Uthibitisho wa Merkle kwa uadilifu wa data nje ya mtandao
Utangulizi
Kimsingi tungependa kuhifadhi kila kitu katika ghala la Ethereum, ambalo huhifadhiwa kwenye maelfu ya kompyuta na lina upatikanaji wa juu sana (data haiwezi kudhibitiwa) na uadilifu (data haiwezi kurekebishwa kwa njia isiyoidhinishwa), lakini kuhifadhi neno la baiti 32 kwa kawaida hugharimu gesi 20,000. Ninapoandika hili, gharama hiyo ni sawa na $6.60. Kwa senti 21 kwa kila baiti hii ni ghali sana kwa matumizi mengi.
Ili kutatua tatizo hili, mfumo ikolojia wa Ethereum ulitengeneza njia nyingi mbadala za kuhifadhi data kwa njia ya ugatuzi . Kwa kawaida huhusisha maelewano kati ya upatikanaji na bei. Hata hivyo, uadilifu kwa kawaida huhakikishwa.
Katika makala hii utajifunza jinsi ya kuhakikisha uadilifu wa data bila kuhifadhi data kwenye mnyororo wa bloku, kwa kutumia uthibitisho wa Merkle (opens in a new tab).
Inafanyaje kazi?
Kimsingi tunaweza tu kuhifadhi hashi ya data onchain, na kutuma data yote katika miamala inayohitaji. Hata hivyo, hii bado ni ghali sana. Baiti moja ya data kwa muamala hugharimu takriban gesi 16, kwa sasa karibu nusu senti, au takriban $5 kwa kila kilobaiti. Kwa $5000 kwa kila megabaiti, hii bado ni ghali sana kwa matumizi mengi, hata bila gharama ya ziada ya kuweka hashi kwenye data.
Suluhisho ni kuweka hashi mara kwa mara seti ndogo tofauti za data, kwa hivyo kwa data ambayo huhitaji kutuma unaweza tu kutuma hashi. Unafanya hivi kwa kutumia mti wa Merkle, muundo wa data wa mti ambapo kila nodi ni hashi ya nodi zilizo chini yake:
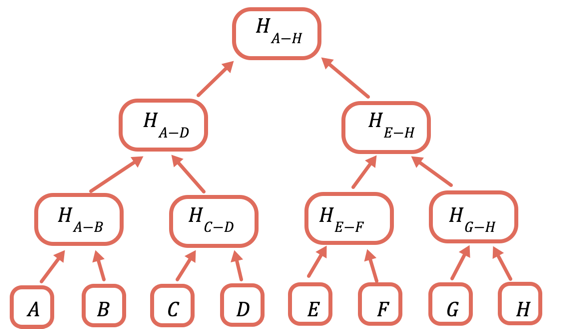
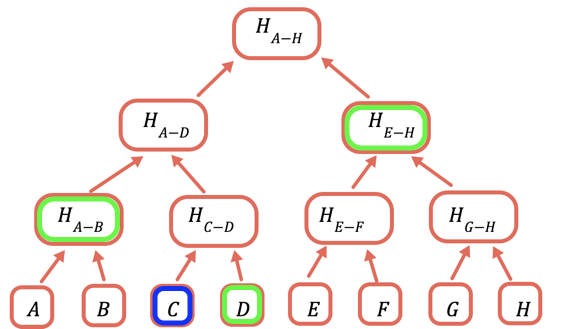
Hashi ya msingi ndiyo sehemu pekee inayohitaji kuhifadhiwa onchain. Ili kuthibitisha thamani fulani, unatoa hashi zote zinazohitaji kuunganishwa nayo ili kupata msingi. Kwa mfano, ili kuthibitisha C unatoa D, H(A-B), na H(E-H).
Utekelezaji
Msimbo wa sampuli umetolewa hapa (opens in a new tab).
Msimbo wa offchain
Katika makala hii tunatumia JavaScript kwa ajili ya hesabu za offchain. Mifumo mingi iliyotawanywa ina sehemu yake ya offchain katika JavaScript.
Kuunda mzizi wa Merkle
Kwanza tunahitaji kutoa mzizi wa Merkle kwa mnyororo.
1const ethers = require("ethers")Tunatumia chaguo la kukokotoa la hashi kutoka kwa kifurushi cha ethers (opens in a new tab).
