Biała księga Ethereum
Ten dokument wprowadzający został pierwotnie opublikowany w 2014 r. przez Vitalika Buterina, założyciela Ethereum, przed uruchomieniem projektu w 2015 r. Warto zauważyć, że Ethereum, podobnie jak wiele projektów oprogramowania open-source tworzonych przez społeczność, ewoluowało od czasu powstania.
_Chociaż ten dokument ma już kilka lat, zachowujemy go, ponieważ nadal służy on jako użyteczny punkt odniesienia i dokładna reprezentacja Ethereum i jego wizji. Aby dowiedzieć się o najnowszych zmianach w Ethereum i o tym, jak wprowadzane są zmiany w protokole, polecamy ten przewodnik.
Platforma nowej generacji dla inteligentnych kontraktów i zdecentralizowanych aplikacji
Stworzenie Bitcoina przez Satoshi Nakamoto w 2009 roku było często uznawane za radykalny krok w rozwoju pieniądza i waluty, będąc pierwszym przykładem cyfrowego aktywa, które jednocześnie nie ma zabezpieczenia ani „wartości wewnętrznej (opens in a new tab)” oraz nie ma scentralizowanego emitenta ani kontrolera. Jednak kolejną, prawdopodobnie ważniejszą częścią eksperymentu Bitcoin jest leżąca u jego podstaw technologia blockchain jako narzędzia rozproszonego konsensusu i uwaga szybko zaczyna przesuwać się na ten inny aspekt Bitcoina. Często cytowane alternatywne zastosowania technologii blockchain obejmują wykorzystanie cyfrowych zasobów w łańcuchu bloków do reprezentowania niestandardowych walut i instrumentów finansowych („kolorowe monety (opens in a new tab)”), własność podstawowego urządzenia fizycznego („inteligentna własność (opens in a new tab)”), aktywa niewymienialne, takie jak nazwy domen („Namecoin (opens in a new tab)”), a także bardziej złożone aplikacje, w których zasoby cyfrowe są bezpośrednio kontrolowane przez fragment kodu implementujący dowolne zasady („inteligentne kontrakty (opens in a new tab)”), a nawet oparte na blockchainie „zdecentralizowane organizacje autonomiczne (opens in a new tab)” (DAO). To, co Ethereum zamierza zapewnić, to blockchain z wbudowanym w pełni rozwiniętym językiem programowania z kompletnością Turinga, który może być używany do tworzenia „kontraktów”, które mogą być używane do zakodowania dowolnych funkcji przejścia stanu, umożliwiając użytkownikom tworzenie dowolnego z opisanych powyżej systemów, a także wielu innych, których jeszcze sobie nie wyobrażamy, po prostu poprzez zapisanie logiki w kilku wierszach kodu.
Wprowadzenie do Bitcoina i istniejących koncepcji
Historia
Koncepcja zdecentralizowanej cyfrowej waluty, a także alternatywnych zastosowań, takich jak rejestry własności, istnieje od dziesięcioleci. Protokoły anonimowych e-pieniędzy z lat 80. i 90., w większości oparte na prymitywie kryptograficznym znanym jako Chaumian blinding, zapewniały walutę o wysokim stopniu prywatności, ale protokoły te w dużej mierze nie zyskały na popularności ze względu na ich zależność od scentralizowanego pośrednika. W 1998 roku b-money (opens in a new tab) autorstwa Wei Dai stało się pierwszą propozycją wprowadzenia idei tworzenia pieniędzy poprzez rozwiązywanie zagadek obliczeniowych, a także zdecentralizowanego konsensusu, ale propozycja była skąpa w szczegóły dotyczące tego, jak zdecentralizowany konsensus mógłby zostać faktycznie wdrożony. W 2005 roku Hal Finney wprowadził koncepcję „dowodów pracy wielokrotnego użytku (opens in a new tab)”, systemu, który wykorzystuje pomysły z b-money wraz z trudnymi obliczeniowo zagadkami Hashcash Adama Backa, aby stworzyć koncepcję kryptowaluty, ale po raz kolejny nie udało mu się osiągnąć ideału, polegając na zaufanym przetwarzaniu jako backendzie. W 2009 roku zdecentralizowana waluta została po raz pierwszy wdrożona w praktyce przez Satoshi'ego Nakamoto, łącząc ustalone prymitywy zarządzania własnością poprzez kryptografię klucza publicznego z algorytmem konsensusu do śledzenia, kto jest właścicielem monet, znanym jako „proof-of-work”.
Mechanizm stojący za proof-of-work był przełomem w przestrzeni, ponieważ rozwiązywał jednocześnie dwa problemy. Po pierwsze, zapewniał prosty i umiarkowanie skuteczny algorytm konsensusu, umożliwiając węzłom w sieci wspólne uzgadnianie zestawu kanonicznych aktualizacji stanu księgi Bitcoin. Po drugie, zapewniał mechanizm umożliwiający swobodne wejście w proces konsensusu, rozwiązując polityczny problem decydowania o tym, kto może wpływać na konsensus, jednocześnie zapobiegając atakom typu Sybil. Czyni to, zastępując formalną barierę uczestnictwa, np. wymóg rejestracji jako unikalny podmiot na określonej liście, barierą ekonomiczną — waga pojedynczego węzła w procesie głosowania konsensusu jest wprost proporcjonalna do mocy obliczeniowej, jaką wnosi węzeł. Od tego czasu zaproponowano alternatywne podejście zwane proof-of-stake, obliczające wagę węzła jako proporcjonalną do jego zasobów walutowych, a nie zasobów obliczeniowych; dyskusja na temat względnych zalet obu podejść wykracza poza zakres tego dokumentu, ale należy zauważyć, że oba podejścia mogą być wykorzystane jako szkielet kryptowaluty.
Bitcoin jako system transformacji stanu

Z technicznego punktu widzenia, księga kryptowalut, takich jak Bitcoin, może być postrzegana jako system zmiany stanu, w którym istnieje „stan” składający się ze statusu własności wszystkich istniejących bitcoinów oraz „funkcja zmiany stanu”, która przyjmuje stan i transakcję i wyprowadza nowy stan, który jest wynikiem. Przykładowo w standardowym systemie bankowym stan jest bilansem, transakcja jest prośbą o przeniesienie $X z A do B, a funkcja przejścia stanu zmniejsza wartość na koncie A o $X i zwiększa wartość na koncie B o $X. Jeśli konto A ma mniej niż $X, to funkcja zmiany stanu zwraca błąd. Można zatem formalnie zdefiniować:
ZASTOSUJ(S,TX) -> S' lub BŁĄD
W systemie bankowym zdefiniowanym powyżej:
Zastosuj ({ Alice: $50, Bob: $50 },"wyślij $20 z Alice do Bob") = { Alice: $30, Bob: $70 }
Ale:
ZASTOSUJ({ Alice: $50, Bob: $50 }:,"wyślij 70 USD od Alicji do Roberta") = BŁĄD
„Stan” w Bitcoinie to zbiór wszystkich monet (technicznie rzecz biorąc, „niewydanych wyników transakcji” lub UTXO), które zostały wybite i nie zostały jeszcze wydane, przy czym każda UTXO ma nominał i właściciela (zdefiniowanego przez 20-bajtowy adres, który jest zasadniczo kryptograficznym kluczem publicznymfn1). Transakcja zawiera jedno lub więcej danych wejściowych, z których każde zawiera odniesienie do istniejącego UTXO i podpis kryptograficzny wygenerowany przez klucz prywatny powiązany z adresem właściciela, oraz jedno lub więcej danych wyjściowych, z których każde zawiera nowe UTXO, które ma zostać dodane do stanu.
Funkcja przejścia stanu APPLY(S,TX) -> S' może być z grubsza zdefiniowana w następujący sposób:
Dla każdego wejścia w
TX:- Jeśli UTXO, do którego następuje odwołanie, nie znajduje się w
S, zwróć błąd. - Jeśli podany podpis nie pasuje do właściciela UTXO, zwróć błąd.
- Jeśli UTXO, do którego następuje odwołanie, nie znajduje się w
- Jeśli suma wartości wszystkich wejściowych UTXO jest mniejsza niż suma wartości wszystkich wyjściowych UTXO, zwróć błąd.
- Zwróć
Sze wszystkimi wejściowymi UTXO usuniętymi i wszystkimi wyjściowymi UTXO dodanymi.
Pierwsza połowa pierwszego kroku uniemożliwia nadawcom transakcji wydawanie monet, które nie istnieją, druga połowa pierwszego kroku uniemożliwia nadawcom transakcji wydawanie monet innych ludzi, a drugi krok wymusza zachowanie wartości. Aby użyć tego do płatności, protokół jest następujący. Załóżmy, że Alice chce wysłać 11,7 BTC do Boba. Najpierw Alice poszuka zestawu dostępnych UTXO, które posiada, o łącznej wartości co najmniej 11,7 BTC. Realistycznie rzecz biorąc, Alice nie będzie w stanie uzyskać dokładnie 11,7 BTC; powiedzmy, że najmniejsza kwota, jaką będzie w stanie uzyskać, to 6+4+2=12. Następnie tworzy transakcję z tymi trzema wejściami i dwoma wyjściami. Pierwszym wyjściem będzie 11,7 BTC z adresem Boba jako właścicielem, a drugim wyjściem będzie pozostałe 0,3 BTC „reszty”, a właścicielem będzie sama Alice.
Wydobycie

Gdybyśmy mieli dostęp do godnej zaufania scentralizowanej usługi, system ten byłby banalny do wdrożenia; można by go po prostu zakodować dokładnie tak, jak opisano, używając dysku twardego scentralizowanego serwera do śledzenia stanu. Jednak w przypadku Bitcoina staramy się zbudować zdecentralizowany system walutowy, więc będziemy musieli połączyć stanowy system transakcji z systemem konsensusu, aby zapewnić, że wszyscy zgadzają się co do kolejności transakcji. Zdecentralizowany proces konsensusu Bitcoina wymaga, aby węzły w sieci nieustannie próbowały tworzyć pakiety transakcji zwane „blokami”. Sieć ma na celu tworzenie mniej więcej jednego bloku co dziesięć minut, przy czym każdy blok zawiera znacznik czasu, nonce, odniesienie do (tj. hasz) poprzedniego bloku i listę wszystkich transakcji, które miały miejsce od poprzedniego bloku. Z czasem tworzy to trwały, ciągle rosnący „blockchain”, który stale aktualizuje się, aby reprezentować najnowszy stan księgi Bitcoin.
Algorytm sprawdzający, czy blok jest prawidłowy, wyrażony w tym paradygmacie, jest następujący:
- Sprawdź, czy poprzedni blok, na który powołuje się bieżący blok, istnieje i jest prawidłowy.
- Sprawdź, czy znacznik czasu bloku jest większy niż znacznik poprzedniego blokufn2 i mniejszy niż 2 godziny w przyszłości.
- Sprawdź, czy proof-of-work w bloku jest prawidłowy.
- Niech S[0] będzie stanem na końcu poprzedniego bloku.
- Załóżmy, że TX jest listą transakcji bloku z n transakcjami. Dla wszystkich
iw0...n-1ustawS[i+1] = APPLY(S[i],TX[i]). Jeśli jakakolwiek aplikacja zwróci błąd, wyjdź i zwróć fałsz. - Zwróć prawdę i zarejestruj S[n] jako stan na końcu tego bloku.
Zasadniczo, każda transakcja w bloku musi zapewnić prawidłowe przejście stanu ze stanu kanonicznego przed wykonaniem transakcji do nowego stanu. Należy zauważyć, że stan nie jest w żaden sposób zakodowany w bloku; jest to wyłącznie abstrakcja, która ma być zapamiętana przez węzeł walidujący i może być (bezpiecznie) obliczony tylko dla dowolnego bloku, zaczynając od stanu genezy i sekwencyjnie stosując każdą transakcję w każdym bloku. Ponadto należy zwrócić uwagę, że kolejność, w której górnik uwzględnia transakcje w bloku, ma znaczenie; jeżeli w bloku są dwie transakcje A i B, a B wydaje UTXO stworzone przez A, wtedy blok będzie prawidłowy, jeśli A pojawi się przed B, ale nie odwrotnie.
Jednym z warunków prawidłowości obecnych na powyższej liście, który nie jest znaleziony w innych systemach, jest wymóg „dowodu pracy”. Dokładny warunek polega na tym, że podwójny hash SHA256 każdego bloku, traktowany jako 256-bitowa liczba, musi być mniejszy niż dynamicznie dostosowany cel, który w chwili pisania tego wynosi około 2187. Celem tego jest sprawienie, aby tworzenie bloków było obliczeniowo „trudne”, uniemożliwiając w ten sposób atakującym metodą Sybil przerobienie całego blockchainu na swoją korzyść. Ponieważ SHA256 jest zaprojektowany, by być kompletnie nieprzewidywalną pseudo losową funkcją, jedyną możliwością stworzenia ważnego bloku jest zwykła metoda prób i błędów, wielokrotne powtarzanie nonce i porównywanie z haszem.
Przy obecnym celu ~2187, sieć musi wykonać średnio ~269 prób, zanim zostanie znaleziony prawidłowy blok; generalnie, cel jest ponownie kalibrowany przez sieć co 2016 bloków, więc nowy blok jest tworzony przez jakiś węzeł w sieci co średnio dziesięć minut. Aby zrekompensować górnikom tę pracę obliczeniową, górnik każdego bloku ma prawo do zawarcia transakcji dającej mu 25 BTC znikąd. Dodatkowo, jeśli jakakolwiek transakcja ma wyższy łączny nominał na wejściach niż na wyjściach, różnica trafia również do górnika jako „opłata transakcyjna”. Nawiasem mówiąc, jest to jedyny mechanizm, za pomocą którego emitowane są BTC; stan genezy nie zawierał żadnych monet.
