Протокол Етеріум проходить своє найзначніше оновлення масштабування з моменту впровадження транзакцій з блобами за допомогою EIP-4844. Як частина оновлення Фусака, PeerDAS запроваджує новий спосіб обробки даних блобів, забезпечуючи збільшення пропускної здатності доступності даних (DA) для рівнів 2 (l2) приблизно на порядок.
Більше про дорожню карту масштабування блобів (відкривається в новій вкладці)
Масштабованість
Бачення Етеріуму полягає в тому, щоб бути нейтральною, безпечною та децентралізованою платформою, доступною для кожного у світі. Оскільки використання мережі зростає, це вимагає балансування трилеми масштабу, безпеки та децентралізації мережі. Якби Етеріум просто збільшив обсяг даних, що обробляються мережею в межах її поточної архітектури, він би ризикував перевантажити вузли, на які Етеріум покладається для своєї децентралізації. Масштабованість вимагає ретельного проєктування механізмів, що мінімізує компроміси.
Однією зі стратегій досягнення цієї мети є створення різноманітної екосистеми рішень для масштабування рівня 2 (l2), замість обробки всіх транзакцій у Головній мережі . або ролапи обробляють транзакції у своїх власних окремих ланцюгах і використовують Етеріум для верифікації та безпеки. Публікація лише критично важливих для безпеки фіксацій та стиснення корисного навантаження дозволяє рівням 2 (l2) ефективніше використовувати пропускну здатність DA Етеріуму. Своєю чергою, рівень 1 (l1) несе менше даних без шкоди для гарантій безпеки, тоді як рівні 2 (l2) залучають більше користувачів за нижчих витрат на газ. Спочатку рівні 2 (l2) публікували дані як calldata у звичайних транзакціях, які конкурували з транзакціями рівня 1 (l1) за газ і були непрактичними для масової доступності даних.
Прото-данкшардинг
Першим великим кроком до масштабування рівня 2 (l2) стало оновлення Денкун, яке запровадило прото-данкшардинг (EIP-4844). Це оновлення створило новий спеціалізований тип даних для ролапів, який називається блобами. Блоби (великі двійкові об'єкти) — це ефемерні фрагменти довільних даних, які не потребують виконання EVM і які вузли зберігають лише протягом обмеженого часу. Ця ефективніша обробка дозволила рівням 2 (l2) публікувати більше даних в Етеріумі та масштабуватися ще далі.
Попри те, що використання блобів уже має значні переваги для масштабування, це лише частина кінцевої мети. У поточному протоколі кожен вузол у мережі все ще повинен завантажувати кожен блоб. Вузьким місцем стає пропускна здатність, необхідна для окремих вузлів, оскільки обсяг даних, які потрібно завантажити, прямо зростає зі збільшенням кількості блобів.
Етеріум не йде на компроміси щодо децентралізації, і пропускна здатність є одним із найчутливіших параметрів. Навіть за наявності потужних обчислювальних ресурсів, широко доступних кожному, хто може собі це дозволити, обмеження пропускної здатності завантаження (відкривається в новій вкладці) навіть у високоурбанізованих містах розвинених країн (таких як Німеччина (відкривається в новій вкладці), Бельгія (відкривається в новій вкладці), Австралія (відкривається в новій вкладці) або Сполучені Штати (відкривається в новій вкладці)) можуть призвести до того, що вузли зможуть працювати лише з центрів обробки даних, якщо вимоги до пропускної здатності не будуть ретельно налаштовані.
Оператори вузлів стикаються з дедалі вищими вимогами до пропускної здатності та дискового простору в міру збільшення кількості блобів. Розмір і кількість блобів обмежуються цими факторами. Кожен блоб може містити до 128 кб даних, у середньому 6 блобів на блок. Це був лише перший крок до майбутньої архітектури, яка використовує блоби ще ефективніше.
