint b) pure internal returns(uint){
if(a + b <= a){
revert();
}
return a + b;
}
Odpowiadające mu AST pokazano poniżej:
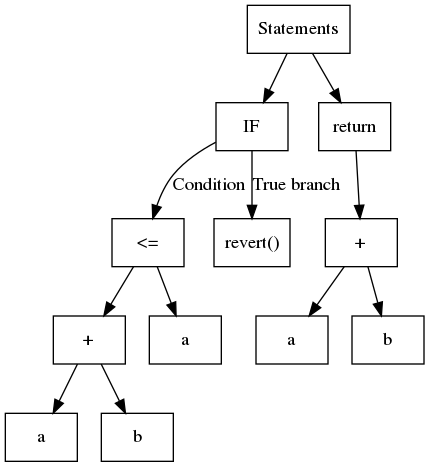
Slither używa AST wyeksportowanego przez solc.
Choć proste w budowie, AST jest strukturą zagnieżdżoną. Czasami nie jest to najprostsze do analizy. Na przykład, aby zidentyfikować operacje użyte w wyrażeniu a + b <= a, musisz najpierw przeanalizować <=, a następnie +. Powszechnym podejściem jest użycie tak zwanego wzorca odwiedzającego (visitor pattern), który rekurencyjnie porusza się po drzewie. Slither zawiera ogólnego odwiedzającego w ExpressionVisitor (otwiera się w nowej karcie).
Poniższy kod używa ExpressionVisitor do wykrycia, czy wyrażenie zawiera dodawanie:
from slither.visitors.expression.expression import ExpressionVisitor
from slither.core.expressions.binary_operation import BinaryOperationType
class HasAddition(ExpressionVisitor):
def result(self):
return self._result
def _post_binary_operation(self, expression):
if expression.type == BinaryOperationType.ADDITION:
self._result = True
visitor = HasAddition(expression) # expression jest wyrażeniem do przetestowania
print(f'The expression {expression} has a addition: {visitor.result()}')
Graf przepływu sterowania (CFG)
Drugą najpopularniejszą reprezentacją kodu jest graf przepływu sterowania (CFG). Jak sama nazwa wskazuje, jest to reprezentacja oparta na grafie, która ujawnia wszystkie ścieżki wykonania. Każdy węzeł zawiera jedną lub wiele instrukcji. Krawędzie w grafie reprezentują operacje przepływu sterowania (if/then/else, pętle itp.). CFG naszego poprzedniego przykładu to:
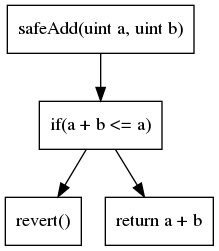
CFG to reprezentacja, na której opiera się większość analiz.
Istnieje wiele innych reprezentacji kodu. Każda z nich ma swoje zalety i wady w zależności od analizy, którą chcesz przeprowadzić.
Analiza
Najprostszym rodzajem analiz, jakie można przeprowadzić za pomocą narzędzia Slither, są analizy składniowe.
Analiza składniowa
Slither może poruszać się po różnych komponentach kodu i ich reprezentacji, aby znaleźć niespójności i wady, używając podejścia podobnego do dopasowywania wzorców.
Na przykład poniższe detektory szukają problemów związanych ze składnią:
-
Przesłanianie zmiennych stanu (State variable shadowing) (otwiera się w nowej karcie): iteruje po wszystkich zmiennych stanu i sprawdza, czy którakolwiek z nich przesłania zmienną z dziedziczonego kontraktu (state.py#L51-L62 (otwiera się w nowej karcie))
-
Nieprawidłowy interfejs ERC-20 (otwiera się w nowej karcie): szuka nieprawidłowych sygnatur funkcji ERC-20 (incorrect_erc20_interface.py#L34-L55 (otwiera się w nowej karcie))
Analiza semantyczna
W przeciwieństwie do analizy składniowej, analiza semantyczna sięga głębiej i analizuje „znaczenie” kodu. Ta rodzina obejmuje kilka szerokich typów analiz. Prowadzą one do potężniejszych i bardziej użytecznych wyników, ale są również bardziej złożone w pisaniu.
Analizy semantyczne są używane do najbardziej zaawansowanego wykrywania podatności.
Analiza zależności danych
Mówi się, że zmienna variable_a jest zależna od danych ze zmiennej variable_b, jeśli istnieje ścieżka, dla której na wartość variable_a wpływa variable_b.
W poniższym kodzie variable_a jest zależna od variable_b:
// ...
variable_a = variable_b + 1;
Slither posiada wbudowane możliwości analizy zależności danych (otwiera się w nowej karcie), dzięki swojej reprezentacji pośredniej (omówionej w dalszej części).