1// Data ghafi ambayo uadilifu wake tunapaswa kuthibitisha. Baiti mbili za kwanza ni2// kitambulisho cha mtumiaji, na baiti mbili za mwisho ni kiasi cha tokeni ambazo3// mtumiaji anamiliki kwa sasa.4const dataArray = [5 0x0bad0010, 0x60a70020, 0xbeef0030, 0xdead0040, 0xca110050, 0x0e660060,6 0xface0070, 0xbad00080, 0x060d0091,7]Kusimba kila ingizo katika nambari kamili ya biti-256 husababisha msimbo usioweza kusomeka vizuri kuliko kutumia JSON, kwa mfano. Hata hivyo, hii ina maana ya uchakataji mdogo sana ili kupata data katika mkataba, kwa hiyo gharama za gesi ni za chini sana. Unaweza kusoma JSON onchain (opens in a new tab), ni wazo baya tu kama linaweza kuepukika.
1// Safu ya thamani za hashi, kama BigInts2const hashArray = dataArrayKatika kesi hii data yetu ni thamani za biti-256 kuanzia, kwa hivyo hakuna uchakataji unaohitajika. Ikiwa tutatumia muundo wa data mgumu zaidi, kama vile mifuatano, tunahitaji kuhakikisha tunaweka hashi data kwanza ili kupata safu ya hashi. Kumbuka kuwa hii pia ni kwa sababu hatujali ikiwa watumiaji wanajua habari za watumiaji wengine. Vinginevyo tungehitaji kuweka hashi ili mtumiaji 1 asijue thamani ya mtumiaji 0, mtumiaji 2 asijue thamani ya mtumiaji 3, n.k.
1// Badilisha kati ya mfuatano ambao chaguo la kukokotoa la hashi linatarajia na2// BigInt tunayotumia kila mahali pengine.3const hash = (x) =>4 BigInt(ethers.utils.keccak256("0x" + x.toString(16).padStart(64, 0)))Chaguo la kukokotoa la hashi ya ethers linatarajia kupata mfuatano wa JavaScript na nambari ya heksadesimali, kama vile 0x60A7, na hujibu kwa mfuatano mwingine wenye muundo sawa. Hata hivyo, kwa msimbo uliobaki ni rahisi kutumia BigInt, kwa hivyo tunabadilisha kuwa mfuatano wa heksadesimali na kurudi tena.
1// Hashi linganifu ya jozi ili tusijali ikiwa mpangilio umegeuzwa.2const pairHash = (a, b) => hash(hash(a) ^ hash(b))Chaguo hili la kukokotoa ni linganifu (hashi ya a xor (opens in a new tab) b). Hii ina maana kwamba tunapoangalia uthibitisho wa Merkle hatuhitaji kuwa na wasiwasi kuhusu ikiwa tutaweka thamani kutoka kwa uthibitisho kabla au baada ya thamani iliyokokotolewa. Uthibitishaji wa Merkle unafanywa onchain, kwa hivyo kadri tunavyohitaji kufanya kidogo ndivyo inavyokuwa bora zaidi.
Onyo:
Kroptografia ni ngumu kuliko inavyoonekana.
Toleo la awali la makala hii lilikuwa na chaguo la kukokotoa la hashi hash(a^b).
Hilo lilikuwa wazo baya kwa sababu lilimaanisha kwamba kama ungejua thamani halali za a na b ungeweza kutumia b' = a^b^a' kuthibitisha thamani yoyote ya a' unayotaka.
Ukiwa na chaguo hili la kukokotoa ingekubidi ukokotee b' kiasi kwamba hash(a') ^ hash(b') ni sawa na thamani inayojulikana (tawi linalofuata kwenye njia ya kuelekea kwenye mzizi), ambayo ni ngumu zaidi.
1// Thamani ya kuashiria kuwa tawi fulani ni tupu, halina2// thamani3const empty = 0nWakati idadi ya thamani si kielelezo kamili cha mbili tunahitaji kushughulikia matawi tupu. Njia ambayo programu hii hufanya ni kuweka sifuri kama kishika nafasi.
