Il protocollo Ethereum sta subendo il suo aggiornamento di scalabilità più significativo dall'introduzione delle transazioni blob con l'EIP-4844. Come parte dell'aggiornamento Fusaka, PeerDAS introduce un nuovo modo di gestire i dati dei blob, offrendo un aumento di circa un ordine di grandezza nella capacità di disponibilità dei dati (DA) per i layer 2 (l2).
Maggiori informazioni sulla roadmap di scalabilità dei blob (si apre in una nuova scheda)
Scalabilità
La visione di Ethereum è quella di essere una piattaforma neutrale, sicura e decentralizzata disponibile per chiunque nel mondo. Con la crescita dell'utilizzo della rete, ciò richiede di bilanciare il trilemma di scalabilità, sicurezza e decentralizzazione della rete. Se Ethereum aumentasse semplicemente i dati gestiti dalla rete all'interno del suo design attuale, correrebbe il rischio di sovraccaricare i nodi su cui Ethereum fa affidamento per la sua decentralizzazione. La scalabilità richiede una progettazione rigorosa dei meccanismi che riduca al minimo i compromessi.
Una delle strategie per raggiungere questo obiettivo è consentire un ecosistema diversificato di soluzioni di scalabilità di layer 2 (l2) piuttosto che elaborare tutte le transazioni sulla Mainnet di . I o rollup elaborano le transazioni sulle proprie catene separate e utilizzano Ethereum per la verifica e la sicurezza. La pubblicazione dei soli commitment critici per la sicurezza e la compressione dei payload consentono ai layer 2 (l2) di utilizzare la capacità di DA di Ethereum in modo più efficiente. A sua volta, il layer 1 (l1) trasporta meno dati senza compromettere le garanzie di sicurezza, mentre i layer 2 (l2) accolgono più utenti a costi del gas inferiori. Inizialmente, i layer 2 (l2) pubblicavano i dati come calldata in transazioni ordinarie, che competevano con le transazioni del layer 1 (l1) per il gas ed era poco pratico per la disponibilità dei dati in blocco.
Proto-Danksharding
Il primo passo importante verso la scalabilità dei layer 2 (l2) è stato l'aggiornamento Dencun, che ha introdotto il Proto-Danksharding (EIP-4844). Questo aggiornamento ha creato un nuovo tipo di dati specializzato per i rollup chiamato blob. I blob, o binary large object, sono porzioni effimere di dati arbitrari che non necessitano dell'esecuzione dell'EVM e che i nodi archiviano solo per un periodo di tempo limitato. Questa elaborazione più efficiente ha consentito ai layer 2 (l2) di pubblicare più dati su Ethereum e di scalare ulteriormente.
Nonostante abbia già forti vantaggi per la scalabilità, l'utilizzo dei blob è solo una parte dell'obiettivo finale. Nel protocollo attuale, ogni nodo della rete deve ancora scaricare ogni blob. Il collo di bottiglia diventa la larghezza di banda richiesta ai singoli nodi, con la quantità di dati che deve essere scaricata che aumenta direttamente con un numero maggiore di blob.
Ethereum non scende a compromessi sulla decentralizzazione e la larghezza di banda è uno dei parametri più sensibili. Anche con una potente capacità di calcolo ampiamente disponibile per chiunque possa permettersela, le limitazioni della larghezza di banda in upload (si apre in una nuova scheda) persino in città altamente urbanizzate di nazioni sviluppate (come Germania (si apre in una nuova scheda), Belgio (si apre in una nuova scheda), Australia (si apre in una nuova scheda) o Stati Uniti (si apre in una nuova scheda)) potrebbero limitare i nodi a poter essere eseguiti solo dai data center se i requisiti di larghezza di banda non vengono calibrati attentamente.
Gli operatori dei nodi hanno requisiti di larghezza di banda e spazio su disco sempre più elevati all'aumentare dei blob. Le dimensioni e la quantità dei blob sono limitate da questi vincoli. Ogni blob può trasportare fino a 128 kb di dati con una media di 6 blob per blocco. Questo è stato solo il primo passo verso un design futuro che utilizza i blob in modo ancora più efficiente.