Przykład użycia zależności danych można znaleźć w detektorze niebezpiecznej ścisłej równości (otwiera się w nowej karcie). W tym przypadku Slither będzie szukał porównania ścisłej równości z niebezpieczną wartością (incorrect_strict_equality.py#L86-L87 (otwiera się w nowej karcie)) i poinformuje użytkownika, że powinien użyć >= lub <= zamiast ==, aby zapobiec uwięzieniu kontraktu przez atakującego. Między innymi detektor uzna za niebezpieczną wartość zwracaną przez wywołanie balanceOf(address) (incorrect_strict_equality.py#L63-L64 (otwiera się w nowej karcie)) i użyje silnika zależności danych do śledzenia jej użycia.
Obliczanie punktu stałego
Jeśli Twoja analiza porusza się po CFG i podąża za krawędziami, prawdopodobnie napotkasz już odwiedzone węzły. Na przykład, jeśli pętla jest przedstawiona jak poniżej:
for(uint i; i < range; ++){
variable_a += 1
}
Twoja analiza będzie musiała wiedzieć, kiedy się zatrzymać. Istnieją tutaj dwie główne strategie: (1) iteracja po każdym węźle skończoną liczbę razy, (2) obliczenie tak zwanego punktu stałego (fixpoint). Punkt stały w zasadzie oznacza, że analiza tego węzła nie dostarcza już żadnych istotnych informacji.
Przykład użycia punktu stałego można znaleźć w detektorach reentrancji: Slither bada węzły i szuka wywołań zewnętrznych, zapisów i odczytów z pamięci (storage). Gdy osiągnie punkt stały (reentrancy.py#L125-L131 (otwiera się w nowej karcie)), zatrzymuje eksplorację i analizuje wyniki, aby sprawdzić, czy występuje reentrancja, poprzez różne wzorce reentrancji (reentrancy_benign.py (otwiera się w nowej karcie), reentrancy_read_before_write.py (otwiera się w nowej karcie), reentrancy_eth.py (otwiera się w nowej karcie)).
Pisanie analiz wykorzystujących wydajne obliczanie punktu stałego wymaga dobrego zrozumienia, w jaki sposób analiza propaguje swoje informacje.
Reprezentacja pośrednia
Reprezentacja pośrednia (IR - Intermediate Representation) to język, który ma być bardziej podatny na analizę statyczną niż oryginał. Slither tłumaczy język Solidity na własne IR: SlithIR (otwiera się w nowej karcie).
Zrozumienie SlithIR nie jest konieczne, jeśli chcesz pisać tylko podstawowe testy. Przyda się jednak, jeśli planujesz pisać zaawansowane analizy semantyczne. Moduły wypisywania SlithIR (otwiera się w nowej karcie) i SSA (otwiera się w nowej karcie) pomogą Ci zrozumieć, jak tłumaczony jest kod.
Podstawy API
Slither posiada API, które pozwala na eksplorację podstawowych atrybutów kontraktu i jego funkcji.
Aby załadować bazę kodu:
from slither import Slither
slither = Slither('/path/to/project')
Eksploracja kontraktów i funkcji
Obiekt Slither posiada:
contracts (list(Contract): lista kontraktówcontracts_derived (list(Contract): lista kontraktów, które nie są dziedziczone przez inny kontrakt (podzbiór kontraktów)get_contract_from_name (str): Zwraca kontrakt na podstawie jego nazwy
Obiekt Contract posiada:
name (str): Nazwa kontraktufunctions (list(Function)): Lista funkcjimodifiers (list(Modifier)): Lista funkcjiall_functions_called (list(Function/Modifier)): Lista wszystkich funkcji wewnętrznych osiągalnych przez kontraktinheritance (list(Contract)): Lista dziedziczonych kontraktówget_function_from_signature (str): Zwraca funkcję (Function) na podstawie jej sygnaturyget_modifier_from_signature (str): Zwraca modyfikator (Modifier) na podstawie jego sygnaturyget_state_variable_from_name (str): Zwraca zmienną stanu (StateVariable) na podstawie jej nazwy
Obiekt Function lub Modifier posiada:
name (str): Nazwa funkcjicontract (contract): kontrakt, w którym zadeklarowana jest funkcjanodes (list(Node)): Lista węzłów tworzących CFG funkcji/modyfikatoraentry_point (Node): Punkt wejścia CFGvariables_read (list(Variable)): Lista odczytywanych zmiennychvariables_written (list(Variable)): Lista zapisywanych zmiennychstate_variables_read (list(StateVariable)): Lista odczytywanych zmiennych stanu (podzbiór variables`read)state_variables_written (list(StateVariable)): Lista zapisywanych zmiennych stanu (podzbiór variables`written)