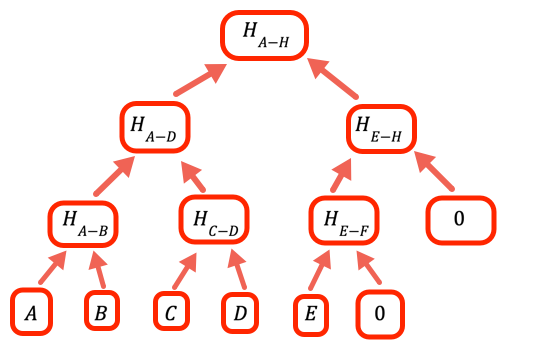
1// Kokotoa ngazi moja juu ya mti wa safu ya hashi kwa kuchukua hashi ya2// kila jozi kwa mfuatano3const oneLevelUp = (inputArray) => {4 var result = []5 var inp = [...inputArray] // Ili kuepuka kuandika upya ingizo // Ongeza thamani tupu ikiwa ni lazima (tunahitaji majani yote yawe // yameunganishwa kwa jozi)67 if (inp.length % 2 === 1) inp.push(empty)89 for (var i = 0; i < inp.length; i += 2)10 result.push(pairHash(inp[i], inp[i + 1]))1112 return result13} // oneLevelUpOnyesha yoteChaguo hili la kukokotoa "hupanda" ngazi moja katika mti wa Merkle kwa kuweka hashi jozi za thamani kwenye safu ya sasa. Kumbuka kuwa huu si utekelezaji bora zaidi, tungeweza kuepuka kunakili ingizo na kuongeza tu hashEmpty inapofaa katika kitanzi, lakini msimbo huu umeboreshwa kwa ajili ya usomaji.
1const getMerkleRoot = (inputArray) => {2 var result34 result = [...inputArray] // Panda juu ya mti hadi kuwe na thamani moja tu, huo ndio // mzizi. // // Ikiwa safu ina idadi isiyo ya kawaida ya maingizo // msimbo katika oneLevelUp unaongeza thamani tupu, kwa hivyo ikiwa tuna, kwa mfano, // majani 10 tutakuwa na matawi 5 katika safu ya pili, 3 // matawi katika ya tatu, 2 katika ya nne na mzizi ni wa tano56 while (result.length > 1) result = oneLevelUp(result)78 return result[0]9}Onyesha yoteIli kupata mzizi, panda hadi kubaki thamani moja tu.
Kuunda uthibitisho wa Merkle
Uthibitisho wa Merkle ni thamani za kuweka hashi pamoja na thamani inayothibitishwa ili kurudisha mzizi wa Merkle. Thamani ya kuthibitisha mara nyingi hupatikana kutoka kwa data nyingine, kwa hivyo napendelea kuitoa kando badala ya kuwa sehemu ya msimbo.
1// Uthibitisho wa merkle unajumuisha thamani ya orodha ya maingizo ya2// kuwekea hashi. Kwa sababu tunatumia chaguo la kukokotoa la hashi linganifu, hatuhitaji3// eneo la kipengee ili kuthibitisha uthibitisho, bali kuunda tu4const getMerkleProof = (inputArray, n) => {5 var result = [], currentLayer = [...inputArray], currentN = n67 // Hadi tufike juu8 while (currentLayer.length > 1) {9 // Hakuna safu za urefu usio wa kawaida10 if (currentLayer.length % 2)11 currentLayer.push(empty)1213 result.push(currentN % 214 // Ikiwa currentN si shufwa, ongeza na thamani iliyo kabla yake kwenye uthibitisho15 ? currentLayer[currentN-1]16 // Ikiwa ni shufwa, ongeza thamani baada yake17 : currentLayer[currentN+1])18Onyesha yoteTunaweka hashi (v[0],v[1]), (v[2],v[3]), n.k. Kwa hivyo kwa thamani shufwa tunahitaji inayofuata, kwa thamani witiri tunahitaji iliyotangulia.
1 // Sogeza hadi safu inayofuata juu2 currentN = Math.floor(currentN/2)3 currentLayer = oneLevelUp(currentLayer)4 } // while currentLayer.length > 156 return result7} // getMerkleProofMsimbo wa onchain
Mwishowe tuna msimbo unaoangalia uthibitisho. Msimbo wa onchain umeandikwa katika Solidity (opens in a new tab). Uboreshaji ni muhimu zaidi hapa kwa sababu gesi ni ghali kiasi.
1//SPDX-License-Identifier: Public Domain2pragma solidity ^0.8.0;34import "hardhat/console.sol";Niliandika hii kwa kutumia mazingira ya uundaji ya Hardhat (opens in a new tab), ambayo inaturuhusu kuwa na tokeo la konsoli kutoka Solidity (opens in a new tab) tunapounda.