Campionamento della disponibilità dei dati
La disponibilità dei dati è la garanzia che tutti i dati necessari per convalidare in modo indipendente la catena siano accessibili a tutti i partecipanti della rete. Garantisce che i dati siano stati completamente pubblicati e possano essere utilizzati per verificare in modo trustless il nuovo stato della catena o le transazioni in entrata.
I blob di Ethereum forniscono una forte garanzia di disponibilità dei dati che assicura la sicurezza dei layer 2 (l2). Per fare ciò, i nodi di Ethereum devono scaricare e archiviare i blob nella loro interezza. Ma cosa succederebbe se potessimo distribuire i blob nella rete in modo più efficiente ed evitare questa limitazione?
Un approccio diverso per archiviare i dati e garantirne la disponibilità è il campionamento della disponibilità dei dati (DAS). Invece che ogni computer che esegue Ethereum archivi completamente ogni singolo blob, il DAS introduce una divisione decentralizzata del lavoro. Suddivide l'onere dell'elaborazione dei dati distribuendo compiti più piccoli e gestibili sull'intera rete di nodi. I blob vengono divisi in parti e ogni nodo scarica solo alcune parti utilizzando un meccanismo per una distribuzione casuale uniforme su tutti i nodi.
Questo introduce un nuovo problema: dimostrare la disponibilità e l'integrità dei dati. Come può la rete garantire che i dati siano disponibili e che siano tutti corretti quando i singoli nodi detengono solo piccole parti? Un nodo malintenzionato potrebbe fornire dati falsi e infrangere facilmente le forti garanzie di disponibilità dei dati! È qui che la crittografia viene in aiuto.
Per garantire l'integrità dei dati, l'EIP-4844 è stato già implementato con i commitment KZG. Queste sono prove crittografiche create quando un nuovo blob viene aggiunto alla rete. Una piccola prova è inclusa in ogni blocco e i nodi possono verificare che i blob ricevuti corrispondano al commitment KZG del blocco.
Il DAS è un meccanismo che si basa su questo e garantisce che i dati siano sia corretti che disponibili. Il campionamento è un processo in cui un nodo interroga solo una piccola parte dei dati e la verifica rispetto al commitment. KZG è uno schema di commitment polinomiale, il che significa che qualsiasi singolo punto sulla curva polinomiale può essere verificato. Controllando solo un paio di punti sul polinomio, il client che esegue il campionamento può avere una forte garanzia probabilistica che i dati siano disponibili.
PeerDAS
PeerDAS (EIP-7594) (si apre in una nuova scheda) è una proposta specifica che implementa il meccanismo DAS in Ethereum, segnando probabilmente il più grande aggiornamento da The Merge. PeerDAS è progettato per estendere i dati dei blob, dividendoli in colonne e distribuendone un sottoinsieme ai nodi.
Ethereum prende in prestito un po' di matematica intelligente per ottenere questo risultato: applica la codifica a cancellazione in stile Reed-Solomon ai dati dei blob. I dati dei blob sono rappresentati come un polinomio i cui coefficienti codificano i dati, quindi valutano quel polinomio in punti aggiuntivi per creare un blob esteso, raddoppiando il numero di valutazioni. Questa ridondanza aggiunta consente il recupero della cancellazione: anche se mancano alcune valutazioni, il blob originale può essere ricostruito purché sia disponibile almeno la metà dei dati totali, comprese le parti estese.