Aby lepiej zrozumieć cel wydobywania, zbadajmy, co dzieje się w przypadku złośliwego atakującego. Ponieważ wiadomo, że kryptografia Bitcoina jest bezpieczna, atakujący będzie koncentrował się na jedynej części systemu Bitcoin, która nie jest chroniona bezpośrednio przez kryptografię: kolejność transakcji. Strategia atakującego jest prosta:
- Wysyła 100 BTC do sprzedawcy w zamian za jakiś produkt (najlepiej cyfrowy towar z szybką dostawą)
- Czeka na dostawę produktu
- Produkuje kolejną transakcję wysyłającą te same 100 BTC do niego samego
- Spróbuj przekonać sieć, że jego transakcja do samego siebie była pierwsza
Po wykonaniu kroku (1), po kilku minutach jakiś górnik uwzględni transakcję w bloku, powiedzmy bloku numer 270000. Po około godzinie do łańcucha zostanie dodanych kolejnych pięć bloków po tym bloku, a każdy z tych bloków pośrednio wskaże transakcję, a tym samym ją „potwierdzi”. W tym momencie sprzedawca zaakceptuje płatność jako sfinalizowaną i dostarczy produkt; ponieważ zakładamy, że to towar cyfrowy, dostawa jest natychmiastowa. Teraz atakujący tworzy kolejną transakcję wysyłającą 100 BTC do siebie. Jeśli atakujący po prostu wypuści ją do sieci, transakcja nie zostanie przetworzona; górnicy spróbują uruchomić APPLY(S,TX) i zauważą, że TX zużywa UTXO, które nie jest już w danym stanie. Zamiast tego atakujący tworzy „fork” blockchainu, zaczynając od wydobycia innej wersji bloku 270000 wskazującego na ten sam blok 269999 jako rodzica, ale z nową transakcją w miejscu starej. Ponieważ dane bloku są
różne, wymaga to ponownego potwierdzenia pracy. Ponadto nowa wersja bloku 270000 atakującego ma inny hash, więc oryginalne bloki od 270001 do 270005 nie „wskazują” na niego; w ten sposób oryginalny łańcuch i nowy łańcuch atakującego są całkowicie oddzielne. Reguła jest taka, że w forku najdłuższy blockchain jest uznawany za prawdziwy, więc
prawdziwi górnicy będą pracować na łańcuchu 270005, podczas gdy sam atakujący
będzie pracował na łańcuchu 270000. Aby atakujący mógł uczynić swój blockchain najdłuższym, musiałby mieć więcej mocy obliczeniowej niż pozostała część sieci łącznie, aby nadrobić zaległości (stąd „atak 51%”).
Drzewa Merkle
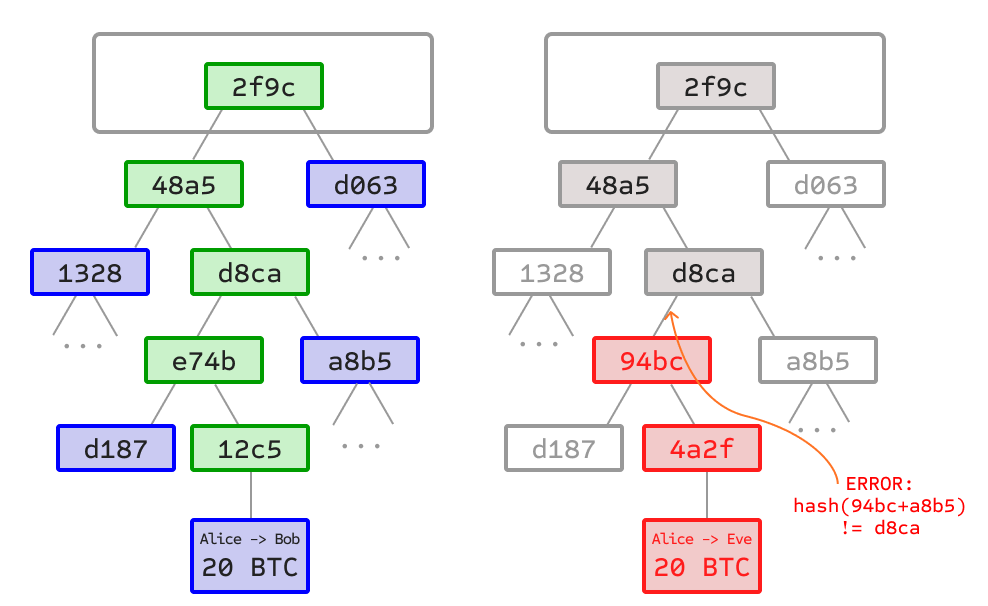
Po lewej: wystarczy przedstawić tylko niewielką liczbę węzłów w drzewie Merkle, aby udowodnić prawidłowość gałęzi.
Po prawej: każda próba zmiany jakiejkolwiek części drzewa Merkle ostatecznie doprowadzi do niespójności gdzieś w łańcuchu.
Ważną funkcją skalowalności Bitcoina jest to, że blok jest przechowywany w wielopoziomowej strukturze danych. „Hash” bloku jest w rzeczywistości tylko hashem nagłówka bloku, około 200-bajtowym fragmentem danych, który zawiera znacznik czasu, nonce, hash poprzedniego bloku i hash korzenia struktury danych zwanej drzewem Merkle przechowującym wszystkie transakcje w bloku. Drzewo Merkle jest rodzajem drzewa binarnego, składającego się z węzłów z dużą liczbą węzłów liści u dołu drzewa zawierających bazowe dane, zbioru węzłów pośrednich, gdzie każdy węzeł jest hashem jego dwóch dzieci, i finalnie pojedynczego węzła korzenia, również utworzonego z hashu jego dwóch dzieci, reprezentującego „wierzchołek” drzewa. Celem drzewa Merkle jest umożliwienie dostarczania danych w bloku fragmentarycznie: węzeł może pobrać tylko nagłówek bloku z jednego źródła, niewielką część drzewa istotną dla niego z innego źródła i nadal mieć pewność, że wszystkie dane są poprawne. Powodem, dla którego to działa, jest to, że hashe propagują się w górę: jeśli złośliwy użytkownik spróbuje zamienić fałszywą transakcję w dolnej części drzewa Merkle, ta zmiana spowoduje zmianę w węźle powyżej, a następnie zmianę w kolejnym węźle powyżej, ostatecznie zmieniając korzeń drzewa, a tym samym hash bloku, powodując, że protokół zarejestruje go jako zupełnie inny blok (prawie na pewno z nieprawidłowym dowodem pracy).
Protokół drzewa Merkle jest niewątpliwie niezbędny do zapewnienia stabilności w dłuższej perspektywie. „Pełny węzeł” w sieci Bitcoin, który przechowuje i przetwarza cały każdy blok, zajmuje około 15 GB przestrzeni dyskowej w sieci Bitcoin na kwiecień 2014 r. i rośnie o ponad gigabajt miesięcznie. Obecnie jest to opłacalne dla niektórych komputerów stacjonarnych, a nie telefonów, a później w przyszłości tylko przedsiębiorstwa i hobbyści będą mogli w tym uczestniczyć. Protokół znany jako „uproszczona weryfikacja płatności” (SPV) pozwala na istnienie innej klasy węzłów, zwanych „lekkimi węzłami”, które pobierają nagłówki bloków, weryfikują proof-of-work w nagłówkach bloków, a następnie pobierają tylko„gałęzie” związane z transakcjami, które są dla nich istotne. Pozwala to lekkim węzłom na określenie z dużą gwarancją bezpieczeństwa statusu dowolnej transakcji Bitcoin i ich aktualnego salda, przy jednoczesnym pobraniu tylko bardzo małej części całego blockchainu.
Alternatywne zastosowania Blockchain
Pomysł wykorzystania podstawowej idei blockchain i zastosowania jej do innych koncepcji również ma długą historię. W 2005 r. Nick Szabo przedstawił koncepcję „bezpiecznych tytułów własności z upoważnieniem właściciela (opens in a new tab)”, dokumentu opisującego, w jaki sposób „nowe postępy w technologii replikowanych baz danych” pozwolą na system oparty na blockchainie do przechowywania rejestru tego, kto jest właścicielem jakiej ziemi, tworząc rozbudowany framework obejmujący takie koncepcje, jak gospodarstwo rolne, zasiedzenie i gruziński podatek gruntowy. Niestety, w tamtym czasie nie istniał skuteczny system zreplikowanych baz danych, więc protokół ten nigdy nie został wdrożony w praktyce. Jednak po 2009 roku, gdy zdecentralizowany konsensus Bitcoina został opracowany, szybko zaczęło pojawiać się wiele alternatywnych aplikacji.
- Namecoin – stworzony w 2010 roku, Namecoin (opens in a new tab) można najlepiej opisać jako zdecentralizowaną bazę danych do rejestracji nazw. W zdecentralizowanych protokołach, takich jak Tor, Bitcoin i BitMessage, musi istnieć jakiś sposób identyfikacji kont, aby inni ludzie mogli wchodzić z nimi w interakcje, ale we wszystkich istniejących rozwiązaniach jedynym dostępnym rodzajem identyfikatora jest pseudolosowy hasz, taki jak
1LW79wp5ZBqaHW1jL5TCiBCrhQYtHagUWy. Idealnie byłoby mieć konto o nazwie „george”. Problem polega jednak na tym, że jeśli jedna osoba może utworzyć konto o nazwie „george”, to ktoś inny może użyć tego samego procesu, aby zarejestrować nazwę „george” również dla siebie i podszyć się pod niego. Jedynym rozwiązaniem jest paradygmat first-to-file, w którym pierwszy rejestrator odnosi sukces, a drugi ponosi porażkę — problem ten doskonale pasuje do protokołu konsensusu Bitcoina. Namecoin jest najstarszą i najbardziej udaną implementacją systemu rejestracji nazw wykorzystującą taki pomysł. - Kolorowe monety – celem kolorowych monet (opens in a new tab) jest służenie jako protokół umożliwiający ludziom tworzenie własnych cyfrowych walut – lub, w ważnym trywialnym przypadku waluty z jedną jednostką, cyfrowych tokenów na blockchainie Bitcoina. W protokole kolorowych monet „emituje się” nową walutę poprzez publiczne przypisanie koloru do określonego UTXO Bitcoina, a protokół rekurencyjnie definiuje kolor innych UTXO jako taki sam jak kolor danych wejściowych, które wydała tworząca je transakcja (niektóre specjalne zasady mają zastosowanie w przypadku danych wejściowych o mieszanych kolorach). Pozwala to użytkownikom na utrzymywanie portfeli zawierających tylko UTXO o określonym kolorze i wysyłanie ich podobnie jak zwykłych bitcoinów, śledząc wstecznie blockchain, aby określić kolor każdego UTXO, który otrzymają.
- Metacoins – ideą metacoin jest posiadanie protokołu, który działa na Bitcoinie, wykorzystując transakcje Bitcoin do przechowywania transakcji metacoin, ale posiadając inną funkcję przejścia stanu,
APPLY'. Ponieważ protokół metacoin nie może zapobiec pojawianiu się nieprawidłowych transakcji metacoin w blockchainie Bitcoina, dodano regułę, która domyślnie ustawia protokół naAPPLY'(S,TX) = S, jeśliAPPLY'(S,TX)zwróci błąd. Zapewnia to łatwy mechanizm tworzenia dowolnego protokołu kryptowalutowego, potencjalnie z zaawansowanymi funkcjami, których nie można zaimplementować w samym Bitcoinie, ale przy bardzo niskich kosztach rozwoju, ponieważ złożoność wydobycia i sieci jest już obsługiwana przez protokół Bitcoina. Metacoiny zostały wykorzystane do implementacji niektórych klas umów finansowych, rejestracji nazw i zdecentralizowanej giełdy.
Ogólnie rzecz biorąc, istnieją dwa podejścia do budowania protokołu konsensusu: budowanie niezależnej sieci i budowanie protokołu na Bitcoinie. Pierwsze podejście, choć dość skuteczne w przypadku aplikacji takich jak Namecoin, jest trudne do wdrożenia; każda indywidualna implementacja wymaga uruchomienia niezależnego blockchainu, a także zbudowania i przetestowania całego niezbędnego kodu przejścia stanu i sieci. Ponadto przewidujemy, że zestaw aplikacji dla zdecentralizowanej technologii konsensusu będzie zgodny z rozkładem prawa potęgowego, w którym zdecydowana większość aplikacji byłaby zbyt mała, aby uzasadnić swój własny blockchain, i zauważamy, że istnieją duże klasy zdecentralizowanych aplikacji, w szczególności zdecentralizowane autonomiczne organizacje, które muszą ze sobą współdziałać.
Z drugiej strony, podejście oparte na Bitcoinie ma tę wadę, że nie dziedziczy uproszczonych funkcji weryfikacji płatności Bitcoina. SPV działa w przypadku Bitcoina, ponieważ może wykorzystywać głębokość blockchainu jako proxy dla ważności; w pewnym momencie, gdy przodkowie transakcji sięgają wystarczająco daleko wstecz, można bezpiecznie powiedzieć, że byli oni legalnie częścią stanu. Z drugiej strony, metaprotokoły oparte na blockchainie nie mogą zmusić blockchainu do nieuwzględnienia transakcji, które nie są ważne w kontekście ich własnych protokołów. W związku z tym w pełni bezpieczna implementacja meta-protokołu SPV musiałaby skanować wstecz aż do początku blockchainu Bitcoin, aby określić, czy określone transakcje są ważne. Obecnie wszystkie „lekkie” implementacje meta-protokołów opartych na Bitcoinie polegają na zaufanym serwerze w celu dostarczenia danych, co jest niewątpliwie wysoce nieoptymalnym wynikiem, zwłaszcza gdy jednym z głównych celów kryptowalut jest wyeliminowanie potrzeby zaufania.
