オフラインデータの完全性のためのマークルプルーフ
はじめに
すべてのデータは、イーサリアムストレージに保存することが理想的です。このストレージは、数千ものコンピューターに保存され、非常に高い可用性(データは検閲されない)と完全性(データは不正に変更されない)を備えていますが、32バイトワードを保存するのに通常2万ガスがかかります。 執筆時点で、そのコストは$6.60に相当します。 1バイトごとに21セントかかるため、多くの用途には高すぎます。
この問題を解決するために、イーサリアムのエコシステムはデータを分散型の 方法で保存するための多くの代替手段を開発しました。 通常、これらは可用性と価格のトレードオフを伴います。 しかしながら、一般に完全性は保証されます。
この記事では、マークルプルーフ (opens in a new tab)を使用して、 ブロックチェーンにデータを保存せずにデータの完全性を確保する方法を学びます。
仕組み
理論上は、データのハッシュのみをオンチェーンに保存し、それを必要とするトランザクションですべてのデータを送信できます。 しかし、これでもまだ高すぎます。 1バイトのデータのトランザクションのコストは約16ガスで、現時点では0.5セントです。つまり、1キロバイトあたり約 $5になります。 1メガバイトでは $5000になり、データをハッシュ化するコストを差し引いても、多くの用途にはまだ高すぎます。
これを解決するには、異なるデータのサブセットを繰り返しハッシュ化します。そうすることで、データを送信する必要が無い場合は、ハッシュを送信するだけで済むようになります。 これを行うには、次のようなマークルツリーを使用します。このツリーは、それぞれのノードがその下のノードのハッシュとなるデータ構造を持ちます。
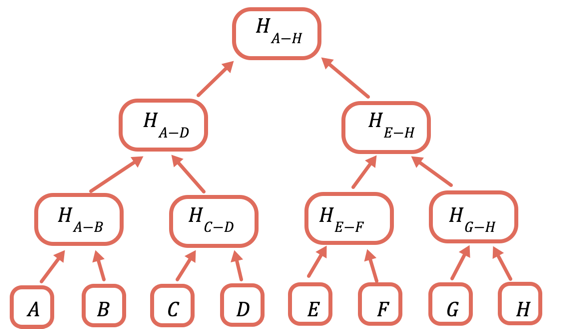
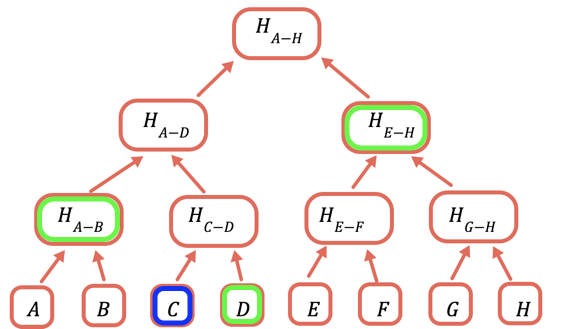
オンチェーンに保存する必要があるのはルートハッシュのみです。 特定の値を証明するには、ルートのハッシュを得るために、その値と結合させる必要があるハッシュをすべて提供します。 例えば、Cを証明するには、D、H(A-B)、H(E-H)を提供します。
実装
サンプルコードはこちらで提供されています (opens in a new tab)。
オフチェーンコード
この記事では、オフチェーンの計算にJavaScriptを使用します。 ほとんどの分散型アプリケーションには、JavaScriptのオフチェーンコンポーネントがあります。
マークルルートの作成
最初に、マークルルートをチェーンに提供する必要があります。
1const ethers = require("ethers")ethersパッケージのハッシュ関数を使用します (opens in a new tab)。
1// 完全性を検証する必要がある生データです。最初の2バイトは2// ユーザー識別子、最後の2バイトはユーザーが3// 現在所有しているトークンの量です。4const dataArray = [5 0x0bad0010, 0x60a70020, 0xbeef0030, 0xdead0040, 0xca110050, 0x0e660060,6 0xface0070, 0xbad00080, 0x060d0091,7]各エントリを単一の256ビット整数にエンコードすると、JSONを使用した場合などよりも読みにくいコードになります。 しかし、これによりコントラクト内のデータを取得するための処理量が大幅に削減され、ガス代も大幅に削減されます。 オンチェーンでJSONを読み込むことはできますが (opens in a new tab)、回避できるのであれば良いアイデアではありません。
1// BigIntとしてのハッシュ値の配列2const hashArray = dataArrayここでは、256ビット値のデータで始めるので、処理は必要ありません。 文字列型のようなより複雑なデータ構造を使用する場合は、まずデータをハッシュ化してハッシュ配列を取得する必要があります。 これは、ユーザーが他のユーザーの情報を知っていても知らなくても構わないことを前提にしているためでもあります。 さもなければ、ユーザー1がユーザー0の値がわからないように、ユーザー2がユーザー3の値がわからないように、というようなハッシュ化をしなければならなくなります。
1// ハッシュ関数が期待する文字列と2// 他の場所で使用するBigIntを相互に変換します。3const hash = (x) =>4 BigInt(ethers.utils.keccak256("0x" + x.toString(16).padStart(64, 0)))ethersのハッシュ関数は、0x60A7などの16進数のJavaScript文字列を受け取ることを想定しており、同じ構造の別の文字列で応答します。 ただし、コードの残りの部分ではBigIntを使用する方が簡単なので、16進数の文字列に変換して、また元に戻します。
1// 順序が逆でも気にしなくていいように、ペアを対称的にハッシュ化します。2const pairHash = (a, b) => hash(hash(a) ^ hash(b))この関数は対称的です(a xor (opens in a new tab) b のハッシュ)。 そのため、マークルプルーフを確認するときに、計算された値の前と後のどちらにプルーフの値を配置すべきかについて考慮する必要はありません。 マークルプルーフの確認はオンチェーンで行われるので、必要な処理が少ないほど良いとされます。