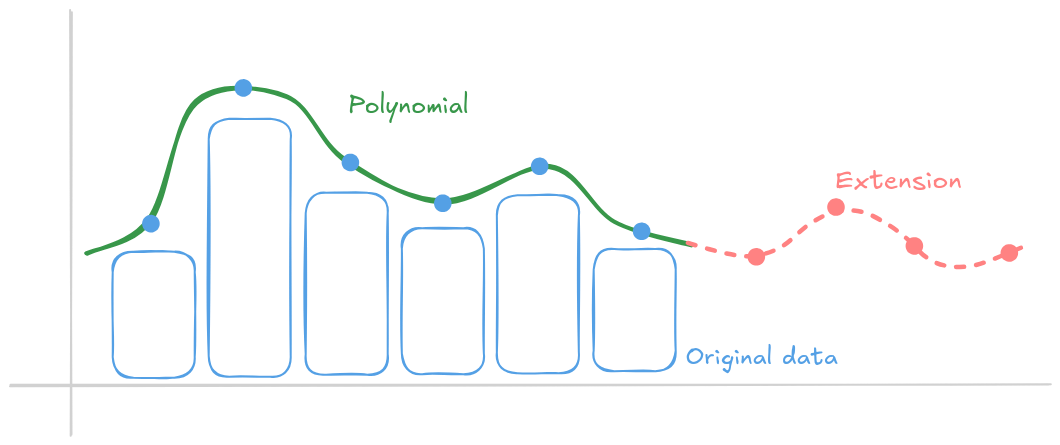
In realtà, questo polinomio ha migliaia di coefficienti. I commitment KZG sono valori di pochi byte, qualcosa di simile a un hash, noti a tutti i nodi. Ogni nodo che detiene abbastanza punti dati può ricostruire in modo efficiente un set completo di dati dei blob (si apre in una nuova scheda).
Curiosità: la stessa tecnica di codifica veniva utilizzata dai DVD. Se graffiavi un DVD, il lettore era ancora in grado di leggerlo grazie alla codifica Reed-Solomon che aggiunge le parti mancanti del polinomio.
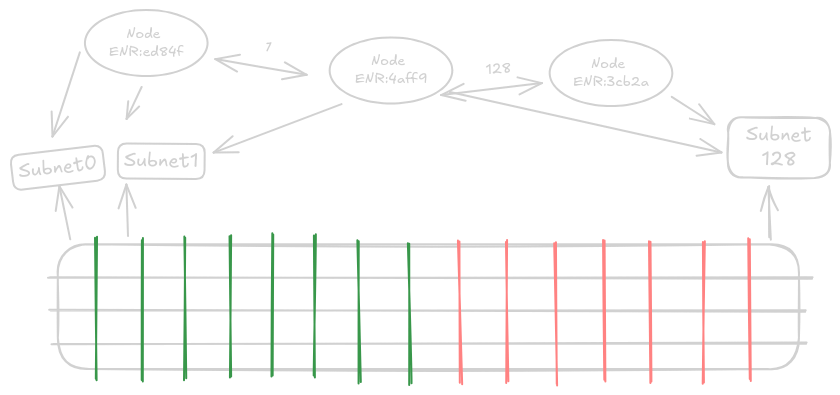
Storicamente, i dati nelle blockchain, che si trattasse di blocchi o blob, venivano trasmessi a tutti i nodi. Con l'approccio di divisione e campionamento di PeerDAS, non è più necessario trasmettere tutto a tutti. Dopo Fusaka, il networking del livello di consenso è organizzato in argomenti/sottoreti del protocollo gossip: le colonne dei blob vengono assegnate a sottoreti specifiche e ogni nodo si iscrive a sottoinsiemi predeterminati e custodisce solo quelle parti.
Con PeerDAS, i dati estesi dei blob sono divisi in 128 parti chiamate colonne. I dati vengono distribuiti a questi nodi tramite un protocollo gossip dedicato su sottoreti specifiche a cui sono iscritti. Ogni nodo regolare sulla rete partecipa ad almeno 8 sottoreti di colonne scelte casualmente. Ricevere dati da sole 8 delle 128 sottoreti significa che questo nodo predefinito riceve solo 1/16 di tutti i dati, ma poiché i dati sono stati estesi, questo corrisponde a 1/8 dei dati originali.
Ciò consente un nuovo limite teorico di scalabilità pari a 8 volte l'attuale schema in cui "tutti scaricano tutto". Con i nodi che si iscrivono a diverse sottoreti casuali che servono le colonne dei blob, la probabilità è molto alta che siano distribuiti uniformemente e quindi che ogni porzione di dati esista da qualche parte nella rete. I nodi che eseguono validatori sono tenuti a iscriversi a più sottoreti per ogni validatore che eseguono.