Вибірка доступності даних
Доступність даних — це гарантія того, що всі дані, необхідні для незалежної перевірки ланцюга, доступні всім учасникам мережі. Це гарантує, що дані були повністю опубліковані та можуть бути використані для бездовіреної перевірки нового стану ланцюга або вхідних транзакцій.
Блоби Етеріуму забезпечують надійну гарантію доступності даних, що гарантує безпеку рівнів 2 (l2). Для цього вузли Етеріуму повинні завантажувати та зберігати блоби повністю. Але що, якби ми могли ефективніше розподіляти блоби в мережі та уникнути цього обмеження?
Іншим підходом до зберігання даних і забезпечення їхньої доступності є вибірка доступності даних (DAS). Замість того, щоб кожен комп'ютер, на якому працює Етеріум, повністю зберігав кожен окремий блоб, DAS запроваджує децентралізований розподіл праці. Він знімає тягар обробки даних, розподіляючи менші, керовані завдання по всій мережі вузлів. Блоби діляться на частини, і кожен вузол завантажує лише кілька частин, використовуючи механізм рівномірного випадкового розподілу між усіма вузлами.
Це створює нову проблему — доведення доступності та цілісності даних. Як мережа може гарантувати, що дані доступні та всі вони правильні, коли окремі вузли зберігають лише невеликі частини? Зловмисний вузол міг би надавати підроблені дані та легко порушити надійні гарантії доступності даних! Саме тут на допомогу приходить криптографія.
Щоб забезпечити цілісність даних, EIP-4844 вже було реалізовано з фіксаціями KZG. Це криптографічні докази, які створюються під час додавання нового блобу до мережі. Невеликий доказ включається в кожен блок, і вузли можуть перевірити, що отримані блоби відповідають фіксації KZG блоку.
DAS — це механізм, який базується на цьому та гарантує, що дані є правильними та доступними. Вибірка — це процес, під час якого вузол запитує лише невелику частину даних і перевіряє її на відповідність фіксації. KZG — це схема поліноміальної фіксації, що означає, що будь-яку окрему точку на поліноміальній кривій можна перевірити. Перевіривши лише кілька точок на поліномі, клієнт, який виконує вибірку, може мати надійну імовірнісну гарантію того, що дані доступні.
PeerDAS
PeerDAS (EIP-7594) (відкривається в новій вкладці) — це конкретна пропозиція, яка реалізує механізм DAS в Етеріумі, знаменуючи, ймовірно, найбільше оновлення з часів Злиття. PeerDAS розроблено для розширення даних блобів, поділяючи їх на стовпці та розподіляючи підмножину між вузлами.
Етеріум запозичує деяку розумну математику для досягнення цього: він застосовує кодування зі стиранням у стилі Ріда-Соломона до даних блобів. Дані блобів представлені у вигляді полінома, коефіцієнти якого кодують дані, потім цей поліном обчислюється в додаткових точках для створення розширеного блобу, подвоюючи кількість обчислень. Ця додана надмірність забезпечує відновлення після стирання: навіть якщо деякі обчислення відсутні, оригінальний блоб можна реконструювати, якщо доступна принаймні половина загального обсягу даних, включаючи розширені частини.
