Prove di Merkle per l'integrità dei dati offline
Introduzione
Idealmente vorremmo archiviare tutto nello spazio di archiviazione di Ethereum, che è distribuito su migliaia di computer e ha una disponibilità estremamente elevata (i dati non possono essere censurati) e integrità (i dati non possono essere modificati in modo non autorizzato), ma l'archiviazione di una parola di 32 byte costa in genere 20.000 gas. Nel momento in cui scrivo, questo costo equivale a 6,60 $. A 21 centesimi per byte, è troppo costoso per molti usi.
Per risolvere questo problema, l'ecosistema di Ethereum ha sviluppato molti modi alternativi per archiviare i dati in modo decentralizzato. Di solito comportano un compromesso tra disponibilità e prezzo. Tuttavia, l'integrità è generalmente assicurata.
In questo articolo imparerai come garantire l'integrità dei dati senza archiviarli sulla blockchain, utilizzando le prove di Merkle (si apre in una nuova scheda).
Come funziona?
In teoria potremmo semplicemente archiviare l'hash dei dati onchain e inviare tutti i dati nelle transazioni che lo richiedono. Tuttavia, questo è ancora troppo costoso. Un byte di dati in una transazione costa circa 16 gas, attualmente circa mezzo centesimo, o circa 5 $ per kilobyte. A 5000 $ per megabyte, è ancora troppo costoso per molti usi, anche senza il costo aggiuntivo dell'hashing dei dati.
La soluzione è eseguire ripetutamente l'hashing di diversi sottoinsiemi di dati, in modo che per i dati che non è necessario inviare si possa semplicemente inviare un hash. Lo si fa utilizzando un albero di Merkle, una struttura dati ad albero in cui ogni nodo è un hash dei nodi sottostanti:
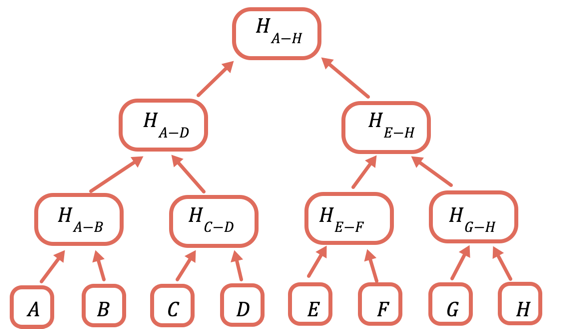
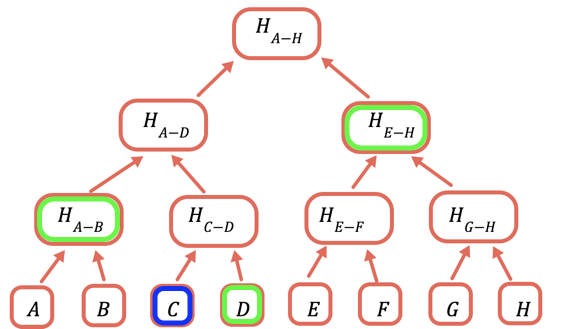
L'hash della radice è l'unica parte che deve essere archiviata onchain. Per dimostrare un certo valore, fornisci tutti gli hash che devono essere combinati con esso per ottenere la radice. Ad esempio, per dimostrare C fornisci D, H(A-B) e H(E-H).
Implementazione
Il codice di esempio è fornito qui (si apre in una nuova scheda).
Codice offchain
In questo articolo utilizziamo JavaScript per i calcoli offchain. La maggior parte delle applicazioni decentralizzate ha il proprio componente offchain in JavaScript.
Creazione della radice di Merkle
Per prima cosa dobbiamo fornire la radice di Merkle alla catena.
const ethers = require("ethers")
Utilizziamo la funzione di hash dal pacchetto ethers (si apre in una nuova scheda).
// I dati grezzi di cui dobbiamo verificare l'integrità. I primi due byte s
// ono un identificatore utente, e gli ultimi due byte la quantità di token che l'
// utente possiede attualmente.
const dataArray = [
0x0bad0010, 0x60a70020, 0xbeef0030, 0xdead0040, 0xca110050, 0x0e660060,
0xface0070, 0xbad00080, 0x060d0091,
]
La codifica di ogni voce in un singolo intero a 256 bit produce un codice meno leggibile rispetto all'utilizzo di JSON, ad esempio. Tuttavia, questo significa un'elaborazione significativamente inferiore per recuperare i dati nel contratto, quindi costi del gas molto più bassi. Puoi leggere JSON onchain (si apre in una nuova scheda), è solo una cattiva idea se evitabile.
// L'array dei valori di hash, come BigInt
const hashArray = dataArray
In questo caso i nostri dati sono valori a 256 bit in partenza, quindi non è necessaria alcuna elaborazione. Se utilizziamo una struttura dati più complicata, come le stringhe, dobbiamo assicurarci di eseguire prima l'hashing dei dati per ottenere un array di hash. Nota che questo è anche perché non ci interessa se gli utenti conoscono le informazioni di altri utenti. Altrimenti avremmo dovuto eseguire l'hashing in modo che l'utente 1 non conosca il valore per l'utente 0, l'utente 2 non conosca il valore per l'utente 3, ecc.