Ogni nodo ha un ID univoco generato casualmente, che normalmente funge da identità pubblica per le connessioni. In PeerDAS, questo numero viene utilizzato per determinare le sottoreti di un set casuale a cui deve iscriversi, risultando in una distribuzione casuale uniforme di tutti i dati dei blob.
Una volta che un nodo ricostruisce con successo i dati originali, ridistribuisce le colonne recuperate nella rete, sanando attivamente eventuali lacune nei dati e migliorando la resilienza complessiva del sistema. I nodi connessi a validatori con un saldo combinato ≥4096 ETH devono essere un supernodo e pertanto devono iscriversi a tutte le sottoreti delle colonne di dati e custodire tutte le colonne. Questi supernodi saneranno continuamente le lacune nei dati. La natura probabilisticamente auto-riparante del protocollo consente forti garanzie di disponibilità pur non limitando gli operatori domestici che detengono solo porzioni dei dati.
La disponibilità dei dati può essere confermata da qualsiasi nodo che detiene solo un piccolo sottoinsieme dei dati dei blob grazie al meccanismo di campionamento descritto sopra. Questa disponibilità è applicata rigorosamente: i validatori devono seguire le nuove regole di scelta del fork, il che significa che accetteranno e voteranno per i blocchi solo dopo aver verificato la disponibilità dei dati.
L'impatto diretto sugli utenti (in particolare gli utenti dei layer 2 (l2)) è la riduzione delle commissioni. Con uno spazio 8 volte maggiore per i dati dei rollup, le operazioni degli utenti sulla loro catena diventano ancora più economiche nel tempo. Ma le commissioni più basse dopo Fusaka richiederanno tempo e dipenderanno dai BPO.
Blob-Parameter-Only (BPO)
La rete sarà teoricamente in grado di elaborare 8 volte più blob, ma gli aumenti dei blob sono un cambiamento che deve essere adeguatamente testato ed eseguito in modo sicuro e graduale. Le reti di test forniscono sufficiente sicurezza per distribuire le funzionalità sulla Mainnet, ma dobbiamo garantire la stabilità della rete p2p prima di abilitare un numero significativamente più elevato di blob.
Per aumentare gradualmente il numero target di blob per blocco senza sovraccaricare la rete, Fusaka introduce i fork Blob-Parameter-Only (BPO) (si apre in una nuova scheda). A differenza dei fork regolari che necessitano di un ampio coordinamento dell'ecosistema, di accordi e di aggiornamenti software, i BPO (EIP-7892) (si apre in una nuova scheda) sono aggiornamenti pre-programmati che aumentano il numero massimo di blob nel tempo senza alcun intervento.
Ciò significa che immediatamente dopo l'attivazione di Fusaka e il lancio di PeerDAS, il numero di blob rimarrà invariato. Il numero di blob inizierà a raddoppiare ogni poche settimane fino a raggiungere un massimo di 48, mentre gli sviluppatori monitorano per garantire che il meccanismo funzioni come previsto e non abbia effetti negativi sui nodi che eseguono la rete.
Direzioni future
PeerDAS è solo un passo verso una visione di scalabilità più ampia del FullDAS (si apre in una nuova scheda), o danksharding. Mentre PeerDAS utilizza la codifica a cancellazione 1D per ogni blob individualmente, il danksharding completo utilizzerà uno schema di codifica a cancellazione 2D più completo sull'intera matrice dei dati dei blob. L'estensione dei dati in due dimensioni crea proprietà di ridondanza ancora più forti e una ricostruzione e verifica più efficienti. La realizzazione del FullDAS richiederà sostanziali ottimizzazioni della rete e del protocollo, insieme a ulteriori ricerche.
Letture consigliate
- PeerDAS: Peer Data Availability sampling di Francesco D'Amato (si apre in una nuova scheda)
- Una documentazione del PeerDAS di Ethereum (si apre in una nuova scheda)
- Dimostrare la sicurezza di PeerDAS senza l'AGM (si apre in una nuova scheda)
- Vitalik su PeerDAS, il suo impatto e il test di Fusaka (si apre in una nuova scheda)