Merkle-Beweise für Offline-Datenintegrität
Einführung
Idealerweise würden wir gerne alles im Ethereum-Speicher ablegen, der über Tausende von Computern verteilt ist und eine extrem hohe Verfügbarkeit (die Daten können nicht zensiert werden) sowie Integrität (die Daten können nicht unbefugt geändert werden) aufweist. Das Speichern eines 32-Byte-Wortes kostet jedoch typischerweise 20.000 Gas. Zum Zeitpunkt des Schreibens entspricht dieser Preis 6,60 $. Mit 21 Cent pro Byte ist dies für viele Anwendungsfälle zu teuer.
Um dieses Problem zu lösen, hat das Ethereum-Ökosystem viele alternative Wege entwickelt, um Daten dezentralisiert zu speichern. Meistens beinhalten diese einen Kompromiss zwischen Verfügbarkeit und Preis. Die Integrität ist jedoch in der Regel gewährleistet.
In diesem Artikel erfahren Sie, wie Sie die Datenintegrität sicherstellen können, ohne die Daten auf der Blockchain zu speichern, indem Sie Merkle-Beweise (opens in a new tab) verwenden.
Wie funktioniert das?
Theoretisch könnten wir einfach den Hash der Daten auf der Blockchain speichern und alle Daten in Transaktionen senden, die sie benötigen. Dies ist jedoch immer noch zu teuer. Ein Byte an Daten für eine Transaktion kostet etwa 16 Gas, derzeit etwa einen halben Cent oder etwa 5 $ pro Kilobyte. Mit 5.000 $ pro Megabyte ist dies für viele Anwendungen immer noch zu teuer, selbst ohne die zusätzlichen Kosten für das Hashen der Daten.
Die Lösung besteht darin, verschiedene Teilmengen der Daten wiederholt zu hashen, sodass Sie für die Daten, die Sie nicht senden müssen, einfach einen Hash senden können. Dies geschieht mithilfe eines Merkle-Baums, einer Baum-Datenstruktur, bei der jeder Knoten ein Hash der darunter liegenden Knoten ist:
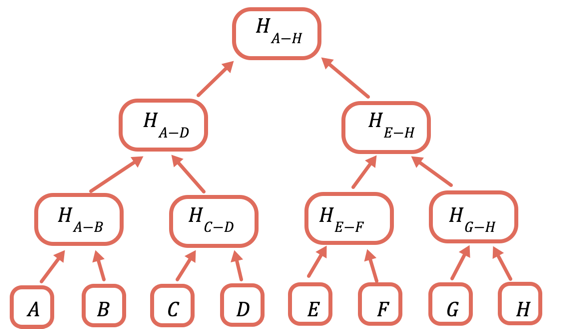
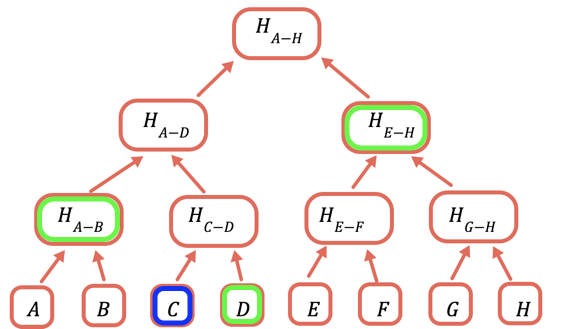
Der Wurzel-Hash ist der einzige Teil, der auf der Blockchain gespeichert werden muss. Um einen bestimmten Wert zu beweisen, stellen Sie alle Hashes bereit, die damit kombiniert werden müssen, um die Wurzel zu erhalten. Um beispielsweise C zu beweisen, stellen Sie D, H(A-B) und H(E-H) bereit.
Implementierung
Der Beispielcode wird hier bereitgestellt (opens in a new tab).
Off-Chain-Code
In diesem Artikel verwenden wir JavaScript für die Off-Chain-Berechnungen. Die meisten dezentralisierten Anwendungen haben ihre Off-Chain-Komponente in JavaScript.
Erstellen der Merkle-Wurzel
Zuerst müssen wir der Chain die Merkle-Wurzel bereitstellen.
1const ethers = require("ethers")Wir verwenden die Hash-Funktion aus dem ethers-Paket (opens in a new tab).