// Converte tra la stringa che la funzione di hash si aspetta e il
// BigInt che usiamo ovunque altrove.
const hash = (x) =>
BigInt(ethers.utils.keccak256("0x" + x.toString(16).padStart(64, 0)))
La funzione di hash di ethers si aspetta di ricevere una stringa JavaScript con un numero esadecimale, come 0x60A7, e risponde con un'altra stringa con la stessa struttura. Tuttavia, per il resto del codice è più facile usare BigInt, quindi convertiamo in una stringa esadecimale e viceversa.
// Hash simmetrico di una coppia, così non ci importerà se l'ordine è invertito.
const pairHash = (a, b) => hash(hash(a) ^ hash(b))
Questa funzione è simmetrica (hash di a xor (si apre in una nuova scheda) b). Ciò significa che quando controlliamo la prova di Merkle non dobbiamo preoccuparci se inserire il valore della prova prima o dopo il valore calcolato. Il controllo della prova di Merkle viene eseguito onchain, quindi meno dobbiamo fare lì, meglio è.
Attenzione:
La crittografia è più difficile di quanto sembri.
La versione iniziale di questo articolo aveva la funzione di hash hash(a^b).
È stata una cattiva idea perché significava che se conoscevi i valori legittimi di a e b potevi usare b' = a^b^a' per dimostrare qualsiasi valore a' desiderato.
Con questa funzione dovresti calcolare b' in modo tale che hash(a') ^ hash(b') sia uguale a un valore noto (il ramo successivo sulla strada verso la radice), il che è molto più difficile.
// Il valore per indicare che un certo ramo è vuoto, non
// ha un valore
const empty = 0n
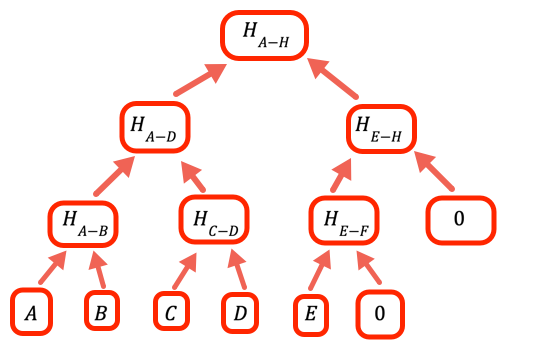
Quando il numero di valori non è una potenza intera di due, dobbiamo gestire i rami vuoti. Il modo in cui questo programma lo fa è inserire zero come segnaposto.
// Calcola un livello superiore dell'albero di un array di hash prendendo l'hash di
// ogni coppia in sequenza
const oneLevelUp = (inputArray) => {
var result = []
var inp = [...inputArray] // Per evitare di sovrascrivere l'input // Aggiunge un valore vuoto se necessario (abbiamo bisogno che tutte le foglie siano // accoppiate)
if (inp.length % 2 === 1) inp.push(empty)
for (var i = 0; i < inp.length; i += 2)
result.push(pairHash(inp[i], inp[i + 1]))
return result
} // oneLevelUp
Questa funzione "sale" di un livello nell'albero di Merkle eseguendo l'hashing delle coppie di valori al livello corrente. Nota che questa non è l'implementazione più efficiente, avremmo potuto evitare di copiare l'input e aggiungere semplicemente hashEmpty quando appropriato nel ciclo, ma questo codice è ottimizzato per la leggibilità.
const getMerkleRoot = (inputArray) => {
var result
result = [...inputArray] // Risale l'albero finché non c'è un solo valore, ovvero la // radice. // // Se un livello ha un numero dispari di voci, il // codice in oneLevelUp aggiunge un valore vuoto, quindi se abbiamo, per esempio, // 10 foglie avremo 5 rami nel secondo livello, 3 // rami nel terzo, 2 nel quarto e la radice è il quinto
while (result.length > 1) result = oneLevelUp(result)
return result[0]
}
Per ottenere la radice, sali finché non rimane un solo valore.
Creazione di una prova di Merkle
Una prova di Merkle è costituita dai valori di cui eseguire l'hashing insieme al valore da dimostrare per riottenere la radice di Merkle. Il valore da dimostrare è spesso disponibile da altri dati, quindi preferisco fornirlo separatamente piuttosto che come parte del codice.
// Una prova di Merkle consiste nel valore della lista di voci con cui fare
// l'hash. Poiché usiamo una funzione di hash simmetrica, non
// abbiamo bisogno della posizione dell'elemento per verificare la prova, solo per crearla
const getMerkleProof = (inputArray, n) => {
var result = [], currentLayer = [...inputArray], currentN = n
// Finché non raggiungiamo la cima
while (currentLayer.length > 1) {
// Nessun livello di lunghezza dispari
if (currentLayer.length % 2)
currentLayer.push(empty)
result.push(currentN % 2
// Se currentN è dispari, aggiungi con il valore che lo precede alla prova
? currentLayer[currentN-1]
// Se è pari, aggiungi il valore che lo segue
: currentLayer[currentN+1])
Eseguiamo l'hashing di (v[0],v[1]), (v[2],v[3]), ecc. Quindi per i valori pari abbiamo bisogno di quello successivo, per i valori dispari di quello precedente.