警告: 暗号技術は見た目以上に難解です。
この記事の初版では、ハッシュ関数hash(a^b)を使用していました。
これは悪いアイデアでした。なぜなら、aとbの正当な値を知っていれば、b' = a^b^a'を使って任意のa'の値を証明できてしまうからです。
この関数では、hash(a') ^ hash(b')が既知の値(ルートに向かう途中の次のブランチ)と等しくなるようにb'を計算する必要があり、これははるかに困難です。
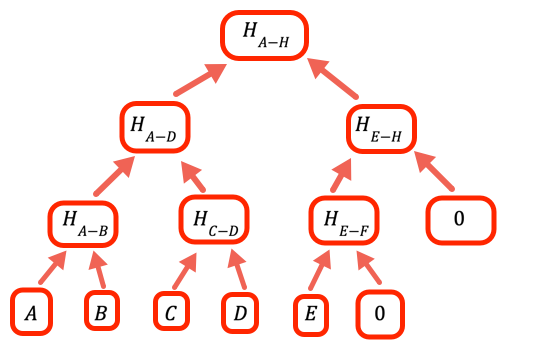
1// あるブランチが空で、値を2// 持たないことを示すための値です。3const empty = 0n値の数が2の整数乗ではない時は、空のブランチを処理する必要があります。 このプログラムでは、ゼロをプレースホルダーとして配置する方法を使っています。
1// 各ペアを順番にハッシュ化することで、ハッシュ配列のツリーを1レベル上に計算します。2const oneLevelUp = (inputArray) => {3 var result = []4 var inp = [...inputArray] // 入力の上書きを避けるため // 必要であれば空の値を追加します (すべてのリーフが // ペアになるようにする必要があります)5
6 if (inp.length % 2 === 1) inp.push(empty)7
8 for (var i = 0; i < inp.length; i += 2)9 result.push(pairHash(inp[i], inp[i + 1]))10
11 return result12} // oneLevelUpこの関数は、現在のレイヤーで値のペアをハッシュ化すると、マークルツリーを1レベル「登り」ます。 これは最も効率的な実装ではないことに注意してください。入力のコピーを避け、ループ内で適切なときにhashEmptyを追加することもできましたが、このコードは読みやすさを重視して最適化されています。
1const getMerkleRoot = (inputArray) => {2 var result3
4 result = [...inputArray] // 値が1つだけになるまでツリーを登ります。それが // ルートです。 // // レイヤーのエントリ数が奇数の場合、 // oneLevelUpのコードが空の値を追加するため、例えば、 // 10個のリーフがあれば、第2レイヤーには5個のブランチ、 // 第3レイヤーには3個のブランチ、第4レイヤーには2個、そしてルートが5番目になります。5
6 while (result.length > 1) result = oneLevelUp(result)7
8 return result[0]9}ルートを得るには、残っている値が1つしかないところまで登ります。
マークルプルーフの作成
マークルプルーフは、マークルルートを得るために、証明される値と一緒にハッシュ化する値です。 証明する値は、他のデータから入手することが多いため、コードの一部としてではなく、別に提供することをお勧めします。
1// マークルプルーフは、一緒にハッシュ化するエントリのリストの値で2// 構成されます。対称的なハッシュ関数を使用しているため、プルーフの検証に3// アイテムの位置は不要で、作成時にのみ必要です。4const getMerkleProof = (inputArray, n) => {5 var result = [], currentLayer = [...inputArray], currentN = n6
7 // トップに到達するまで8 while (currentLayer.length > 1) {9 // レイヤーの長さが奇数にならないようにする10 if (currentLayer.length % 2)11 currentLayer.push(empty)12
13 result.push(currentN % 214 // currentNが奇数の場合、その前の値をプルーフに追加します15 ? currentLayer[currentN-1]16 // 偶数の場合、その後の値を追加します17 : currentLayer[currentN+1])18
(v[0],v[1])、(v[2],v[3])などをハッシュ化します。 したがって、偶数の値の場合はその次の値、基数の値の場合は1つ前の値が必要です。
1 // 上のレイヤーに移動します2 currentN = Math.floor(currentN/2)3 currentLayer = oneLevelUp(currentLayer)4 } // while currentLayer.length > 15
6 return result7} // getMerkleProofオンチェーンコード
最後は、証明を確認するコードです。 オンチェーンコードはSolidity (opens in a new tab)で記述されています。 ガス代が比較的高価なため、ここでは最適化がかなり重要になります。
1//SPDX-License-Identifier: Public Domain2pragma solidity ^0.8.0;3