1// Die Rohdaten, deren Integrität wir überprüfen müssen. Die ersten zwei Bytes s2// ind eine Benutzerkennung, und die letzten zwei Bytes die Menge an Token, die der3// Benutzer derzeit besitzt.4const dataArray = [5 0x0bad0010, 0x60a70020, 0xbeef0030, 0xdead0040, 0xca110050, 0x0e660060,6 0xface0070, 0xbad00080, 0x060d0091,7]Das Codieren jedes Eintrags in eine einzelne 256-Bit-Ganzzahl führt zu weniger lesbarem Code als beispielsweise die Verwendung von JSON. Dies bedeutet jedoch deutlich weniger Verarbeitungsaufwand beim Abrufen der Daten im Smart Contract und somit viel geringere Gaskosten. Sie können JSON auf der Blockchain lesen (opens in a new tab), es ist nur eine schlechte Idee, wenn es sich vermeiden lässt.
1// Das Array der Hash-Werte, als BigInts2const hashArray = dataArrayIn diesem Fall bestehen unsere Daten von vornherein aus 256-Bit-Werten, sodass keine Verarbeitung erforderlich ist. Wenn wir eine kompliziertere Datenstruktur wie Strings verwenden, müssen wir sicherstellen, dass wir die Daten zuerst hashen, um ein Array von Hashes zu erhalten. Beachten Sie, dass dies auch daran liegt, dass es uns egal ist, ob Benutzer die Informationen anderer Benutzer kennen. Andernfalls hätten wir hashen müssen, damit Benutzer 1 den Wert für Benutzer 0 nicht kennt, Benutzer 2 den Wert für Benutzer 3 nicht kennt usw.
1// Konvertieren zwischen dem String, den die Hash-Funktion erwartet, und dem2// BigInt, den wir überall sonst verwenden.3const hash = (x) =>4 BigInt(ethers.utils.keccak256("0x" + x.toString(16).padStart(64, 0)))Die ethers-Hash-Funktion erwartet einen JavaScript-String mit einer hexadezimalen Zahl, wie z. B. 0x60A7, und antwortet mit einem weiteren String mit derselben Struktur. Für den Rest des Codes ist es jedoch einfacher, BigInt zu verwenden, daher konvertieren wir in einen hexadezimalen String und wieder zurück.
1// Symmetrischer Hash eines Paares, sodass es uns egal ist, ob die Reihenfolge umgekehrt wird.2const pairHash = (a, b) => hash(hash(a) ^ hash(b))Diese Funktion ist symmetrisch (Hash von a XOR (opens in a new tab) b). Das bedeutet, dass wir uns bei der Überprüfung des Merkle-Beweises keine Gedanken darüber machen müssen, ob wir den Wert aus dem Beweis vor oder nach dem berechneten Wert einfügen. Die Überprüfung des Merkle-Beweises erfolgt auf der Blockchain, je weniger wir dort also tun müssen, desto besser.
Warnung:
Kryptografie ist schwieriger, als sie aussieht.
Die ursprüngliche Version dieses Artikels enthielt die Hash-Funktion hash(a^b).
Das war eine schlechte Idee, denn das bedeutete, dass man, wenn man die legitimen Werte von a und b kannte, b' = a^b^a' verwenden konnte, um jeden gewünschten a'-Wert zu beweisen.
Mit dieser Funktion müssten Sie b' so berechnen, dass hash(a') ^ hash(b') gleich einem bekannten Wert ist (dem nächsten Zweig auf dem Weg zur Wurzel), was viel schwieriger ist.
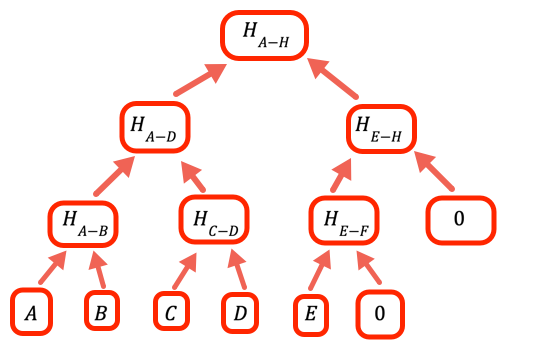
1// Der Wert, der anzeigt, dass ein bestimmter Zweig leer ist, hat keinen2// Wert3const empty = 0nWenn die Anzahl der Werte keine ganzzahlige Zweierpotenz ist, müssen wir leere Zweige behandeln. Dieses Programm macht das, indem es Null als Platzhalter einsetzt.