// Passa al livello successivo superiore
currentN = Math.floor(currentN/2)
currentLayer = oneLevelUp(currentLayer)
} // while currentLayer.length > 1
return result
} // getMerkleProof
Codice onchain
Infine abbiamo il codice che controlla la prova. Il codice onchain è scritto in Solidity (si apre in una nuova scheda). L'ottimizzazione è molto più importante qui perché il gas è relativamente costoso.
//SPDX-License-Identifier: Public Domain
pragma solidity ^0.8.0;
import "hardhat/console.sol";
L'ho scritto utilizzando l'ambiente di sviluppo Hardhat (si apre in una nuova scheda), che ci consente di avere l'output della console da Solidity (si apre in una nuova scheda) durante lo sviluppo.
contract MerkleProof {
uint merkleRoot;
function getRoot() public view returns (uint) {
return merkleRoot;
}
// Estremamente insicuro, nel codice di produzione l'accesso a
// questa funzione DEVE ESSERE strettamente limitato, probabilmente a un
// proprietario
function setRoot(uint _merkleRoot) external {
merkleRoot = _merkleRoot;
} // setRoot
Funzioni set e get per la radice di Merkle. Lasciare che chiunque aggiorni la radice di Merkle è un'idea estremamente pessima in un sistema di produzione. Lo faccio qui per motivi di semplicità per il codice di esempio. Non farlo su un sistema in cui l'integrità dei dati è davvero importante.
function hash(uint _a) internal pure returns(uint) {
return uint(keccak256(abi.encode(_a)));
}
function pairHash(uint _a, uint _b) internal pure returns(uint) {
return hash(hash(_a) ^ hash(_b));
}
Questa funzione genera un hash di coppia. È solo la traduzione in Solidity del codice JavaScript per hash e pairHash.
Nota: Questo è un altro caso di ottimizzazione per la leggibilità. In base alla definizione della funzione (si apre in una nuova scheda), potrebbe essere possibile archiviare i dati come valore bytes32 (si apre in una nuova scheda) ed evitare le conversioni.
// Verifica una prova di Merkle
function verifyProof(uint _value, uint[] calldata _proof)
public view returns (bool) {
uint temp = _value;
uint i;
for(i=0; i<_proof.length; i++) {
temp = pairHash(temp, _proof[i]);
}
return temp == merkleRoot;
}
} // MarkleProof
Nella notazione matematica la verifica della prova di Merkle si presenta così: H(proof_n, H(proof_n-1, H(proof_n-2, ... H(proof_1, H(proof_0, value))...))). Questo codice la implementa.
Le prove di Merkle e i rollup non vanno d'accordo
Le prove di Merkle non funzionano bene con i rollup. Il motivo è che i rollup scrivono tutti i dati della transazione sul layer 1 (l1), ma li elaborano sul layer 2 (l2). Il costo per inviare una prova di Merkle con una transazione è in media di 638 gas per livello (attualmente un byte nei dati di chiamata costa 16 gas se non è zero, e 4 se è zero). Se abbiamo 1024 parole di dati, una prova di Merkle richiede dieci livelli, ovvero un totale di 6380 gas.
Guardando ad esempio a Optimism (si apre in una nuova scheda), la scrittura del gas su l1 costa circa 100 Gwei e il gas su l2 costa 0,001 Gwei (questo è il prezzo normale, può aumentare con la congestione). Quindi, per il costo di un gas su l1 possiamo spendere centomila gas per l'elaborazione su l2. Supponendo di non sovrascrivere l'archiviazione, ciò significa che possiamo scrivere circa cinque parole nell'archiviazione su l2 al prezzo di un gas su l1. Per una singola prova di Merkle possiamo scrivere tutte le 1024 parole nell'archiviazione (supponendo che possano essere calcolate onchain in partenza, piuttosto che fornite in una transazione) e avere ancora la maggior parte del gas avanzato.
Conclusione
Nella vita reale potresti non implementare mai gli alberi di Merkle da solo. Ci sono librerie ben note e controllate che puoi usare e, in generale, è meglio non implementare primitive crittografiche da soli. Ma spero che ora tu capisca meglio le prove di Merkle e possa decidere quando vale la pena usarle.
Nota che mentre le prove di Merkle preservano l'integrità, non preservano la disponibilità. Sapere che nessun altro può prendere i tuoi asset è una magra consolazione se l'archiviazione dei dati decide di negare l'accesso e non puoi nemmeno costruire un albero di Merkle per accedervi. Quindi gli alberi di Merkle sono usati al meglio con un qualche tipo di archiviazione decentralizzata, come IPFS.
Vedi qui per altri miei lavori (si apre in una nuova scheda).