Skrypty
Nawet bez żadnych rozszerzeń, protokół Bitcoin faktycznie umożliwia słabą wersję koncepcji „inteligentnych kontraktów”. UTXO w Bitcoinie może być własnością nie tylko klucza publicznego, ale także bardziej skomplikowanego skryptu wyrażonego w prostym języku programowania opartym na stosie. W tym modelu transakcja wydająca to UTXO musi dostarczyć dane, które spełniają wymagania skryptu. W rzeczywistości nawet podstawowy mechanizm własności klucza publicznego jest implementowany za pomocą skryptu: skrypt przyjmuje podpis krzywej eliptycznej jako dane wejściowe, weryfikuje go względem transakcji i adresu, który jest właścicielem UTXO, i zwraca 1, jeśli weryfikacja zakończy się pomyślnie. W przeciwnym przpadku zwraca 0. Istnieją również inne, bardziej skomplikowane skrypty dla różnych dodatkowych przypadków użycia. Na przykład, można stworzyć skrypt, który wymaga podpisów od dwóch z trzech podanych kluczy prywatnych do walidacji („multisig”), konfigurację przydatną dla kont firmowych, bezpieczne konta oszczędnościowe i niektóre sytuacje depozytu handlowego. Skrypty mogą być również wykorzystywane do wypłacania nagród za rozwiązania problemów obliczeniowych, a nawet można skonstruować skrypt, który mówi coś w stylu „ten Bitcoin UTXO jest Twój, jeśli możesz dostarczyć dowód SPV, że wysłałeś do mnie transakcję Dogecoin o tym nominale”, zasadniczo umożliwiając zdecentralizowaną wymianę między kryptowalutami.
Język skryptowy zaimplementowany w Bitcoinie ma jednak kilka istotnych ograniczeń:
- Brak kompletności w sensie Turinga – znaczy to, że choć język skryptowy Bitcoina obsługuje duży podzbiór obliczeń, to jednak nie obsługuje on wszystkiego. Główną kategorią, której brakuje, są pętle. Ma to na celu uniknięcie nieskończonych pętli podczas weryfikacji transakcji; teoretycznie jest to przeszkoda możliwa do pokonania przez programistów skryptów, ponieważ każda pętla może być symulowana przez wielokrotne powtarzanie kodu bazowego za pomocą instrukcji warunkowej „if”, ale prowadzi to do skryptów, które są bardzo nieefektywne pod względem wykorzystania przestrzeni. Przykładowo, implementacja alternatywnego algorytmu podpisu krzywej eliptycznej prawdopodobnie wymagałaby 256 powtórzonych cykli mnożenia, które musiałyby być indywidualnie uwzględnione w kodzie.
- Ślepota na wartość – nie ma możliwości, aby skrypt UTXO zapewniał precyzyjną kontrolę nad kwotą, którą można wypłacić. Na przykład, jednym z potężnych przypadków użycia kontraktu wyroczni byłby kontrakt zabezpieczający (hedging), do którego A i B wpłacają równowartość 1000 USD w BTC, a po 30 dniach skrypt wysyła równowartość 1000 USD w BTC do A, a resztę do B. Wymagałoby to wyroczni do określenia wartości 1 BTC w USD, ale nawet wtedy byłaby to ogromna poprawa pod względem zaufania i wymagań infrastrukturalnych w porównaniu do w pełni scentralizowanych rozwiązań dostępnych obecnie. Jednakże, ponieważ UTXO działają w trybie „wszystko albo nic”, jedynym sposobem osiągnięcia tego jest bardzo nieefektywne obejście polegające na posiadaniu wielu UTXO o różnych nominałach (np. jedno UTXO o wartości 2k dla każdego k do 30) i pozwoleniu wyroczni na wybór, które UTXO wysłać do A, a które do B.
- Brak stanu – UTXO mogą być albo wydane, albo niewydane; nie ma możliwości tworzenia kontraktów wieloetapowych ani skryptów, które przechowują jakikolwiek inny stan wewnętrzny poza tym. Utrudnia to tworzenie wieloetapowych kontraktów opcyjnych, zdecentralizowanych ofert wymiany lub dwuetapowych protokołów kryptograficznego zobowiązania (niezbędnych do bezpiecznego nagród obliczeniowych). Oznacza to również, że UTXO mogą być wykorzystywane jedynie do budowania prostych, jednorazowych kontraktów, a nie bardziej złożonych kontraktów „stanowych”, takich jak zdecentralizowane organizacje, co sprawia, że meta-protokoły są trudne do wdrożenia. Połączenie binarnego stanu ze ślepotą na wartość oznacza również, że kolejne ważne zastosowanie, jak limity wypłat, jest niemożliwe do zrealizowania.
- Ślepota na blockchain – UTXO są ślepe na dane z blockchainu, takie jak nonce, znacznik czasu i hasz poprzedniego bloku. Powoduje to poważne ograniczenia w aplikacjach hazardowych i w kilku innych kategoriach, pozbawiając język skryptowy potencjalnie cennego źródła losowości.
Widzimy zatem trzy podejścia do budowania zaawansowanych aplikacji bazujących na kryptowalucie: budowanie nowego blockchaina, używanie skryptów bazujących na Bitcoin i budowanie metaprotokołu opartego na Bitcoin. Budowanie nowego blockchainu pozwala na nieograniczoną swobodę w budowaniu zestawu funkcji, ale kosztem czasu rozwoju, wysiłku przy uruchamianiu i bezpieczeństwa. Korzystanie ze skryptów jest łatwe do wdrożenia i standaryzacji, ale jest bardzo ograniczone w swoich możliwościach, a metaprotokoły, choć łatwe, cierpią z powodu błędów w skalowalności. Dzięki Ethereum zamierzamy zbudować alternatywny framework, który zapewnia jeszcze większe korzyści w łatwości rozwoju, jak również jeszcze silniejsze właściwości lekkiego klienta, a jednocześnie pozwala aplikacjom na współdzielenie środowiska ekonomicznego i bezpieczeństwa blockchainu.
Ethereum
Celem Ethereum jest stworzenie alternatywnego protokołu do budowy zdecentralizowanych aplikacji, zapewnienie innego zestawu kompromisów, które uważamy za bardzo przydatne dla dużej klasy zdecentralizowanych aplikacji, ze szczególnym naciskiem na sytuacje, w których szybki czas rozwoju, bezpieczeństwo dla małych i rzadko używanych aplikacji i zdolność różnych aplikacji do bardzo efektywnej interakcji, są ważne. Ethereum robi to, budując coś, co jest w zasadzie ostateczną abstrakcyjną warstwą podstawową: blockchain z wbudowanym językiem programowania kompletnym w sensie Turinga, pozwalającym każdemu pisać inteligentne kontrakty i zdecentralizowane aplikacje, w których można tworzyć własne, dowolne zasady własności, formaty transakcji i funkcje przejścia stanów. Uproszczoną wersję Namecoina można zapisać w dwóch linijkach kodu, a inne protokoły, takie jak waluty i systemy reputacji, mogą być zbudowane w mniej niż dwudziestu. Inteligentne kontrakty, kryptograficzne „skrzynki”, które zawierają wartość i odblokowują ją tylko wtedy, gdy spełnione są określone warunki, można również budować na tej platformie, ze znacznie większą mocą niż oferowana przez skrypty Bitcoina, ze względu na dodatkowe możliwości kompletności w sensie Turinga, świadomości wartości, świadomości blockchainu i stanu.
Konta Ethereum
W Ethereum stan składa się z obiektów zwanych „kontami”, przy czym każde konto ma 20-bajtowy adres, a przejścia stanu to bezpośrednie transfery wartości i informacji pomiędzy kontami. Konto Ethereum posiada cztery pola:
- Nonce, licznik używany do zapewnienia, że każda transakcja może być przetworzona tylko raz
- Bieżące saldo etheru konta
- Kod kontraktu konta, jeśli jest obecny
- Pamięć konta (domyślnie pusta)
„Ether” jest głównym wewnętrznym krypto-paliwem Ethereum, wykorzystywanym do uiszczania opłat transakcyjnych. Ogólnie rzecz biorąc, istnieją dwa rodzaje kont: konta zewnętrzne, kontrolowane przez klucze prywatne oraz konta kontraktowe, kontrolowane przez ich kod kontraktu. Konto zewnętrzne nie ma kodu i można z niego wysyłać wiadomości poprzez tworzenie i podpisywanie transakcji; w przypadku konta kontraktu, za każdym razem, gdy konto takie otrzyma wiadomość, jego kod zostaje aktywowany, co pozwala mu na odczytywanie i zapisywanie do wewnętrznego magazynu oraz wysyłanie innych wiadomości lub tworzenie kontaktów.
Warto zauważyć, że „kontrakty” w Ethereum nie powinny być postrzegane jako coś, co powinno być „spełnione” lub „przestrzegane”; są one raczej jak „autonomiczni agenci”, którzy żyją w środowisku wykonawczym Ethereum, zawsze wykonując określony fragment kodu, gdy są „szturchani” przez wiadomość lub transakcję, oraz mają bezpośrednią kontrolę nad własnym saldem etheru i własnym magazynem klucz/wartość, w którym przechowują trwałe zmienne.
Wiadomości i transakcje
Termin „transakcja” jest używany w Ethereum w odniesieniu do podpisanego pakietu danych, który przechowuje wiadomość do wysłania z konta zewnętrznego. Transakcje zawierają:
- Odbiorcę wiadomości
- Podpis identyfikujący nadawcę
- Ilość etheru do przesłania od nadawcy do odbiorcy
- Opcjonalne pole danych
- Wartość
STARTGAS, reprezentująca maksymalną liczbę kroków obliczeniowych, które może wykonać transakcja - Wartość
GASPRICEreprezentująca opłatę, jaką płaci nadawca za każdy krok obliczeniowy
Pierwsze trzy to standardowe pola, których się oczekuje w każdej kryptowalucie. Pole danych nie ma domyślnie żadnej funkcji, ale maszyna wirtualna posiada kod operacyjny, za pomocą którego kontrakt może uzyskać dostęp do tych danych; dla przykładu, jeśli kontrakt działa na blockchainie jako usługa rejestracji domen, może chcieć zinterpretować przekazywane mu dane jako zawierające dwa „pola”, przy czym pierwsze pole mogłoby być domeną do zarejestrowania, a drugie adresem IP, do którego byłaby przypisana domena. Kontrakt odczytałby te wartości z danych wiadomości i odpowiednio umieścił je w magazynie.
Pola STARTGAS i GASPRICE mają kluczowe znaczenie dla modelu ochrony Ethereum przed atakami typu „odmowa usługi”. Aby zapobiec przypadkowym bądź wrogim nieskończonym pętlom lub innym przypadkom marnotrawienia zasobów obliczeniowych w kodzie, każda transakcja musi ustawić limit na liczbę kroków obliczeniowych, które mogą zostać wykorzystane podczas jej realizacji. Podstawową jednostką obliczeniową jest „gaz”; zazwyczaj jeden krok obliczeniowy kosztuje 1 gaz, ale niektóre operacje kosztują większe ilości gazu, ponieważ są bardziej wymagające obliczeniowo lub zwiększają ilość danych, które muszą być przechowywane jako część stanu. Istnieje również opłata w wysokości 5 gazu za każdy bajt w danych transakcji. System opłat ma na celu zmuszenie atakującego do proporcjonalnego płacenia za każdy zasób, który zużywa, w tym za obliczenia, przepustowość i pamięć; w związku z tym każda transakcja, która powoduje zwiększone zużycie któregokolwiek z tych zasobów przez sieć, musi mieć opłatę za gaz w przybliżeniu proporcjonalną to tego wzrostu.
Komunikaty
Kontrakty mają możliwość wysyłania „wiadomości” do innych kontraktów. Wiadomości są wirtualnymi obiektami, które nigdy nie są serializowane i istnieją tylko w środowisku wykonawczym Ethereum. Wiadomość zawiera:
- Nadawcę wiadomości (niejawny)
- Odbiorcę wiadomości
- Ilość etheru do przesłania wraz z wiadomością
- Opcjonalne pole danych
- Wartość
STARTGAS
Zasadniczo wiadomość jest jak transakcja, z tą różnicą, że jest tworzona przez kontakt, a nie podmiot zewnętrzny. Wiadomość jest tworzona, gdy kontrakt aktualnie wykonujący kod wykona kod operacyjny CALL, który tworzy i wykonuje wiadomość. Podobnie jak w przypadku transakcji, wiadomość prowadzi do uruchomienia kodu na koncie odbiorcy. W ten sposób, kontrakty mogą mieć relacje z innymi kontraktami w taki sam sposób, w jaki mogą to robić podmioty zewnętrzne.
Warto zauważyć, że przydział gazu przypisany przez transakcję lub kontrakt dotyczy całkowitej ilości gazu zużytej przez tę transakcję i wszystkie jej podwykonania. Na przykład, jeśli podmiot zewnętrzny A wyśle transakcję do B z 1000 gazu, a B zużyje 600 gazu przed wysłaniem wiadomości do C, a wewnętrzne wykonanie C zużyje 300 gazu przed zwróceniem wyniku, to B może zużyć jeszcze 100 gazu przed wyczerpaniem dostępnego gazu.