1// Berechne eine Ebene höher im Baum eines Hash-Arrays, indem der Hash von2// jedem Paar nacheinander gebildet wird3const oneLevelUp = (inputArray) => {4 var result = []5 var inp = [...inputArray] // Um ein Überschreiben der Eingabe zu vermeiden // Füge bei Bedarf einen leeren Wert hinzu (wir müssen alle Blätter // paaren)6
7 if (inp.length % 2 === 1) inp.push(empty)8
9 for (var i = 0; i < inp.length; i += 2)10 result.push(pairHash(inp[i], inp[i + 1]))11
12 return result13} // oneLevelUpDiese Funktion „klettert“ eine Ebene im Merkle-Baum nach oben, indem sie die Wertepaare auf der aktuellen Ebene hasht. Beachten Sie, dass dies nicht die effizienteste Implementierung ist. Wir hätten das Kopieren der Eingabe vermeiden und einfach hashEmpty an der entsprechenden Stelle in der Schleife hinzufügen können, aber dieser Code ist auf Lesbarkeit optimiert.
1const getMerkleRoot = (inputArray) => {2 var result3
4 result = [...inputArray] // Klettere den Baum hinauf, bis es nur noch einen Wert gibt, das ist die // Wurzel. // // Wenn eine Ebene eine ungerade Anzahl von Einträgen hat, fügt der // Code in oneLevelUp einen leeren Wert hinzu. Wenn wir also zum Beispiel // 10 Blätter haben, haben wir 5 Zweige in der zweiten Ebene, 3 // Zweige in der dritten, 2 in der vierten und die Wurzel ist die fünfte5
6 while (result.length > 1) result = oneLevelUp(result)7
8 return result[0]9}Um die Wurzel zu erhalten, klettern Sie so lange, bis nur noch ein Wert übrig ist.
Erstellen eines Merkle-Beweises
Ein Merkle-Beweis besteht aus den Werten, die zusammen mit dem zu beweisenden Wert gehasht werden müssen, um die Merkle-Wurzel zurückzuerhalten. Der zu beweisende Wert ist oft aus anderen Daten verfügbar, daher ziehe ich es vor, ihn separat und nicht als Teil des Codes bereitzustellen.
1// Ein Merkle-Beweis besteht aus dem Wert der Liste von Einträgen, mit denen2// gehasht wird. Da wir eine symmetrische Hash-Funktion verwenden, benötigen wir3// die Position des Elements nicht, um den Beweis zu verifizieren, sondern nur, um ihn zu erstellen4const getMerkleProof = (inputArray, n) => {5 var result = [], currentLayer = [...inputArray], currentN = n6
7 // Bis wir die Spitze erreichen8 while (currentLayer.length > 1) {9 // Keine Ebenen mit ungerader Länge10 if (currentLayer.length % 2)11 currentLayer.push(empty)12
13 result.push(currentN % 214 // Wenn currentN ungerade ist, füge es mit dem Wert davor zum Beweis hinzu15 ? currentLayer[currentN-1]16 // Wenn es gerade ist, füge den Wert danach hinzu17 : currentLayer[currentN+1])18
Wir hashen (v[0],v[1]), (v[2],v[3]) usw. Für gerade Werte benötigen wir also den nächsten, für ungerade Werte den vorherigen.
1 // Gehe zur nächsten Ebene nach oben2 currentN = Math.floor(currentN/2)3 currentLayer = oneLevelUp(currentLayer)4 } // while currentLayer.length > 15
6 return result7} // getMerkleProofOn-Chain-Code
Schließlich haben wir den Code, der den Beweis überprüft. Der On-Chain-Code ist in Solidity (opens in a new tab) geschrieben. Optimierung ist hier viel wichtiger, da Gas relativ teuer ist.
1// SPDX-License-Identifier: Public Domain2pragma solidity ^0.8.0;3
4import "hardhat/console.sol";Ich habe dies mit der Hardhat-Entwicklungsumgebung (opens in a new tab) geschrieben, die es uns ermöglicht, während der Entwicklung Konsolenausgaben von Solidity (opens in a new tab) zu erhalten.