4import "hardhat/console.sol";これはHardhat開発環境 (opens in a new tab)を使用して作成しました。これにより、開発中にSolidityからのコンソール出力 (opens in a new tab)が可能になります。
1
2contract MerkleProof {3 uint merkleRoot;4
5 function getRoot() public view returns (uint) {6 return merkleRoot;7 }8
9 // 非常に安全性が低い。本番コードでは、この関数への10 // アクセスを、おそらくオーナーに11 // 限定するなど、厳しく制限する必要があります。12 function setRoot(uint _merkleRoot) external {13 merkleRoot = _merkleRoot;14 } // setRootマークルルート用のset関数とget関数が書かれています。 本番システムで誰でもマークルルートを更新できるようにすることは、_極めて悪いアイデア_です。 ここでは、サンプルコードをシンプルにするために、あえて行っています。 データの完全性が実際に重要となるシステムでは、これを行わないでください。
1 function hash(uint _a) internal pure returns(uint) {2 return uint(keccak256(abi.encode(_a)));3 }4
5 function pairHash(uint _a, uint _b) internal pure returns(uint) {6 return hash(hash(_a) ^ hash(_b));7 }この関数は、ペアのハッシュを生成します。 これは、hashとpairHashのJavaScriptコードをSolidityに変換したものです。
**注:**これも読みやすさを優先して最適化された例です。 関数の定義 (opens in a new tab)に基づけば、データをbytes32 (opens in a new tab)値として保存し、変換を回避できる可能性があります。
1 // マークルプルーフを検証します2 function verifyProof(uint _value, uint[] calldata _proof)3 public view returns (bool) {4 uint temp = _value;5 uint i;6
7 for(i=0; i<_proof.length; i++) {8 temp = pairHash(temp, _proof[i]);9 }10
11 return temp == merkleRoot;12 }13
14} // MarkleProof数学的記法では、マークルプルーフの検証は次のようになります: H(proof_n, H(proof_n-1, H(proof_n-2, ... H(proof_1, H(proof_0, value))...)))。 これをこのコードで実装しています。
マークルプルーフとロールアップの相性
マークルプルーフはロールアップとうまく機能しません。 ロールアップでは、すべてのトランザクションデータはL1(レイヤー1)に書き込まれ、処理はL2(レイヤー2)で行われるためです。 マークルプルーフをトランザクションで送信するのにかかるコストは、1レイヤーあたり平均638ガスです(現在のコールデータ1バイトは、ゼロでなければ16ガス、ゼロであれば4ガスかかります)。 1024ワードのデータがある場合、マークルプルーフには10レイヤー、つまり合計で6380ガスが必要になります。
例えばOptimism (opens in a new tab)を見ると、L1への書き込みのガス代は約100 gwei、L2のガス代は0.001 gweiです(これは通常の価格で、混雑状況によって上昇する可能性があります)。 したがって、L1の1回分のガス代で、L2では10万ガスを処理に使えることになります。 ストレージを上書きしないと仮定すると、L1の1回のガス代でL2のストレージに約5ワード書き込めるということになります。 単一のマークルプルーフの場合、(トランザクションで提供されるのではなく、最初からオンチェーンで計算できると仮定して)1024ワードすべてをストレージに書き込んでも、まだガスのほとんどが残ります。
結論
実際に、マークルツリーを自身で実装することはないかもしれません。 よく知られている監査済みのライブラリを使用できるため、基本的には独自の暗号論的プリミティブを実装しないことをお勧めします。 しかし、マークルプルーフをよく理解し、使いどころを判断できるようになっていただければと思います。
マークルプルーフは_完全性_を維持しますが、_可用性_は維持しないことに注意してください。 データストレージにアクセスを拒否され、データストレージにアクセスするためのマークルツリーを構築することもできない場合でも、誰も自分の資産を奪うことはできないということを知っていると、ささやかな慰めとなります。 この特性により、マークルツリーは、IPFSなどの分散型ストレージで最もよく使用されています。
私の他の作品はこちらでご覧いただけます (opens in a new tab).
最終更新: 2026年3月3日