Funkcja przejścia stanu w Ethereum
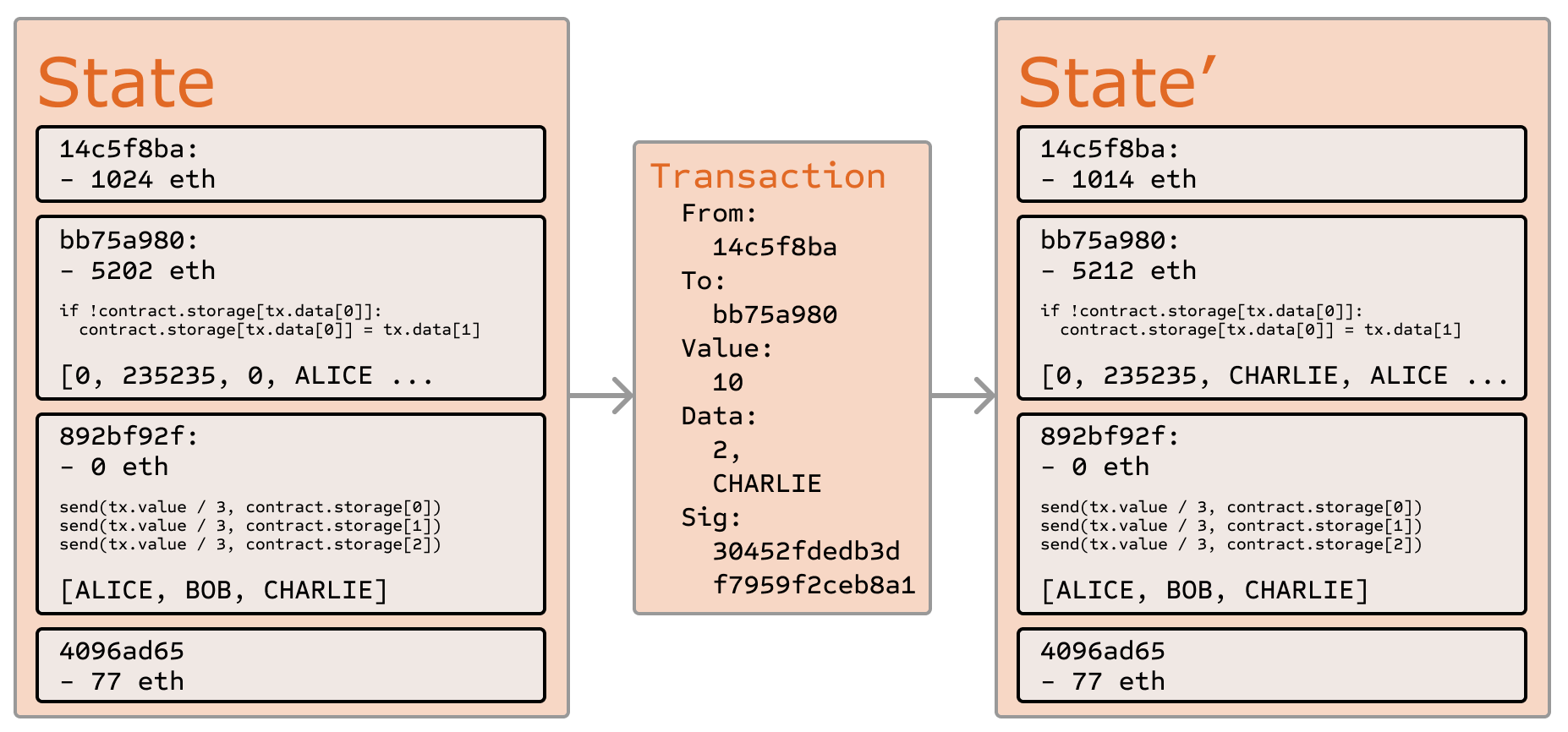
Funkcja przejścia stanu Ethereum, APPLY(S,TX) -> S' może być zdefiniowana w następujący sposób:
- Sprawdź, czy transakcja jest poprawnie sformułowana (tj. ma odpowiednią liczbę wartości), podpis jest prawidłowy, a nonce pasuje do nonce na koncie nadawcy. W przeciwnym razie zwróć błąd.
- Oblicz opłatę transakcyjną jako
STARTGAS * GASPRICEi określ adres nadawcy na podstawie podpisu. Odejmij opłatę od salda konta nadawcy i zwiększ nonce nadawcy. Jeśli saldo jest nie wystarczające, aby pokryć opłatę, zwróć błąd. - Zainicjuj
GAS = STARTGASi odejmij określoną ilość gazu na bajt, aby zapłacić za bajty w transakcji. - Przenieś wartość transakcji z konta nadawcy na konto odbiorcy. Jeśli konto odbiorcy jeszcze nie istnieje, utwórz je. Jeśli konto odbiorcy jest kontraktem, wykonaj kod kontraktu do momentu zakończenia lub wyczerpania gazu.
- Jeśli transfer wartości nie powiedzie się z powodu braku środków na koncie nadawcy lub wykonanie kodu wyczerpało gaz, cofnij wszystkie zmiany stanu z wyjątkiem uiszczenia opłat, a opłaty dodaj do konta górnika.
- W przeciwnym razie zwróć opłaty za niewykorzystany gaz nadawcy i wyślij opłaty za zużyty gaz na konto górnika.
Załóżmy na przykład, że kod kontaktu wygląda tak:
if !self.storage[calldataload(0)]:
self.storage[calldataload(0)] = calldataload(32)
Warto zauważyć, że w rzeczywistości kod kontraktu jest napisany w niskopoziomowym kodzie EVM; dla przejrzystości, powyższy przykład jest napisany w Serpent, jednym z naszych języków wysokiego poziomu, i może być skompilowany do kodu EVM. Załóżmy, że pamięć kontraktu jest na początku pusta i zostaje wysłana transakcja z wartością 10 etherów, 2000 gazu, ceną gazu 0,001 etheru i 64 bajtami danych, gdzie bajty 0-31 reprezentują liczbę 2, a bajty 32-63 reprezentują ciąg znaków CHARLIE. Proces dla funkcji przejścia stanu w tym przypadku wygląda następująco:
- Sprawdź, czy transakcja jest prawidłowa i poprawnie sformułowana.
- Sprawdź, czy nadawca transakcji ma przynajmniej 2000 * 0.001 = 2 ethery. Jeśli tak, odejmij 2 ethery z konta nadawcy.
- Zainicjuj gaz = 2000; zakładając, że transakcja ma 170 bajtów, a opłata za bajt wynosi 5, odejmij 850, pozostawiając 1150 gazu.
- Odejmij kolejne 10 etherów z konta nadawcy i dodaj je do konta kontraktu.
- Uruchom kod. W tym przypadku jest to proste: sprawdza, czy pamięć kontraktu pod indeksem
2jest używana, zauważa, że nie jest, więc ustawia pamięć pod indeksem2na wartośćCHARLIE. Załóżmy, że zabiera to 187 gazu, więc pozostała ilość gazu wynosi 1150 - 187 = 963 - Dodaj 963 * 0.001 = 0.963 etheru z powrotem na konto nadawcy i zwróć wynikowy stan.
Gdyby po stronie odbiorcy transakcji nie byłoby kontraktu, to całkowita opłata transakcyjna byłaby po prostu równa wartości GASPRICE pomnożonej przez długość transakcji w bajtach, a dane przesłane wraz z transakcją byłyby nieistotne.
Warto zauważyć, że wiadomości działają podobnie do transakcji w kontekście cofania; jeśli wykonanie transakcji wyczerpie gaz, to jej wykonanie i wszystkie inne wykonania wywołane przez to wykonanie zostaną cofnięte, ale wykonania nadrzędne nie muszą być cofane. Oznacza to, że „bezpieczne” jest dla kontraktu wywołanie innego kontraktu, ponieważ jeśli A wywołuje B z ilością G gazu, to wykonanie A gwarantuje utratę co najwyżej G gazu. Na koniec warto zauważyć, że istnieje kod operacyjny, CREATE, który tworzy kontrakt; jego mechanika wykonania jest generalnie podobna do CALL, z tą różnicą, że wynik wykonania określa kod nowo utworzonego kontraktu.
Wykonanie kodu
Kod w kontraktach Ethereum jest napisany w niskopoziomowym, opartym na stosie języku kodu bajtowego, nazywanym „kodem maszyny wirtualnej Ethereum” lub „kodem EVM”. Kod składa się z serii bajtów, gdzie każdy bajt reprezentuje operację. Zasadniczo wykonywanie kodu jest nieskończoną pętlą, która polega na wielokrotnym powtarzaniu operacji na bieżącym liczniku programu (który zaczyna od zera), a następnie zwiększaniu licznika programu o jeden, aż do momentu osiągnięcia końca kodu lub napotkania błędu bądź instrukcji STOP lub RETURN. Operacje mają dostęp do trzech typów przestrzeni do przechowywania danych:
- Stos, kontener typu „ostatnie weszło, pierwsze wyszło”, do którego można wstawiać i usuwać wartości
- Pamięć, nieskończenie rozszerzalna tablica bajtów
- Długoterminowa pamięć kontraktu, czyli magazyn klucz-wartość. W przeciwieństwie do stosu i pamięci, które są resetowane po zakończeniu obliczeń, magazyn jest trwały i przechowuje dane przez dłuższy czas.
Kod ma również dostęp do wartości, nadawcy, danych przychodzącej wiadomości, a także do danych nagłówka bloku. Kod może również zwrócić tablicę bajtów danych jako dane wyjściowe.
Formalny model wykonywania kodu EVM jest zaskakująco prosty. Podczas gdy Wirtualna Maszyna Ethereum jest uruchomiona, jej pełny stan obliczeniowy może być zdefiniowany za pomocą krotki (block_state, transaction, message, code, memory, stack, pc, gas), gdzie block_state to globalny stan zawierający wszystkie konta, w tym ich salda i pamięć. Na początku każdej rundy wykonywania aktualna instrukcja jest odnajdywana poprzez pobranie pc-tego bajtu code (lub 0, jeśli pc >= len(code)), a każda instrukcja ma własną definicję tego, jak wpływa na krotkę. Na przykład ADD usuwa dwa elementy ze stosu i dodaje z powrotem ich sumę, zmniejsza gas o 1 i zwiększa pc o 1, a SSTORE usuwa dwa górne elementy ze stosu i wstawia drugi element do pamięci kontraktu pod indeksem określonym przez pierwszy element. Chociaż istnieje wiele sposobów optymalizacji wykonywania kodu maszyny wirtualnej Ethereum, na przykład poprzez kompilację just-in-time, podstawową implementację Ethereum można zrealizować w kilku setkach linii kodu.
Blockchain i wydobycie

Blockchain Ethereum jest w wielu aspektach podobny do blockchainu Bitcoin, chociaż ma też pewne różnice. Główna różnica między Ethereum a Bitcoinem pod względem architektury blockchainu polega na tym, że bloki Ethereum, w przeciwieństwie do bloków Bitcoin, zawierają kopię zarówno listę transakcji, jak i najnowszego stanu. Poza tym, w bloku przechowywane są również dwie inne wartości: numer bloku i trudność. Podstawowy algorytm walidacji bloku w Ethereum wygląda następująco:
- Sprawdź, czy poprzedni blok, do którego się odwołano, istnieje i jest prawidłowy.
- Sprawdź, czy znacznik czasu bloku jest większy niż znacznik czasu poprzedniego bloku i mniejszy niż 15 minut w przyszłość.
- Sprawdź, czy numer bloku, trudność, korzeń transakcji, korzeń wujka oraz limit gazu (różne niskopoziomowe koncepcje specyficzne dla Ethereum) są prawidłowe.
- Sprawdź, czy proof-of-work w bloku jest prawidłowy.
- Niech S[0] będzie stanem na końcu poprzedniego bloku.
- Niech
TXbędzie listą transakcji bloku zntransakcjami. Dla wszystkichiw0...n-1, ustawS[i+1] = APPLY(S[i],TX[i]). Jeśli którakolwiek z aplikacji zwróci błąd lub jeśli całkowite zużycie gazu w bloku do tego momentu przekroczyGASLIMIT, zwróć błąd. - Niech
S_FINALbędzie równeS[n], ale z dodaną nagrodą za blok wypłaconą górnikowi. - Sprawdź, czy korzeń drzewa Merkle stanu
S_FINALjest równy końcowemu korzeniowi stanu podanemu w nagłówku bloku. Jeśli tak, blok jest prawidłowy; w przeciwnym razie jest nieprawidłowy.
Podejście to może wydawać się bardzo nieefektywne na pierwszy rzut oka, ponieważ wymaga przechowywania całego stanu z każdym blokiem, ale w rzeczywistości efektywność powinna być porównywalna do tej w Bitcoinie. Powodem jest to, że stan jest przechowywany w strukturze drzewa, a po każdym bloku tylko mała część drzewa musi być zmieniana. W związku z tym na ogół między dwoma sąsiednimi blokami zdecydowana większość drzewa powinna być taka sama, a zatem dane mogą być przechowywane raz i odwoływane podwójnie za pomocą wskaźników (tj. haszy poddrzew). W tym celu wykorzystuje się specjalny rodzaj drzewa znany jako „drzewo Patricia”, które jest modyfikacją koncepcji drzewa Merkle, umożliwiającą efektywne dodawanie i usuwanie węzłów, a nie tylko ich zmianę. Co więcej, ponieważ wszystkie informacje o stanie są częścią ostatniego bloku, nie ma potrzeby przechowywania całej historii blockchainu — strategia, która gdyby mogła być zastosowana w Bitcoinie, mogłaby zapewnić oszczędności rzędu 5-20 razy względem przestrzeni.
Często zadawanym pytaniem jest „gdzie” wykonywany jest kod kontraktu, pod względem fizycznego sprzętu. Odpowiedź jest prosta: proces wykonywania kodu kontraktu jest częścią definicji funkcji przejścia stanu, która jest częścią algorytmu walidacji bloku, więc jeśli transakcja zostanie dodana do bloku B, wykonanie kodu wywołane przez tę transakcję zostanie wykonane przez wszystkie węzły, teraz i w przyszłości, które pobiorą i zweryfikują blok B.
Aplikacje
Ogólnie rzecz biorąc, na Ethereum istnieją trzy rodzaje zastosowań. Pierwsza kategoria to aplikacje finansowe, które zapewniają użytkownikom bardziej zaawansowane sposoby zarządzania i zawierania umów z wykorzystaniem ich środków. Obejmuje to subwaluty, derywaty finansowe, kontrakty zabezpieczające, portfele oszczędnościowe, testamenty, a nawet niektóre rodzaje pełnowymiarowych umów o pracę. Druga kategoria to aplikacje półfinansowe, w których zaangażowane są pieniądze, ale istnieje również silna strona niepieniężna tego, co się robi; doskonałym przykładem są samoegzekwujące się nagrody za rozwiązania problemów obliczeniowych. Trzecia kategoria to aplikacje, takie jak głosowanie online i zdecentralizowane zarządzanie, które nie są w ogóle związane z finansami.