1
2contract MerkleProof {3 uint merkleRoot;4
5 function getRoot() public view returns (uint) {6 return merkleRoot;7 }8
9 // Extrem unsicher, in Produktionscode muss der Zugriff auf10 // diese Funktion STRENG LIMITIERT SEIN, wahrscheinlich auf einen11 // Besitzer12 function setRoot(uint _merkleRoot) external {13 merkleRoot = _merkleRoot;14 } // setRootSet- und Get-Funktionen für die Merkle-Wurzel. Jeden die Merkle-Wurzel aktualisieren zu lassen, ist in einem Produktionssystem eine extrem schlechte Idee. Ich mache es hier der Einfachheit halber für den Beispielcode. Tun Sie dies nicht auf einem System, bei dem Datenintegrität tatsächlich wichtig ist.
1 function hash(uint _a) internal pure returns(uint) {2 return uint(keccak256(abi.encode(_a)));3 }4
5 function pairHash(uint _a, uint _b) internal pure returns(uint) {6 return hash(hash(_a) ^ hash(_b));7 }Diese Funktion generiert einen Paar-Hash. Es ist lediglich die Solidity-Übersetzung des JavaScript-Codes für hash und pairHash.
Hinweis: Dies ist ein weiterer Fall von Optimierung für die Lesbarkeit. Basierend auf der Funktionsdefinition (opens in a new tab) könnte es möglich sein, die Daten als bytes32 (opens in a new tab)-Wert zu speichern und die Konvertierungen zu vermeiden.
1 // Verifiziere einen Merkle-Beweis2 function verifyProof(uint _value, uint[] calldata _proof)3 public view returns (bool) {4 uint temp = _value;5 uint i;6
7 for(i=0; i<_proof.length; i++) {8 temp = pairHash(temp, _proof[i]);9 }10
11 return temp == merkleRoot;12 }13
14} // MarkleProofIn mathematischer Notation sieht die Verifizierung eines Merkle-Beweises so aus: H(proof_n, H(proof_n-1, H(proof_n-2, ... H(proof_1, H(proof_0, value))...))). Dieser Code implementiert dies.
Merkle-Beweise und Rollups passen nicht zusammen
Merkle-Beweise funktionieren nicht gut mit Rollups. Der Grund dafür ist, dass Rollups alle Transaktionsdaten auf L1 schreiben, aber auf L2 verarbeiten. Die Kosten für das Senden eines Merkle-Beweises mit einer Transaktion belaufen sich durchschnittlich auf 638 Gas pro Ebene (derzeit kostet ein Byte in Call-Daten 16 Gas, wenn es nicht null ist, und 4, wenn es null ist). Wenn wir 1024 Datenwörter haben, erfordert ein Merkle-Beweis zehn Ebenen oder insgesamt 6380 Gas.
Wenn wir uns zum Beispiel Optimism (opens in a new tab) ansehen, kostet das Schreiben von L1-Gas etwa 100 Gwei und L2-Gas kostet 0,001 Gwei (das ist der normale Preis, er kann bei Überlastung steigen). Für die Kosten von einem L1-Gas können wir also hunderttausend Gas für die L2-Verarbeitung ausgeben. Unter der Annahme, dass wir den Speicher nicht überschreiben, bedeutet dies, dass wir für den Preis von einem L1-Gas etwa fünf Wörter in den Speicher auf L2 schreiben können. Für einen einzigen Merkle-Beweis können wir die gesamten 1024 Wörter in den Speicher schreiben (vorausgesetzt, sie können von vornherein auf der Blockchain berechnet werden, anstatt in einer Transaktion bereitgestellt zu werden) und haben immer noch den Großteil des Gases übrig.
Fazit
Im wirklichen Leben werden Sie Merkle-Bäume vielleicht nie selbst implementieren. Es gibt bekannte und geprüfte Bibliotheken, die Sie verwenden können, und im Allgemeinen ist es am besten, kryptografische Primitive nicht selbst zu implementieren. Aber ich hoffe, dass Sie Merkle-Beweise jetzt besser verstehen und entscheiden können, wann sich ihr Einsatz lohnt.
Beachten Sie, dass Merkle-Beweise zwar die Integrität wahren, nicht aber die Verfügbarkeit. Zu wissen, dass niemand sonst Ihre Vermögenswerte nehmen kann, ist ein schwacher Trost, wenn der Datenspeicher beschließt, den Zugriff zu verweigern, und Sie auch keinen Merkle-Baum konstruieren können, um darauf zuzugreifen. Daher werden Merkle-Bäume am besten mit einer Art dezentralisiertem Speicher wie IPFS verwendet.
Weitere meiner Arbeiten finden Sie hier (opens in a new tab).
Letzte Aktualisierung der Seite: 3. März 2026