12contract MerkleProof {3 uint merkleRoot;45 function getRoot() public view returns (uint) {6 return merkleRoot;7 }89 // Si salama kabisa, katika ufikiaji wa msimbo wa uzalishaji10 // chaguo hili la kukokotoa LAZIMA liwe na kikomo kikali, pengine kwa11 // mmiliki12 function setRoot(uint _merkleRoot) external {13 merkleRoot = _merkleRoot;14 } // setRootOnyesha yoteChaguo za kukokotoa za kuweka na kupata za mzizi wa Merkle. Kumruhusu kila mtu kusasisha mzizi wa Merkle ni wazo baya sana katika mfumo wa uzalishaji. Ninafanya hivi hapa kwa ajili ya kurahisisha msimbo wa sampuli. Usifanye hivyo kwenye mfumo ambapo uadilifu wa data ni muhimu.
1 function hash(uint _a) internal pure returns(uint) {2 return uint(keccak256(abi.encode(_a)));3 }45 function pairHash(uint _a, uint _b) internal pure returns(uint) {6 return hash(hash(_a) ^ hash(_b));7 }Chaguo hili la kukokotoa hutengeneza hashi ya jozi. Ni tafsiri ya Solidity tu ya msimbo wa JavaScript wa hash na pairHash.
Kumbuka: Hii ni kesi nyingine ya uboreshaji kwa ajili ya usomaji. Kulingana na ufafanuzi wa chaguo la kukokotoa (opens in a new tab), inaweza kuwezekana kuhifadhi data kama thamani ya bytes32 (opens in a new tab) na kuepuka ubadilishaji.
1 // Thibitisha uthibitisho wa Merkle2 function verifyProof(uint _value, uint[] calldata _proof)3 public view returns (bool) {4 uint temp = _value;5 uint i;67 for(i=0; i<_proof.length; i++) {8 temp = pairHash(temp, _proof[i]);9 }1011 return temp == merkleRoot;12 }1314} // MarkleProofOnyesha yoteKatika nukuu za kihisabati uthibitishaji wa Merkle unaonekana kama hivi: H(proof_n, H(proof_n-1, H(proof_n-2, ... H(proof_1, H(proof_0, value))...)))`. Msimbo huu unautekeleza.
Uthibitisho wa Merkle na unda-mpya havichanganyiki
Uthibitisho wa Merkle haufanyi kazi vizuri na unda-mpya. Sababu ni kwamba unda-mpya huandika data yote ya muamala kwenye L1, lakini huchakata kwenye L2. Gharama ya kutuma uthibitisho wa Merkle na muamala ni wastani wa gesi 638 kwa kila safu (kwa sasa baiti katika data ya wito hugharimu gesi 16 ikiwa si sifuri, na 4 ikiwa ni sifuri). Ikiwa tuna maneno 1024 ya data, uthibitisho wa Merkle unahitaji safu kumi, au jumla ya gesi 6380.
Tukiangalia kwa mfano Optimism (opens in a new tab), kuandika gesi ya L1 hugharimu takriban gwei 100 na gesi ya L2 hugharimu gwei 0.001 (hiyo ndiyo bei ya kawaida, inaweza kupanda kukiwa na msongamano). Kwa hivyo kwa gharama ya gesi moja ya L1 tunaweza kutumia gesi laki moja kwenye uchakataji wa L2. Tukichukulia kuwa hatuandiki upya kwenye ghala, hii ina maana kwamba tunaweza kuandika takriban maneno matano kwenye ghala kwenye L2 kwa bei ya gesi moja ya L1. Kwa uthibitisho mmoja wa Merkle tunaweza kuandika maneno yote 1024 kwenye ghala (tukichukulia kuwa yanaweza kukokotolewa onchain kuanzia, badala ya kutolewa katika muamala) na bado kubaki na gesi nyingi.
Hitimisho
Katika maisha halisi unaweza usiwahi kutekeleza miti ya Merkle peke yako. Kuna maktaba zinazojulikana na zilizokaguliwa ambazo unaweza kutumia na kwa ujumla ni bora kutotekeleza vianzo vya kroptografia peke yako. Lakini natumai sasa unaelewa uthibitisho wa Merkle vizuri zaidi na unaweza kuamua wakati unafaa kutumia.
Kumbuka kwamba ingawa uthibitisho wa Merkle huhifadhi uadilifu, hauhifadhi upatikanaji. Kujua kwamba hakuna mtu mwingine anayeweza kuchukua mali zako ni faraja ndogo ikiwa hifadhi ya data itaamua kutoruhusu ufikiaji na huwezi kuunda mti wa Merkle ili kuzifikia pia. Kwa hivyo miti ya Merkle hutumiwa vyema zaidi na aina fulani ya hifadhi iliyogatuliwa, kama vile IPFS.
Tazama hapa kwa kazi zangu zaidi (opens in a new tab).
Ukurasa ulihaririwa mwisho: 18 Desemba 2025