Systemy tokenów
Blockchainowe systemy tokenów mają wiele zastosowań, począwszy od subwalut reprezentujących aktywa takie jak USD, złoto czy nawet akcje firm, indywidualnych tokenów reprezentujących inteligentną własność, bezpiecznych i niepodrabialnych kuponów, aż do systemów tokenów niezwiązanych z tradycyjną wartością, wykorzystywanych jako systemy punktowe do zachęcania. Systemy tokenów są zaskakująco łatwe do zaimplementowania w Ethereum. Kluczowym punktem do zrozumienia jest to, że każda waluta lub system tokenów to zasadniczo baza danych z jedną operacją: odejmij X jednostek od A i dodaj X jednostek do B z zastrzeżeniem, że (1) A miał co najmniej X jednostek przed transakcją oraz (2) transakcja została zatwierdzona przez A. Wszystko, czego potrzeba do zaimplementowania systemu tokenów, to zaimplementowanie tej logiki w kontrakcie.
Podstawowy kod do implementacji systemu tokenów w Serpent wygląda następująco:
def send(to, value):
if self.storage[msg.sender] >= value:
self.storage[msg.sender] = self.storage[msg.sender] - value
self.storage[to] = self.storage[to] + value
Jest to zasadniczo dosłowna implementacja funkcji przejścia stanu „systemu bankowego” opisanej wcześniej w tym dokumencie. Trzeba dodać kilka dodatkowych linijek kodu, aby zapewnić początkowy etap dystrybucji jednostek walutowych, a najlepiej byłoby dodać funkcję, która pozwoli innymi kontraktom sprawdzenie salda adresu. I to wszystko. Teoretycznie, oparte na Ethereum systemy tokenów odgrywające rolę walut podrzędnych mogą potencjalnie zawierać inną ważną funkcję, której brakuje meta walutom opartym na Bitcoinie: możliwość płacenia opłat transakcyjnych w tej walucie. Sposób, w jaki można by to zaimplementować, polega na tym, że kontakt utrzymywałby saldo etheru, z którego refundowałby ether użyty do uiszczenia opłat nadawcy, a uzupełniałby to saldo, zbierając wewnętrzne jednostki walutowe pobierane jako opłaty i odsprzedając je w stale trwającej aukcji. Użytkownicy musieliby zatem „aktywować” swoje konta za pomocą etheru, ale gdy ether byłby już na koncie, to mógłby on być ponownie używany, ponieważ kontrakt refundowałby go za każdym razem.
Pochodne finansowe i waluty o stabilnej wartości
Derywaty finansowe są najczęstszym zastosowaniem „inteligentnego kontraktu” i jednym z najprostszych do zaimplementowania w kodzie. Głównym wyzwaniem przy implementacji kontraktów finansowych jest to, że większość z nich wymaga odniesienia do zewnętrznego wskaźnika cen; na przykład bardzo pożądanych zastosowaniem jest inteligentny kontrakt, który zabezpiecza przed zmiennością etheru (lub innej kryptowaluty) w odniesieniu do dolara amerykańskiego, ale wymaga to, aby kontrakt wiedział jaka jest wartość ETH/USD. Najprostszym sposobem na to jest użycie kontraktu „kanału danych” utrzymywanego przez określoną stronę (np. NASDAQ), zaprojektowanego tak, aby ta strona miała możliwość aktualizowania kontraktu w razie potrzeby oraz zapewnienia interfejsu, który pozwala innym kontraktom wysyłać wiadomości do tego kontraktu i otrzymywać odpowiedź zawierającą cenę.
Biorąc pod uwagę ten krytyczny składnik, kontrakt zabezpieczający wyglądałby następująco:
- Poczekaj, aż strona A wpłaci 1000 etherów.
- Poczekaj, aż strona B wpłaci 1000 etherów.
- Zapisz w magazynie wartość USD równą 1000 etherów, obliczoną poprzez zapytanie kontraktu kanału danych, powiedzmy, że jest to $x.
- Po 30 dniach pozwól A lub B „reaktywować” kontrakt w celu wysłania etheru o wartości $x (obliczonego poprzez ponowne zapytanie kontraktu kanału danych w celu uzyskania nowej ceny) do A, a resztę do B.
Taki kontrakt miałby znaczący potencjał w handlu kryptowalutami. Jednym z głównych problemów wymienianych w odniesieniu do kryptowalut jest fakt, że są one zmienne; chociaż wielu użytkowników i kupców może chcieć korzystać z bezpieczeństwa i wygody, jakie oferują kryptograficzne aktywa, to nie chcą oni jednak ryzykować utraty 23% wartości swoich środków w ciągu jednego dnia. Do tej pory najczęściej proponowanym rozwiązaniem były aktywa zabezpieczone przez emitenta; zamysł jest taki, że to emitent tworzy subwalutę, w której ma prawo emitować i odwoływać jednostki, a także dostarczać jedną jednostkę waluty każdemu, kto dostarczy mu (offline) jedną jednostkę określonego aktywa bazowego (np. złota, USD). Emitent obiecuje następnie dostarczyć jedną jednostkę aktywa bazowego każdemu, kto odeśle mu jedną jednostkę krypto-aktywa. Mechanizm ten umożliwia „podniesienie” dowolnego niekryptograficznego aktywa do aktywa kryptograficznego, pod warunkiem, że emitentowi można zaufać.
W praktyce jednak emitenci nie zawsze są godni zaufania, a w niektórych przypadkach infrastruktura bankowa jest zbyt słaba lub wroga, aby takie usługi mogły istnieć. Derywaty finansowe stanowią alternatywę. W tym przypadku zamiast pojedynczego emitenta zapewniającego środki na zabezpieczenie aktywa, rolę odgrywa zdecentralizowany rynek spekulantów, obstawiających, że cena kryptograficznego aktywa referencyjnego (np. ETH) wzrośnie. W przeciwieństwie do emitentów, spekulanci nie mają możliwości wycofania się ze swojej części umowy, ponieważ kontrakt zabezpieczający przechowuje ich fundusze w depozycie. Warto zauważyć, że takie podejście nie jest w pełni zdecentralizowane, ponieważ wciąż potrzebne jest zaufane źródło do dostarczania wskaźnika cenowego, choć mimo to stanowi ono ogromną poprawę pod względem zmniejszenia wymagań infrastrukturalnych (w przeciwieństwie do bycia emitentem, dostarczanie wskaźnika cenowego nie wymaga licencji i moze być prawdopodobnie sklasyfikowane jako wolność słowa) oraz zmniejszenia potencjału oszustw.
Systemy tożsamości i reputacji
Najwcześniejsza ze wszystkich alternatywnych kryptowalut, Namecoin (opens in a new tab), próbowała wykorzystać blockchain podobny do Bitcoina do zapewnienia systemu rejestracji nazw, w którym użytkownicy mogą rejestrować swoje nazwy w publicznej bazie danych wraz z innymi danymi. Głównym cytowanym przypadkiem użycia jest system DNS (opens in a new tab), który mapuje nazwy domen, takie jak „bitcoin.org” (lub w przypadku Namecoina, „bitcoin.bit”) na adres IP. Inne przypadki użycia obejmują uwierzytelnianie e-maili i potencjalnie bardziej zaawansowane systemy reputacji. Oto podstawowy kontrakt zapewniający podobny do Namecoin system rejestracji nazw na Ethereum:
def register(name, value):
if !self.storage[name]:
self.storage[name] = value
Kontrakt jest bardzo prosty; jest to baza danych wewnątrz sieci Ethereum, do której można dodawać, ale nie można modyfikować ani usuwać. Każdy może zarejestrować nazwę z pewną wartością, a rejestracja ta pozostaje na zawsze. Bardziej zaawansowany kontrakt rejestracji nazw będzie również posiadać „klauzulę funkcji” pozwalającą innym kontraktom odpytywać go, a także mechanizm dla „właściciela” (tj. pierwszego rejestrującego) nazwy do zmiany nazwy lub przeniesienia własności. Można nawet dodać funkcjonalność reputacji i sieci zaufania.
Zdecentralizowana pamięć plików
W ciągu ostatnich lat pojawiło się wiele popularnych startupów zajmujących się przechowywaniem plików online, z których najbardziej znanym jest Dropbox, oferujący użytkownikom możliwość przesyłania kopii zapasowej swojego dysku i przechowywania ich w usłudze oraz udostępniania za miesięczną opłatą. Jednak aktualnie rynek przechowywania plików jest czasami stosunkowo nieefektywny; pobieżne spojrzenie na istniejące rozwiązania pokazuje, że szczególnie na poziomie „doliny niesamowitości” 20-200 GB, na którym nie działają ani bezpłatne kwoty, ani rabaty dla przedsiębiorstw, miesięczne ceny za przechowywanie plików są takie, że płaci się więcej w ciągu jednego miesiąca więcej niż za cały dysk. Kontrakty Ethereum mogą umożliwić rozwój ekosystemy zdecentralizowanego przechowywania plików, w którym indywidualni użytkownicy mogą zarabiać drobne kwoty, wynajmując swoje własne dyski, a niewykorzystana przestrzeń może być używana do dalszego obniżania kosztów przechowywania plików.
Kluczowym elementem takiego urządzenia byłoby to, co nazwaliśmy „kontraktem zdecentralizowanego Dropboxa”. Kontrakt ten działa w następujący sposób. Najpierw dzieli się pożądane dane na bloki, szyfrując każdy blok dla prywatności, a następnie tworzy się z nich drzewo Merkle. Następnie tworzy się kontrakt z regułą, że co N bloków, kontrakt wybierze losowy indeks z drzewa Merkle (używając hasha poprzedniego bloku, dostępnego z kodu kontraktu, jako źródło losowości) i da X etheru pierwszemu podmiotowi, który dostarczy transakcję z dowodem własności bloku w tym konkretnym indeksie drzewa, podobnym do uproszczonej weryfikacji płatności. Gdy użytkownik chce ponownie pobrać swój plik, może użyć protokołu kanału mikropłatności (np. zapłacić 1 szabo za 32 kilobajty), aby odzyskać plik; najefektywniejszym podejściem dla płacącego pod względem opłat jest to, aby nie publikował transakcji do końca, zamiast tego zastępując transakcję nieco bardziej opłacalną transakcją z tym samym nonce po każdych 32 kilobajtach.
Ważną cechą tego protokołu jest to, że chociaż może się wydawać, że użytkownik ufa wielu losowym węzłom, że nie zapomną o pliku, można zredukować to ryzyko do niemal zera, dzieląc plik na wiele części za pomocą protokołu dzielenia sekretu i obserwując kontrakty, aby zobaczyć, czy każdy kawałek jest nadal w posiadaniu jakiegoś węzła. Jeśli kontrakt nadal wypłaca pieniądze, stanowi to kryptograficzny dowód na to, że ktoś nadal przechowuje plik.
Zdecentralizowane organizacje autonomiczne
Ogólna koncepcja „zdecentralizowanej organizacji autonomicznej” polega na tym, że wirtualny podmiot ma określony zestaw członków lub udziałowców, którzy, być może z 67% większością, mają prawo do wydawania funduszy podmiotu i modyfikowania jego kodu. Członkowie wspólnie decydowaliby o tym, jak organizacja powinna ulokować swoje fundusze. Metody alokacji funduszy DAO mogłyby obejmować nagrody i wynagrodzenia, a nawet bardziej egzotyczne mechanizmy, takie jak wewnętrzna waluta do nagradzania pracy. Zasadniczo replikuje to prawne cechy tradycyjnej firmy lub organizacji non-profit, ale przy użyciu wyłącznie kryptograficznej technologii blockchain do egzekwowania prawa. Do tej pory wiele dyskusji na temat DAO dotyczyło „kapitalistycznego” modelu „zdecentralizowanej korporacji autonomicznej” (DAC) z akcjonariuszami otrzymującymi dywidendy i zbywalnymi udziałami; alternatywa, być może określana jako „zdecentralizowana społeczność autonomiczna”, miałaby równy udział wszystkich członków w podejmowaniu decyzji i wymagałaby zgody 67% obecnych członków na dodanie lub usunięcie członka. Wymóg, aby jedna osoba mogła mieć tylko jedno członkostwo, musiałby być wtedy egzekwowany wspólnie przez grupę.
Ogólny zarys kodowania DAO jest następujący. Najprostszy projekt to po prostu fragment samomodyfikującego się kodu, który zmienia się, jeśli dwie trzecie członków zgodzi się na zmianę. Chociaż kod jest teoretycznie niezmienny, można to łatwo obejść i uzyskać faktyczną zmienność, umieszczając fragmenty kodu w osobnych kontraktach i przechowując adresy kontraktów, które należy wywołać, w modyfikowalnym magazynie. W prostej implementacji takiego kontraktu DAO byłyby trzy typy transakcji, rozróżniane na podstawie danych dostarczanych w transakcji:
[0,i,K,V], aby zarejestrować propozycję z indeksemiw celu zmiany adresu w indeksie pamięciKna wartośćV[1,i], aby zarejestrować głos za propozycjąi[2,i], aby sfinalizować propozycjęi, jeśli oddano wystarczającą liczbę głosów
Kontrakt miałby następnie klauzule dla każdego z tych przypadków. Utrzymywałby zapis wszystkich otwartych zmian magazynu, wraz z listą tych, którzy za nimi zagłosowali. Miałby również listę wszystkich członków. Gdyby jakakolwiek zmiana magazynu osiągnęła poparcie dwóch trzecich członków, transakcja finalizująca, mogłaby wykonać tę zmianę. Bardziej zaawansowany szkielet kontraktu zawierałby również wbudowaną możliwość głosowania nad funkcjami takimi jak wysyłanie transakcji, dodawanie członków i usuwanie członków, a może nawet mógłby zapewniać oddelegowywanie głosów w stylu płynnej demokracji (opens in a new tab) (tj. każdy może przypisać komuś innemu prawo do głosowania w swoim imieniu, a przypisanie jest przechodnie, więc jeśli A przypisze B, a B przypisze C, to C decyduje o głosie A). Ten projekt pozwoliłby DAO rozwijać się organicznie jako zdecentralizowana społeczność, umożliwiając ludziom ostatecznie delegować zadanie filtrowania, kto jest członkiem, specjalistom, chociaż w przeciwieństwie do „obecnego systemu” specjaliści mogą łatwo pojawiać się i znikać z czasem, gdy poszczególni członkowie społeczności zmieniają swoje nastawienie.