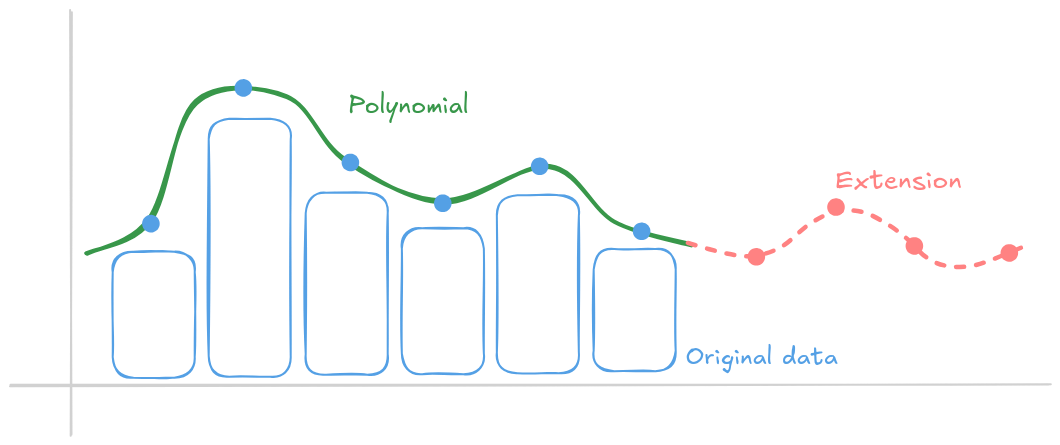
Насправді цей поліном має тисячі коефіцієнтів. Фіксації KZG — це значення в кілька байтів, щось на зразок хешу, відомі всім вузлам. Кожен вузол, що містить достатньо точок даних, може ефективно реконструювати повний набір даних блобу (відкривається в новій вкладці).
Цікавий факт: та сама техніка кодування використовувалася на DVD-дисках. Якщо ви подряпали DVD, програвач все одно міг його прочитати завдяки кодуванню Ріда-Соломона, яке додає відсутні частини полінома.
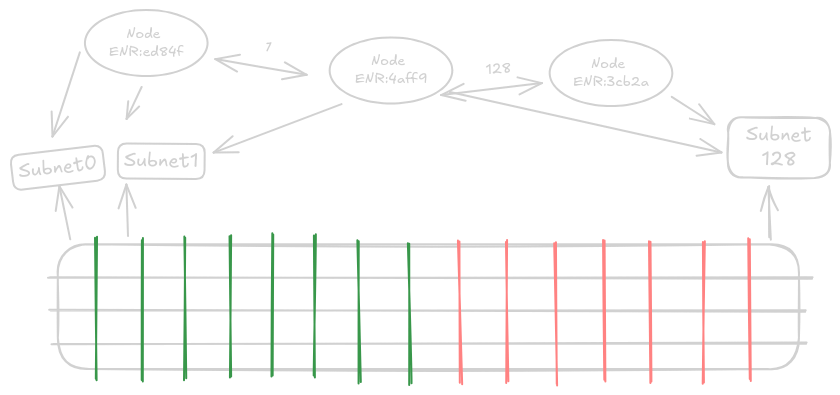
Історично дані в блокчейнах, будь то блоки чи блоби, транслювалися всім вузлам. З підходом PeerDAS до поділу та вибірки трансляція всього всім більше не є необхідною. Після оновлення Фусака мережа рівня консенсусу організована в теми/підмережі протоколу пліток: стовпці блобів призначаються певним підмережам, і кожен вузол підписується на заздалегідь визначені підмножини та зберігає лише ці частини.
З PeerDAS розширені дані блобів діляться на 128 частин, які називаються стовпцями. Дані розподіляються між цими вузлами через виділений протокол пліток у певних підмережах, на які вони підписані. Кожен звичайний вузол у мережі бере участь принаймні у 8 випадково вибраних підмережах стовпців. Отримання даних лише з 8 зі 128 підмереж означає, що цей стандартний вузол отримує лише 1/16 усіх даних, але оскільки дані були розширені, це становить 1/8 від початкових даних.
Це дозволяє досягти нової теоретичної межі масштабування, що у 8 разів перевищує поточну схему «кожен завантажує все». Оскільки вузли підписуються на різні випадкові підмережі, що обслуговують стовпці блобів, існує дуже висока ймовірність того, що вони рівномірно розподілені, і тому кожна частина даних існує десь у мережі. Вузли, на яких працюють валідатори, зобов'язані підписуватися на більшу кількість підмереж з кожним запущеним валідатором.