Alternatywnym modelem jest zdecentralizowana korporacja, w której każde konto może mieć zero lub więcej udziałów, a do podjęcia decyzji wymagane jest poparcie dwóch trzecich udziałów. Kompletny szkielet obejmowałby funkcję zarządzania aktywami, możliwość składania ofert kupna lub sprzedaży udziałów oraz możliwość akceptowania ofert (najlepiej z mechanizmem wewnątrz kontraktu do dopasowywania zamówień). Delegowanie istniałoby również w stylu płynnej demokracji, uogólniając koncepcję „zarządu”.
Dalsze zastosowania
1. Portfele oszczędnościowe. Załóżmy, że Alice chce zabezpieczyć swoje fundusze, ale obawia się, że zgubi lub ktoś zhakuje jej klucz prywatny. Wkłada ether do kontraktu z Bobem, bankiem, w następujący sposób:
- Alice może sama wypłacić maksymalnie 1% środków dziennie.
- Bob może sam wypłacić maksymalnie 1% środków dziennie, ale Alice ma możliwość dokonania transakcji swoim kluczem, która wyłącza tę możliwość.
- Alice i Bob razem mogą wypłacić wszystko.
Zwykle 1% dziennie wystarcza Alice, a jeśli Alice chce wypłacić więcej, może skontaktować się z Bobem, aby jej pomógł. Jeśli klucz Alice zostanie zhakowany, biegnie do Boba, aby przenieść środku do nowego kontraktu. Jeśli Alice zgubi swój klucz, Bob po pewnym czasie wypłaci wszystkie środki. Jeśli Bob okaże się nieuczciwy, Alice może wyłączyć jego możliwość wypłacania środków.
2. Ubezpieczenie upraw. Można łatwo stworzyć kontrakt derywatu finansowego, wykorzystując kanał danych pogody zamiast jakiegokolwiek indeksu cenowego. Jeśli rolnik w stanie Iowa zakupi derywat, które wypłaca środki odwrotnie proporcjonalnie do ilości opadów w stanie Iowa, to w przypadku suszy rolnik automatycznie otrzyma pieniądze, a jeśli będzie wystarczająco dużo deszczu, rolnik będzie zadowolony, ponieważ jego plony będą się dobrze rozwijać. Można to rozszerzyć na ubezpieczenia od klęsk żywiołowych.
3. Zdecentralizowany kanał danych. W przypadku finansowych kontraktów różnic kursowych możliwe jest zdecentralizowanie kanału danych za pomocą protokołu o nazwie „SchellingCoin (opens in a new tab)”. SchellingCoin zasadniczo działa w następujący sposób: N stron wprowadza do systemu wartość danego parametru (np. cenę ETH/USD), wartości te są sortowane, a każdy, kto znajduje się pomiędzy 25. a 75. percentylem, otrzymuje w nagrodę jeden token. Każdy ma motywację do udzielania odpowiedzi, której udzielą wszyscy inni, a jedyną wartością, co do której duża liczba graczy może realistycznie się zgodzić, jest oczywista wartość domyślna: prawda. Tworzy to zdecentralizowany protokół, który teoretycznie może dostarczyć dowolną liczbę wartości, wliczając w to cenę ETH/USD, temperaturę w Berlinie, a nawet wynik konkretnego trudnego obliczenia.
4. Inteligentny depozyt wielopodpisowy. Bitcoin pozwala na wielopodpisowe kontrakty transakcyjne, w których na przykład trzy z pięciu kluczy mogą wydać środki. Ethereum pozwala na większą szczegółowość; na przykład cztery z pięciu kluczy mogą wydawać wszystko, trzy z pięciu mogą wydać do 10% dziennie, a dwa z pięciu mogą wydać do 0,5% dziennie. Co więcej, wielopodpis w Ethereum jest asynchroniczny — dwie strony mogą zarejestrować swoje podpisy na blockchainie w różnym czasie, a ostatni podpis automatycznie wyśle transakcję.
5. Chmura obliczeniowa. Technologia EVM może być również wykorzystywana do tworzenia weryfikowalnego środowiska obliczeniowego, pozwalając użytkownikom zlecać innym wykonania obliczeń, a następnie opcjonalnie żądać dowodów, że obliczenia w niektórych losowo wybranych punktach kontrolnych zostały wykonane poprawnie. Pozwala to na stworzenie rynku chmur obliczeniowych, w którym każdy użytkownik może uczestniczyć, korzystając ze swojego komputera stacjonarnego, laptopa lub wyspecjalizowanego serwera, a wyrywkowa kontrola oraz depozyty zabezpieczające mogą zapewnić, że system jest godny zaufania (tj. węzły nie mogą oszukiwać z zyskiem). Chociaż taki system może nie być odpowiedni dla wszystkich zadań; na przykład zadania wymagające wysokiego poziomu komunikacji międzyprocesowej, nie mogą być łatwo realizowane na dużej chmurze węzłów. Inne zadania są jednak znacznie łatwiejsze do zrównoleglenia; projekty takie jak SETI@home, folding@home i algorytmy genetyczne mogą być z łatwością zaimplementowane na takiej platformie.
6. Hazard peer-to-peer. Dowolna liczba protokołów hazardowych peer-to-peer, takich jak Cyberdice (opens in a new tab) Franka Stajano i Richarda Claytona, może zostać zaimplementowana na blockchainie Ethereum. Najprostszym protokołem hazardowym jest właściwie kontrakt różnicy kursowej oparty na hashu następnego bloku, a bardziej zaawansowane protokoły mogą być tworzone na tej podstawie, tworzą usługi hazardowe z niemal zerowymi opłatami, które nie mają możliwości oszukiwania.
7. Rynki prognostyczne. Przy zastosowaniu wyroczni lub SchellingCoin rynki prognostyczne są również łatwe do zaimplementowania, a rynki prognostyczne połączone z SchellingCoin mogą stać się pierwszym szeroko stosowanym zastosowaniem futarchii (opens in a new tab) jako protokołu zarządzania dla zdecentralizowanych organizacji.
8. Zdecentralizowane rynki on-chain, wykorzystujące system tożsamości i reputacji jako podstawę.
Różne i obawy
Zmodyfikowana implementacja GHOST
Protokół „Greedy Heaviest Observed Subtree” (GHOST) to innowacja po raz pierwszy wprowadzona przez Yonatana Sompolinsky'ego i Aviva Zohara w grudniu 2013 roku (opens in a new tab). Motywacją do stworzenia GHOST jest to, że blockchainy z szybkim czasem potwierdzenia cierpią obecnie na zmniejszonego bezpieczeństwa spowodowanego wysokim wskaźnikiem nieaktualności — ponieważ bloki potrzebują pewnego czasu, aby rozprzestrzenić się w sieci, jeśli górnik A wykopie blok, a następnie górnik B wykopie inny blok, zanim blok górnika A rozprzestrzeni się do B, blok górnika B zmarnuje się i nie przyczyni do bezpieczeństwa sieci. Ponadto istnieje kwestia centralizacji: jeśli górnik A jest pulą wydobywczą z 30% mocy obliczeniowej (hashpower), a B ma 10% mocy obliczeniowej, A będzie miał ryzyko stworzenia bloku nieaktualnego w 70% przypadków (ponieważ w pozostałych 30% przypadków to A wyprodukował ostatni blok, a więc otrzyma dane wydobywcze natychmiast), podczas gdy B będzie miał ryzyko stworzenia bloku nieaktualnego w 90% przypadków. Zatem, jeśli interwał między blokami jest wystarczająco krótki, aby wskaźnik nieaktualnych bloków był wysoki, A będzie znacznie bardziej wydajny po prostu ze względu na swój rozmiar. W połączeniu z tymi dwoma efektami blockchainy, które szybko tworzą bloki, prawdopodobnie doprowadzą do sytuacji, w której jedna pula wydobywcza będzie miała wystarczająco dużą część mocy obliczeniowej sieci, aby de facto kontrolować proces wydobywania.
Jak opisali Sompolinsky i Zohar, GHOST rozwiązuje pierwszy kwestię utraty bezpieczeństwa sieci poprzez uwzględnianie nieaktualnych bloków do obliczeń, który łańcuch jest „najdłuższy”; znaczy to, że nie tylko rodzic i dalsi przodkowie bloku, ale także nieaktualni potomkowie przodka bloku (w żargonie Ethereum „wujkowie”) są dodawani do obliczeń, który blok ma największy całkowity proof-of-work. Aby rozwiązać drugą kwestię stronniczości centralizacji, wykraczamy poza protokół opisany przez Sompolinsky'ego i Zohara, i zapewniamy nagrody za blok dla bloków nieaktualnych: nieaktualny blok otrzymuje 87,5% swojej nagrody podstawowej, a siostrzeniec, który uwzględni nieaktualny blok, otrzyma pozostałe 12,5%. Opłaty transakcyjne nie są jednak przyznawane wujkom.
Ethereum implementuje uproszczoną wersję GHOST, która obejmuje tylko siedem poziomów. Konkretnie jest to zdefiniowane w następujący sposób:
- Blok musi określać rodzica i musi określać 0 lub więcej wujków
- Wujek uwzględniony w bloku B musi mieć następujące właściwości:
- Musi być bezpośrednim dzieckiem k-tego pokolenia przodka B, gdzie
2 <= k <= 7. - Nie może być przodkiem B
- Wujek musi być prawidłowym nagłówkiem bloku, ale nie musi być wcześniej zweryfikowanym ani nawet prawidłowym blokiem
- Wujek musi różnić się od wszystkich wujków uwzględnionych w poprzednich blokach praz od wszystkich innych wujków uwzględnionych w tym samym bloku (brak podwójnego uwzględnienia)
- Musi być bezpośrednim dzieckiem k-tego pokolenia przodka B, gdzie
- Za każdego wujka U w bloku B, górnik B otrzymuje dodatkowe 3,125% do swojej podstawowej nagrody, a górnik U otrzymuje 93,75% podstawowej nagrody.
Ta ograniczona wersja GHOST, z wujkami uwzględnianymi tylko do 7 pokoleń wstecz, została wykorzystana z dwóch powodów. Po pierwsze, nieograniczony GHOST wprowadziłby zbyt wiele komplikacji do obliczeń dotyczących tego, którzy wujkowie dla danego bloku są prawidłowi. Po drugie, nieograniczony GHOST z rekompensatą, jaką stosuje Ethereum, usuwa zachętę dla górnika do kopania w głównym łańcuchu, a nie w łańcuchu publicznego atakującego.
Opłaty
Ponieważ każda transakcja opublikowana w blockchainie nakłada na sieć koszt związany z koniecznością pobrania jej i zweryfikowania, konieczne jest zastosowanie jakiegoś mechanizmu regulacyjnego, zazwyczaj obejmującego opłaty transakcyjne, aby zapobiec nadużyciom. Domyślnym podejściem, stosowanym w Bitcoinie, jest posiadanie całkowicie dobrowolnych opłat, polegających na tym, że górnicy działają jako strażnicy i ustalają dynamiczne minima. Podejście to zostało bardzo przychylnie przyjęte w społeczności Bitcoina, szczególnie dlatego, że jest „oparte na rynku”, pozwalając, by podaż i popyt pomiędzy górnikami a nadawcami transakcji określały cenę. Problem z tym rozumowaniem polega jednak na tym, że przetwarzanie transakcji nie jest rynkiem; chociaż intuicyjnie atrakcyjne jest interpretowanie przetwarzania transakcji jako usługi, którą górnik oferuje nadawcy, w rzeczywistości każda transakcja uwzględniona przez górnika, będzie musiała zostać przetworzona przez każdy węzeł w sieci, więc zdecydowana większość kosztów przetwarzania transakcji jest ponoszona przez strony trzecie, a nie przez górnika, który podejmuje decyzję, czy ją uwzględnić czy nie. W związku z tym bardzo prawdopodobne jest wystąpienie problemów „tragedii wspólnego pastwiska”.
Jednakże, jak się okazuje, ta wada w mechanizmie opartym na rynku, przy określonym niedokładnym założeniu upraszczającym, magicznie się niweluje. Argumentacja jest następująca. Załóżmy, że:
- Transakcja prowadzi do
koperacji, oferując nagrodękRkażdemu górnikowi, który tę transakcję uwzględnia, gdzieRjest ustawiony przez nadawcę, akiRsą (z grubsza) wcześniej widoczne dla górnika. - Operacja ma koszt przetwarzania
Cdla każdego węzła (tj. wszystkie węzły mają taką samą wydajność) - Jest N węzłów wydobywczych, każdy z nich ma dokładnie taką samą moc przetwarzania (tj.
1/Ncałości) - Nie ma żadnych pełnych węzłów niekopalnych.
Górnik byłby skłonny przetworzyć transakcję, jeśli oczekiwana nagroda będzie większa niż koszt. Zatem oczekiwana nagroda to kR/N, ponieważ górnik ma 1/N szansy na przetworzenie kolejnego bloku, a koszt przetwarzania dla górnika wynosi po prostu kC. W związku z tym górnicy będą uwzględniać transakcje, gdzie kR/N > kC lub R > NC. Należy zauważyć, że R jest opłatą za operację dostarczoną przez nadawcę, a zatem jest dolną granicą korzyści, jaką nadawca czerpie z transakcji, a NC jest kosztem przetwarzania operacji dla całej sieci. W związku z tym górnicy mają motywację do uwzględniania tylko tych transakcji, dla których całkowita korzyść użytkowa przewyższa koszt.
W rzeczywistości istnieje jednak kilka istotnych odstępstw od tych założeń:
- Górnik ponosi wyższe koszty przetwarzania transakcji niż innych weryfikujących węzłów, ponieważ dodatkowy czas weryfikacji opóźnia propagację bloku i tym samym zwiększa szansę, że blok stanie się przestarzały.
- Istnieją pełne węzły niewydobywające.
- Dystrybucja energii wydobywczeh może w praktyce stać się radykalnie nieegalitarna.
- Spekulanci, wrogowie polityczni i maszyny, których funkcja użyteczności obejmuje wyrządzanie szkód w sieci, już istnieją, i mogą sprytnie tworzyć kontrakty, w których ich koszt jest znacznie niższy niż koszt zapłacony przez inne weryfikujące węzły.