Кожен вузол має унікальний випадково згенерований ідентифікатор, який зазвичай слугує його публічною ідентичністю для з'єднань. У PeerDAS це число використовується для визначення випадкового набору підмереж, на які він повинен підписатися, що призводить до рівномірного випадкового розподілу всіх даних блобів.
Щойно вузол успішно реконструює початкові дані, він перерозподіляє відновлені стовпці назад у мережу, активно усуваючи будь-які прогалини в даних і підвищуючи загальну стійкість системи. Вузли, підключені до валідаторів із загальним балансом ≥4096 ETH, повинні бути супервузлами, а отже, повинні підписуватися на всі підмережі стовпців даних і зберігати всі стовпці. Ці супервузли будуть постійно усувати прогалини в даних. Імовірнісна природа протоколу, що самовідновлюється, забезпечує надійні гарантії доступності, не обмежуючи при цьому домашніх операторів, які зберігають лише частини даних.
Доступність даних може бути підтверджена будь-яким вузлом, що містить лише невелику підмножину даних блобу, завдяки механізму вибірки, описаному вище. Ця доступність є обов'язковою: валідатори повинні дотримуватися нових правил вибору форку, що означає, що вони прийматимуть і віддаватимуть голос за блоки лише після того, як перевірять доступність даних.
Прямим наслідком для користувачів (зокрема користувачів рівня 2 (l2)) є нижчі комісії. Завдяки у 8 разів більшому простору для даних ролапів, операції користувачів у їхньому ланцюзі з часом стають ще дешевшими. Але зниження комісій після оновлення Фусака потребуватиме часу та залежатиме від BPO.
Тільки параметри блобів (BPO)
Теоретично мережа зможе обробляти у 8 разів більше блобів, але збільшення кількості блобів — це зміна, яку потрібно належним чином протестувати та безпечно виконати крок за кроком. Тестові мережі забезпечують достатню впевненість для того, щоб розгортати функції в Головній мережі, але нам потрібно переконатися в стабільності p2p-мережі, перш ніж увімкнути значно більшу кількість блобів.
Щоб поступово збільшувати цільову кількість блобів на блок без перевантаження мережі, Фусака запроваджує форки тільки для параметрів блобів (BPO) (відкривається в новій вкладці). На відміну від звичайних форків, які потребують широкої координації екосистеми, згоди та оновлення програмного забезпечення, BPO (EIP-7892) (відкривається в новій вкладці) — це попередньо запрограмовані оновлення, які з часом збільшують максимальну кількість блобів без втручання.
Це означає, що відразу після активації оновлення Фусака та запуску PeerDAS кількість блобів залишиться незмінною. Кількість блобів почне подвоюватися кожні кілька тижнів, доки не досягне максимуму в 48, тоді як розробники здійснюватимуть моніторинг, щоб переконатися, що механізм працює належним чином і не має негативного впливу на вузли, що підтримують роботу мережі.
Майбутні напрямки
PeerDAS — це лише крок до ширшого бачення масштабування FullDAS (відкривається в новій вкладці), або данкшардингу. У той час як PeerDAS використовує 1D кодування зі стиранням для кожного блобу окремо, повний данкшардинг використовуватиме більш повну схему 2D кодування зі стиранням для всієї матриці даних блобів. Розширення даних у двох вимірах створює ще сильніші властивості надмірності та ефективнішу реконструкцію та верифікацію. Реалізація FullDAS вимагатиме суттєвих оптимізацій мережі та протоколу, а також додаткових досліджень.
Подальше читання
- PeerDAS: Вибірка доступності даних між вузлами від Франческо Д'Амато (Francesco D'Amato) (відкривається в новій вкладці)
- Документація PeerDAS Етеріуму (відкривається в новій вкладці)
- Доведення безпеки PeerDAS без AGM (відкривається в новій вкладці)
- Віталік про PeerDAS, його вплив та тестування оновлення Фусака (відкривається в новій вкладці)