(1) zapewnia tendencję górnika do włączania mniejszej liczby transakcji, oraz
(2) zwiększa NC; stąd te dwa efekty przynajmniej częściowo
się znoszą
wzajemnie.Jak? (opens in a new tab)
(3) i (4) to główne problemy; aby je rozwiązać, po prostu wprowadzamy
pływający limit: żaden blok nie może mieć więcej operacji niż
BLK_LIMIT_FACTOR razy długoterminowa wykładnicza średnia krocząca.
Konkretnie:
blk.oplimit = floor((blk.parent.oplimit \* (EMAFACTOR - 1) +
floor(parent.opcount \* BLK\_LIMIT\_FACTOR)) / EMA\_FACTOR)
BLK_LIMIT_FACTOR i EMA_FACTOR to stałe, które tymczasowo zostaną ustawione na 65536 i 1,5, ale prawdopodobnie zostaną one zmienione po dalszej analizie.
Istnieje jeszcze jeden czynnik zniechęcający do dużych rozmiarów bloków w Bitcoinie: propagacja dużych bloków trwa dłużej, a zatem istnieje większe prawdopodobieństwo, że staną się one nieaktualne. W Ethereum, bloki zużywające dużo gazu mogą również wymagać więcej czasu na propagację, zarówno dlatego, że są fizycznie większe, jak i dlatego, że wymagają więcej czasu na przetworzenie przejść stanu transakcji w celu ich walidacji. To zniechęcające opóźnienie jest istotnym czynnikiem w Bitcoinie, ale w mniejszym stopniu w Ethereum ze względu na protokół GHOST; dlatego też poleganie na regulowanych limitach bloków zapewnia bardziej stabilną podstawę.
Obliczenia i kompletność w sensie Turinga
Ważną informacją jest to, że maszyna wirtualna Ethereum jest kompletna w sensie Turinga; oznacza to, że kod EVM może kodować dowolne obliczenia, które można sobie wyobrazić, w tym nieskończone pętle. Kod EVM umożliwia wykonywanie pętli na dwa sposoby. Po pierwsze, istnieje instrukcja JUMP, która pozwala programowi przeskoczyć z powrotem do poprzedniego miejsca w kodzie, oraz instrukcja JUMPI do skoków warunkowych, pozwalająca na instrukcje takie jak while x < 27: x = x * 2. Po drugie, kontrakty mogą wywoływać inne kontrakty, co potencjalnie pozwala na zapętlenie poprzez rekurencję. To naturalnie prowadzi do problemu: czy złośliwi użytkownicy mogą zasadniczo wyłączyć górników i pełne węzły zmuszając je do wejścia w nieskończoną pętlę? Kwestia ta pojawia się z powodu problemu znanego w informatyce jako problem stopu: nie ma sposobu, aby powiedzieć, w ogólnym przypadku, czy dany program kiedykolwiek się zatrzyma.
Jak opisano w sekcji dotyczącej przejścia stanu, nasze rozwiązanie polega na wymaganiu, aby transakcja ustaliła maksymalną liczbę kroków obliczeniowych, które mogą zostać wykonane, a jeśli wykonanie przekroczy ten limit, obliczenia są cofane, ale opłaty są nadal uiszczane. Wiadomości działają w ten sam sposób. Aby pokazać motywację stojącą za naszym rozwiązaniem, rozważmy następujące przykłady:
- Atakujący tworzy kontrakt, który uruchamia nieskończoną pętlę, a następnie wysyła transakcję aktywującą tę pętlę do górnika. Górnik przetworzy transakcję, uruchamiając nieskończoną pętlę i poczeka, aż skończy się jej gaz. Nawet jeśli w trakcie wykonywania transakcji zabraknie gazu i zatrzyma się ona w połowie, to transakcja nadal jest prawidłowa, a górnik nadal pobiera opłatę od atakującego za każdy krok obliczeniowy.
- Atakujący tworzy bardzo długą nieskończoną pętlę z zamiarem zmuszenia górnika do obliczania przez tak długi czas, że zanim zakończy się obliczanie, wyjdzie kilka kolejnych bloków i górnik nie będzie mógł uwzględnić transakcji w celu pobrania opłaty. Atakujący będzie zobowiązany jednak do przesłania wartości dla
STARTGASograniczającej liczbę kroków obliczeniowych, które może wykonać, więc górnik będzie wiedział z wyprzedzeniem, że obliczenia zajmą nadmiernie dużą liczbę kroków. - Atakujący widzi kontrakt z kodem w formie
send(A,contract.storage[A]); contract.storage[A] = 0i wysyła transakcję z wystarczającą ilością gazu, aby wykonać krok pierwszy, ale nie drugi (tj. dokonuje wypłaty, ale nie pozwala, aby saldo się zmniejszyło). Autor kontraktu nie musi martwić się o ochronę przed takimi atakami, ponieważ jeśli wykonanie zatrzyma się w połowie, zmiany zostaną cofnięte. - Kontrakt finansowy działa, przyjmując medianę z dziewięciu zastrzeżonych kanałów danych w celu minimalizacji ryzyka. Atakujący przejmuje jeden z kanałów danych, który został zaprojektowany tak, aby można go było modyfikować za pomocą mechanizmu wywołania adresu zmiennej opisanego w sekcji o DAO, i przekształca go tak, aby działał w nieskończonej pętli, próbując w ten sposób zmusić wszelkie próby pobrania środków z kontraktu finansowego do wyczerpania gazu. Kontrakt finansowy może jednak ustawić limit gazu dla wiadomości, aby zapobiec temu problemowi.
Alternatywą dla kompletności w sensie Turinga jest niekompletność w sensie Turinga, w której JUMP i JUMPI nie istnieją i tylko jedna kopia każdego kontraktu może istnieć w stosie wywołań w danym momencie. W tym systemie opisany system opłat i niepewność co do skuteczności naszego rozwiązania mogą nie być konieczne, ponieważ koszty wykonania kontraktu byłby ograniczony przez jego rozmiar. Co więcej, niekompletność Turinga nie jest nawet tak dużym ograniczeniem; spośród wszystkich przykładów kontraktów, które wewnętrznie wymyśliliśmy, tylko jeden wymagał pętli, a nawet tę pętlę można było usunąć, wykonując 26 powtórzeń jednej linii fragmentu kodu. Biorąc pod uwagę poważne implikacje kompletności Turinga i ograniczone korzyści, dlaczego po prostu nie mieć języka niekompletnego w sensie Turinga? W rzeczywistości jednak niekompletność Turinga daleka jest od prostszego rozwiązania problemu. Aby zobaczyć dlaczego, rozważmy następujące kontrakty:
C0: call(C1); call(C1);
C1: call(C2); call(C2);
C2: call(C3); call(C3);
...
C49: call(C50); call(C50);
C50: (uruchom jeden krok programu i zapisz zmianę w pamięci)
Wyślijmy teraz transakcję do A. W ten sposób, w 51 transakcjach, mamy kontrakt, który zajmuje 250 kroków obliczeniowych. Górnicy mogliby próbować wykrywać takie bomby logiczne z wyprzedzeniem, utrzymując wartość obok każdego kontraktu określającą maksymalną liczbę kroków, które może on wykonać i obliczając ją dla kontraktów wywołujących inne kontrakty rekurencyjnie, ale wymagałoby to od górników zakazywania kontraktów, które tworzą inne kontrakty (ponieważ tworzenie i wykonywanie wszystkich powyższych 26 kontraktów mogłoby łątwo zostać włączone do jednego kontraktu). Innym problematycznym punktem jest to, że pole adresu wiadomości jest zmienną, więc generalnie może nie być nawet możliwe ustalenie, które inne kontrakty dany kontrakt wywoła z wyprzedzeniem. W związku z tym mamy zaskakujący wniosek: kompletność Turinga jest zaskakująco łatwa zarządzania, a brak kompletności Turinga jest równie zaskakująco trudny do zarządzania, chyba że wprowadzone zostaną takie same kontrole — ale w takim przypadku dlaczego po prostu nie pozwolić, aby protokół był kompletny w sensie Turinga?
Waluta i emisja
Sieć Ethereum zawiera własną, wbudowaną walutę, ether, która pełni podwójną funkcję: zapewnia podstawową warstwę płynności, aby umożliwić efektywną wymianę między różnymi rodzajami aktywów cyfrowych, oraz co ważniejsze, zapewnia mechanizm do uiszczania opłat transakcyjnych. Dla wygody i uniknięcia przyszłych sporów (jak w przypadku obecnych dyskusji na temat mBTC/uBTC/satoshi w Bitcoinie) nominały zostaną wstępnie oznaczone:
- 1: wei
- 1012: szabo
- 1015: finney
- 1018: ether
Należy to traktować jako rozszerzoną wersję koncepcji „dolarów” i „centów” lub „BTC” i „satoshi”. W najbliższej przyszłości spodziewamy się, że „ether” będzie używany do zwykłych transakcji, „finney” do mikrotransakcji, a „szabo” i „wei” do technicznych dyskusji na temat opłat i implementacji protokołu; pozostałe nominały mogą stać się przydatne później i na razie nie powinny być uwzględniane w klientach.
Model emisji będzie następujący:
- Ether zostanie wydany w sprzedaży waluty po cenie 1000-2000 etherów za BTC, czyli mechanizmu przeznaczonego do finansowania organizacji Ethereum i płacenia za rozwój, który był z powodzeniem wykorzystywany przez inne platformy, takie jak MasterCoin i NXT. Wcześni nabywcy skorzystają z większych rabatów. BTC otrzymane ze sprzedaży zostaną w całości przeznaczone na wypłatę wynagrodzeń i nagród dla deweloperów, oraz zainwestowane w różne projekty non-profit, jak i te nastawione na zysk w ekosystemie Ethereum i kryptowalut.
- 0,099x całkowitej sprzedanej ilości (60102216 ETH) zostanie przydzielone organizacji w celu zrekompensowania wczesnych uczestników oraz na pokrycie wydatków denominowanych w ETH przed blokiem genezy.
- 0,099x całkowitej sprzedanej ilości zostanie utrzymane jako rezerwa długoterminowa.
- 0,26x całkowitej sprzedanej ilości będzie przydzielane górnikom każdego roku na zawsze od tego momentu.
| Grupa | Przy wprowadzeniu | Po 1 roku | Po 5 latach |
|---|---|---|---|
| Jednostki waluty | 1,198X | 1,458X | 2,498X |
| Kupujący | 83,5% | 68,6% | 40,0% |
| Rezerwa wydana przed sprzedażą | 8,26% | 6,79% | 3,96% |
| Rezerwa wykorzystana po sprzedaży | 8,26% | 6,79% | 3,96% |
| Górnicy | 0% | 17,8% | 52,0% |
Długoterminowa stopa wzrostu podaży (w procentach)
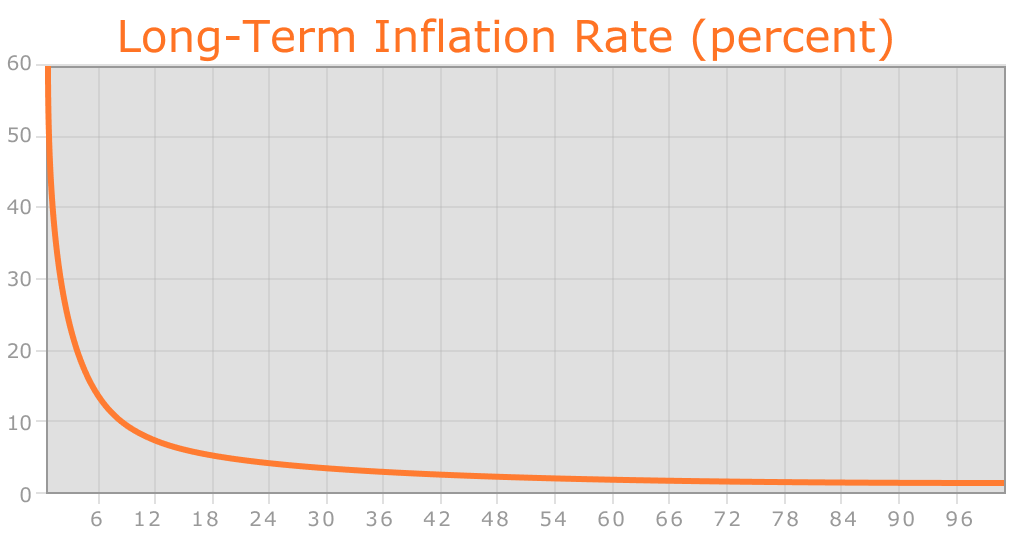
Pomimo liniowej emisji waluty, podobnie jak w przypadku Bitcoina, stopa wzrostu podaży z czasem dąży do zera.
Dwa główne wybory w powyższym modelu to (1) istnienie i wielkość puli zasobów oraz (2) istnienie stale rosnącej liniowej podaży, w przeciwieństwie do ograniczonej podaży, jak w przypadku Bitcoina. Uzasadnienie puli zasobów jest następujące. Gdyby pula zasobów nie istniała, a liniowa emisja została zmniejszona do 0,217x, aby zapewnić taką samą stopę inflacji, całkowita ilość etheru byłaby o 16,5% mniejsza, a każda jednostka byłaby o 19,8% bardziej wartościowa. W związku z tym, w równowadze zakupiono by o 19,8% więcej etheru podczas sprzedaży, a więc każda jednostka byłaby znowu tak samo wartościowa jak wcześniej. Organizacja posiadałaby również 1,198x więcej BTC, które można podzielić na dwie części: oryginalny BTC i dodatkowe 0,198x. W związku z tym sytuacja ta jest dokładnie równoważna z istnieniem puli zasobów, ale z jedną istotną różnicą: organizacja posiadałaby wyłącznie BTC, a zatem nie byłaby zachęcana do wspierania wartości jednostki etheru.
Stały liniowy model wzrostu podaży zmniejsza ryzyko tego, co niektórzy postrzegają jako nadmierną koncentrację bogactwa w Bitcoinie, i daje osobom żyjącym obecnie i w przyszłości uczciwą szansę na nabycie jednostek waluty, jednocześnie zachowując silną zachętę do pozyskiwania i utrzymywania etheru, poniważ „stopa wzrostu podaży” jako procent z czasem nadal zmierza do zera. Teoretyzujemy również, że ponieważ monety są zawsze tracone z czasem z powodu nieostrożności, śmierci itp., a utrata monet może być modelowana jako procent całkowitej podaży rocznie, całkowita podaż waluty w obiegu ostatecznie ustabilizuje się na poziomie równym rocznej emisji podzielonej przez wskaźnik strat (np. przy wskaźniku strat wynoszącym 1%, gdy podaż osiągnie 26X, wówczasz 0,26X będzie wydobywane i 0,26X tracone każdego roku, tworząc równowagę).
Należy pamiętać, ze w przyszłości prawdopodobne jest, że Ethereum przejdzie na model proof-of-stake dla bezpieczeństwa, zmniejszając wymóg emisji do wartości od zera do 0,05X rocznie. W przypadku, gdy organizacja Ethereum straci fundusze lub z jakiegokolwiek innego powodu zniknie, pozostawiamy otwartą „umowę społeczną”: każdy ma prawo stworzyć przyszłą kandydującą wersję Ethereum, pod warunkiem, że ilość etheru musi być co najwyżej równa 60102216 * (1.198 + 0.26 * n), gdzie n to liczba lat po bloku genezy. Twórcy mogą swobodnie sprzedawać lub w inny sposób przydzielać część lub całość różnicy między ekspansją podaży napędzaną przez PoS a maksymalną dopuszczalną ekspansją podaży, aby zapłacić za rozwój. Kandydujące aktualizacje, które nie są zgodne z umową społeczną, mogą zostać w uzasadniony sposób sforkowane na wersje zgodne.
Centralizacja wydobycia
Algorytm wydobywczy Bitcoina działa w ten sposób, że górnicy obliczają SHA256 na lekko zmodyfikowanych wersjach nagłówka bloku miliony razy w kółko, aż w końcu jeden węzeł znajdzie wersję, której hash jest mniejszy niż docelowy (obecnie około 2192). Ten algorytm wydobywczy jest jednak podatny na dwie formy centralizacji. Po pierwsze, ekosystem wydobywczy został zdominowany przez układy ASIC (specjalizowane układy scalone), czyli chipy komputerowe zaprojektowane specjalnie do wydobywania Bitcoinów, które są tysiące razy wydajniejsze w tym konkretnym zadaniu. Oznacza to, ze wydobywanie Bitcoinów nie jest już wysoce zdecentralizowanych i egalitarnym zajęciem, ponieważ wymaga milionów dolarów kapitału, aby efektywnie w tym uczestniczyć. Po drugie, większość górników Bitcoinów nie przeprowadza walidacji bloków lokalnie; zamiast tego polegają oni na scentralizowanych pulach wydobywczych, które dostarczają im nagłówki bloków. Ten problem jest prawdopodobnie poważniejszy: w chwili pisania tego tekstu, trzy największe pule wydobywcze pośrednio kontrolują około 50% mocy obliczeniowej w sieci Bitcoin, chociaż jest to łagodzone przez fakt, że górnicy mogą przełączyć się na inną pulę wydobywczą, jeśli dana pula lub koalicja spróbuje przeprowadzić atak 51%.
Obecnym zamiarem Ethereum jest wykorzystanie algorytmu wydobywczego, w którym górnicy są zobowiązani do pobierania losowanych danych ze stanu, obliczania losowo wybranych transakcji z ostatnich N bloków w blockchainie i zwracania hashu wyniku. Ma to dwie ważne korzyści. Po pierwsze, kontrakty Ethereum mogą zawierać dowolny rodzaj obliczeń, więc układ ASIC Ethereum byłby zasadniczo układem ASIC do ogólnych obliczeń — tj. lepszym procesorem. Po drugie, wydobywanie wymaga dostępu do całego blockchainu, co zmusza górników do przechowywania całego blockchainu i przynajmniej do zdolności weryfikacji każdej transakcji. Eliminuje to potrzebę scentralizowanych pul wydobywczych; chociaż pule wydobywcze mogą nadal pełnić uzasadnioną rolę wyrównywania losowości dystrybucji nagród, funkcja ta może być równie dobrze obsługiwana przez pule peer-to-peer bez centralnej kontroli.
Model ten nie został jeszcze przetestowany, a po drodze mogą pojawić się trudności z uniknięciem pewnych sprytnych optymalizacji podczas korzystania z wykonywania kontraktu jako algorytmu wydobywczego. Jednakże jedną znacząco interesującą funkcją tego algorytmu jest to, że pozwala on każdemu na "zatrucie studni" poprzez wprowadzenie dużej liczby kontraktów na blockchain zaprojektowanych specjalnie po to, aby zatkać niektóre ASIC. Istnieje zachęta ekonomiczna dla producentów ASIC, aby użyć takiego triku w celu zaatakowania siebie nawzajem. Zatem rozwiązanie, które tworzymy jest ostatecznie bardziej ludzkim rozwiązaniem ekonomicznym niż czysto technicznym.
Skalowalność
Jedną z powszechnych obaw związanych z Ethereum jest kwestia skalowalności. Podobnie do Bitcoina, Ethereum cierpi z powodu wady, która opiera się na konieczności przetwarzania każdej transakcji przez każdy węzeł sieci. W przypadku Bitcoina obecny rozmiar blockchaina wynosi około 15 GB i zwiększa się o ok. 1 MB na godzinę. Jeśli sieć Bitcoin miałaby przetwarzać 2000 transakcji na sekundę jak Visa, jej rozmiar rósłby o 1 MB co trzy sekundy (1 GB na godzinę, 8 TB rocznie). Ethereum prawdopodobnie będzie podlegać podobnemu schematowi wzrostu, pogorszonemu przez fakt, że na blockchainie Ethereum będzie wiele aplikacji, a nie tylko waluta, jak w przypadku Bitcoina. Sytuację tę złagodzi jednak fakt, że pełne węzły Ethereum będą musiały przechowywać tylko stan, a nie całą historię blockchaina.
Problem z tak dużą wielkością blockchainu to ryzyko centralizacji. Jeśli wielkość blockchaina wzrośnie do powiedzmy 100 TB, wówczas prawdopodobnym scenariuszem stanie się taki, w którym bardzo mała liczba wielkich przedsiębiorstw utrzymywałaby pełne węzły, a wszyscy normalni użytkownicy używaliby lekkich węzłów SPV. W takiej sytuacji powstaje potencjalne ryzyko, że pełne węzły zgrupują się i dogadają oszustwo w jakiś sposób zapewniający im zysk (np. zmieniając nagrodę za blok, przyznając sobie BTC). Lekkie węzły nie miałyby możliwości natychmiastowego wykrycia tej sytuacji. Oczywiście, prawdopodobnie istniałby co najmniej jeden uczciwy, pełny węzeł i po kilku godzinach informacja o oszustwie wyciekłaby przez kanały takie jak Reddit, ale wtedy byłoby już za późno: zwykli użytkownicy musieliby zorganizować akcję umieszczenia danych bloków na czarnej liście, co stanowiłoby ogromny i prawdopodobnie niewykonalny problem koordynacyjny na skalę porównywalną do przeprowadzenia udanego ataku 51%. W przypadku Bitcoina jest to obecnie problem, ale istnieje modyfikacja blockchainu zaproponowana przez Petera Todda (opens in a new tab), która złagodzi ten problem.
W bliskiej przyszłości Ethereum zastosuje dwie dodatkowe strategie przeciwdziałania temu problemowi. Po pierwsze, z uwagi na mechanizmy kopania oparte na blockchainie, każdy górnik będzie zmuszony utrzymywać pełny węzeł, przez co wytworzy się dolna granica liczby pełnych węzłów. Po drugie, co istotniejsze, dołączony do blockchaina zostanie pośredni korzeń drzewa stanu po przetworzeniu każdej transakcji. Nawet jeśli walidacja bloków jest scentralizowana, problem centralizacji można obejść za pomocą protokołu weryfikacji, o ile istnieje jeden uczciwy węzeł weryfikujący. Jeśli górnik opublikuje nieprawidłowy blok, to blok ten musi być źle sformatowany lub stan S[n] jest niepoprawny. Ponieważ wiadomo, że S[0] jest poprawne, musi istnieć jakiś pierwszy stan S[i], który jest niepoprawny, tam gdzie S[i-1] jest poprawne. Węzeł weryfikujący dostarczyłby indeks i wraz z „dowodem nieważności” składającym się z podzbioru węzłów drzewa Patricia, które muszą przetworzyć APPLY(S[i-1],TX[i]) -> S[i]. Węzły mogłyby używać tych węzłów do wykonywania tej części obliczeń i stwierdzać, że wygenerowany S[i] nie pasuje do podanego S[i].
Inny, bardziej wyrafinowany atak polegałby na tym, że złośliwi górnicy publikowaliby niekompletne bloki, tak że nie istniałyby nawet pełne informacje pozwalające określić, czy bloki są prawidłowe. Rozwiązaniem tego problemu jest protokół typu wyzwanie-odpowiedź: węzły weryfikacyjne wystawiają „wyzwania” w formie docelowych indeksów transakcji, a po otrzymaniu węzła węzeł lekki traktuje blok jako niezaufany, dopóki inny węzeł, niezależnie od tego, czy jest to górnik, czy inny weryfikator, nie dostarczy podzbioru węzłów Patricia jako dowodu ważności.
Wnioski
Protokół Ethereum został pierwotnie pomyślany jako ulepszona wersja kryptowaluty, zapewniająca zaawansowane funkcje, takie jak depozyt w ramach łańcucha bloków, limity wypłat, kontrakty finansowe, rynki hazardowe i tym podobne, za pośrednictwem wysoce uogólnionego języka programowania. Protokół Ethereum nie „obsługiwałby” bezpośrednio żadnej z aplikacji, ale istnienie języka programowania z kompletnością Turinga oznacza, że teoretycznie możliwe jest tworzenie dowolnych kontraktów dla dowolnego typu transakcji lub aplikacji. Co jednak ciekawsze w przypadku Ethereum, to fakt, że protokół Ethereum wykracza daleko poza samą walutę. Protokoły dotyczące zdecentralizowanego przechowywania plików, zdecentralizowanych obliczeń i zdecentralizowanych rynków predykcyjnych, a także dziesiątki innych podobnych koncepcji, mają potencjał znacznego zwiększenia wydajności branży obliczeniowej i zapewnienia dużego wsparcia innym protokołom peer-to-peer poprzez dodanie po raz pierwszy warstwy ekonomicznej. Wreszcie, istnieje również pokaźna gama aplikacji, które nie mają nic wspólnego z pieniędzmi.
Koncepcja dowolnej funkcji przejścia stanu, zaimplementowana w protokole Ethereum, zapewnia platformę o wyjątkowym potencjale. Zamiast być zamkniętym protokołem o jednym przeznaczeniu, przeznaczonym do określonej gamy zastosowań w zakresie przechowywania danych, hazardu lub finansów, Ethereum jest z założenia otwarte i wierzymy, że doskonale nadaje się do pełnienia funkcji warstwy bazowej dla bardzo dużej liczby protokołów finansowych i niefinansowych w nadchodzących latach.
Uwagi i dalsze lektury
Uwagi
- Doświadczony czytelnik może zauważyć, że adres Bitcoin to tak naprawdę skrót klucza publicznego w postaci krzywej eliptycznej, a nie sam klucz publiczny. Jednak w rzeczywistości całkowicie uzasadniona jest terminologia kryptograficzna określająca hash pubkey jako sam klucz publiczny. Dzieje się tak, ponieważ kryptografię Bitcoina można uznać za niestandardowy algorytm podpisu cyfrowego, w którym klucz publiczny składa się z skrótu klucza publicznego ECC, podpis składa się z klucza publicznego ECC połączonego z podpisem ECC, a algorytm weryfikacji obejmuje sprawdzenie klucza publicznego ECC w podpisie względem skrótu klucza publicznego ECC podanego jako klucz publiczny, a następnie weryfikację podpisu ECC względem klucza publicznego ECC.
- Technicznie mediana 11 poprzednich bloków.
- Wewnętrznie zarówno 2, jak i „CHARLIE” są liczbamifn3, przy czym ta druga jest zapisana w systemie big-endian o podstawie 256. Liczby mogą wynosić co najmniej 0 i co najwyżej 2256-1.
Dalsza lektura
- Wartość wewnętrzna (opens in a new tab)
- Inteligentna własność (opens in a new tab)
- Inteligentne kontrakty (opens in a new tab)
- B-money (opens in a new tab)
- Dowody pracy wielokrotnego użytku (opens in a new tab)
- Bezpieczne tytuły własności z upoważnieniem właściciela (opens in a new tab)
- Biała księga Bitcoina (opens in a new tab)
- Namecoin (opens in a new tab)
- Trójkąt Zooko (opens in a new tab)
- Biała księga kolorowych monet (opens in a new tab)
- Biała księga Mastercoin (opens in a new tab)
- Zdecentralizowane korporacje autonomiczne, Bitcoin Magazine (opens in a new tab)
- Uproszczona weryfikacja płatności (opens in a new tab)
- Drzewa Merkle (opens in a new tab)
- Drzewa Patricia (opens in a new tab)
- GHOST (opens in a new tab)
- StorJ i autonomiczni agenci, Jeff Garzik (opens in a new tab)
- Mike Hearn o inteligentnej własności na Turing Festival (opens in a new tab)
- RLP Ethereum
- Drzewa Merkle Patricia w Ethereum
- Peter Todd o drzewach sum Merkle (opens in a new tab)
Historia białej księgi znajduje się na tej stronie wiki (opens in a new tab).
_Ethereum, podobnie jak wiele projektów oprogramowania open-source tworzonych przez społeczność, rozwija się od czasu jego początkowego powstania. Aby dowiedzieć się o najnowszych zmianach w Ethereum i o tym, jak wprowadzane są zmiany w protokole, polecamy ten przewodnik.